pacman::p_load(
rio, # импорт/экспорт
here, # расположение файла
purrr, # итерации
grates, # шкалы в ggplot
tidyverse # управление данными и визуализация
)16 Итерации, циклы и списки
Эпидемиологи часто сталкиваются с ситуациями, когда необходимо повторять анализ по подгруппам, например, по странам, районам или возрастным группам. Это лишь некоторые примеры ситуаций, когда требуются итерации. Кодирование ваших повторяющихся операций с помощью подходов, указанных ниже, позволит вам выполнять такие повторяющиеся задачи быстрее, снижать риск ошибок и сокращать длину кода.
На этой странице мы представим два подхода к повторяющимся операциям - использование циклов на основе for и использование пакета purrr.
-
Циклы for повторяют код для ряда входных данных, но менее часто встречаются в R, чем в других языках программирования. Тем не менее, мы вас с ними познакомим в целях изучения инструмента и для справки.
- Пакет purrr является подходом к итеративным операциям из tidyverse - он работает путем “сопоставления” функции с разными входными данными (значения, столбцы, наборы данных и т.п.)
В ходе изучения мы покажем следующие примеры:
- Импорт и экспорт нескольких файлов
- Создание эпидкривых для нескольких юрисдикций
- Проведение T-тестов для нескольких столбцов датафрейма
В разделе purrr мы также дадим несколько примеров создания и работы с объектами lists.
16.1 Подготовка
Загрузка пакетов
Данный фрагмент кода показывает загрузку пакетов, необходимых для анализа. В данном руководстве мы фокусируемся на использовании p_load() из пакета pacman, которая устанавливает пакет, если необходимо, и загружает его для использования. Вы можете также загрузить установленные пакеты с помощью library() из базового R. См. страницу [Основы R] для получения дополнительной информации о пакетах R.
Импорт данных
Мы импортируем набор данных о случаях имитированной эпидемии Эболы. Если вы хотите выполнять действия параллельно, кликните, чтобы скачать “чистый” построчный список (как .rds файл). Импортируйте данный с помощью функции import() из пакета rio (он работает с многими типами файлов, такими как .xlsx, .csv, .rds - см. детали на странице [Импорт и экспорт]).
# импортируем построчный список
linelist <- import("linelist_cleaned.rds")Первые 50 строк построчного списка отображены ниже.
16.2 Циклы for
Циклы for в R
Циклы for не очень часто применяются в R, но часто встречаются в других языках программирования. Вам, как начинающему, они могут быть полезны для изучения и практики, поскольку их легче изучать, проводить дебаггинг и разобраться, что происходит при каждой итерации, особенно если вы еще не умеете писать собственные функции.
Вы можете быстро перейти от циклов for к итерации с помощью построенных функций в purrr (см. раздел ниже).
Ключевые компоненты
В цикле for есть три ключевых части:
-
Последовательность элементов, по которым проводится итерация
-
Операции, которые проводятся для каждого элемента последовательности
- Контейнер для результатов (опционально)
Базовый синтаксис выглядит следующим образом: for (элемент в последовательности) {сделать операции с элементом}. Обратите внимание, что есть скобки и фигурные скобки. Результаты можно вывести на консоль, либо сохранить в контейнере объекта R.
Простой пример цикла for представлен ниже.
for (num in c(1,2,3,4,5)) { # определяем ПОСЛЕДОВАТЕЛЬНОСТЬ (числа с 1 по 5) и цикл открывается с помощью "{"
print(num + 2) # ОПЕРАЦИИ (добавить два к каждому числу последовательности и вывести на печать)
} # закрываем цикл с помощью "}" [1] 3
[1] 4
[1] 5
[1] 6
[1] 7 # В данном примере нет "контейнера"Последовательность
Это элемент “for” (для) в цикле for - операции будут проводиться “для” каждого элемента в последовательности. Последовательность может быть рядом значений (например, имен юрисдикций, болезней, имен столбцов, элементов списка и т.п.), либо она может быть рядом последовательно идущих чисел (например, 1,2,3,4,5). Каждый из подходов имеет свое применение, что описано ниже.
Базовая структура утверждения в последовательности - item in vector (элемент в векторе).
- Вы можете записать любой знак или слово вместо “item”(“элемента”) (например, “i”, “num”, “hosp”, “district”, и т.п.). Значение этого “элемента” меняется при каждой итерации цикла, проходя по каждому значению в векторе.
- Вектор может быть текстовыми значениями, именами столбцов, либо последовательностью чисел - это значения, которые будут меняться при каждой итерации. Вы можете их использовать внутри операций цикла for, через термин “item” (элемент).
Пример: последовательность текстовых значений
В данном примере цикл выполняется для каждого значения в заранее установленном текстовом векторе имен больниц.
# создаем вектор имен больниц
hospital_names <- unique(linelist$hospital)
hospital_names # печать[1] "Other"
[2] "Missing"
[3] "St. Mark's Maternity Hospital (SMMH)"
[4] "Port Hospital"
[5] "Military Hospital"
[6] "Central Hospital" Мы выбрали термин hosp для отражения значений из вектора hospital_names. Для первой итерации цикла, значением hosp будет hospital_names[[1]]. Во втором цикле это будет hospital_names[[2]]. И так далее…
# 'цикл for' с текстовой последовательностью
for (hosp in hospital_names){ # последовательность
# ЗДЕСЬ ОПЕРАЦИИ
}Пример: последовательность имен столбцов
Это вариация текстовой последовательности, приведенной выше, в которой имена существующего объекта R извлекаются и становятся вектором. Например, имена столбцов в датафрейме. Что удобно, в коде операций циклов for, имена столбцов могут быть использованы для индексирования (подмножества) оригинального датафрейма
Ниже последовательностью являются names() (имена столбцов) датафрейма linelist. Название нашего “элемента” - col, что отражает каждое название столбца по мере проведения циклов.
Для примера мы включаем код операций внутри цикла for, который проводится для каждого значения в последовательности. В этом коде значения последовательности (имена столбцов) используются для индексирования (подмножества) linelist, по одному. Как рассказано на странице [Основы R], двойные квадратные скобки используются для подмножества [[ ]]. Полученный в результате столбец передается в is.na(), затем в sum() для получения количества отсутствующих значений в столбце. Результат печатается в консоли - одно число для каждого столбца.
Примечание по индексированию с помощью имен столбцов - когда вы ссылаетесь на сам столбец, не пишите просто “col”! col отражает только текстовое имя столбца! Чтобы сослаться на весь столбец, вы должны использовать имя столбца как индекс в linelist с помощью linelist[[col]].
for (col in names(linelist)){ # цикл выполняется для каждого столбца в построчном списке; имя столбца представлено как "col"
# Пример кода операций - печать количества отсутствующих значений в столбце
print(sum(is.na(linelist[[col]]))) # построчный список индексируется текущим значением "col"
}[1] 0
[1] 0
[1] 2087
[1] 256
[1] 0
[1] 936
[1] 1323
[1] 278
[1] 86
[1] 0
[1] 86
[1] 86
[1] 86
[1] 0
[1] 0
[1] 0
[1] 2088
[1] 2088
[1] 0
[1] 0
[1] 0
[1] 249
[1] 249
[1] 249
[1] 249
[1] 249
[1] 149
[1] 765
[1] 0
[1] 256Последовательность чисел
В данном подходе последовательность - ряд последовательно расположенных чисел. Таким образом, значение “элемента” - то не текстовое значение (например, “Central Hospital” или “date_onset”), а число. Это полезно для того, чтобы выполнить циклы для датафреймов, поскольку можно использовать номер “элемента” внутри цикла for, чтобы индексировать датафрейм по номеру строки.
Например, представим, что вы хотите выполнить цикл для каждой строки в вашем датафрейме и извлечь определенную информацию. Вашими “элементами” будут числовые номера строк. Часто в этом случае элементы (“items”) записывают как i.
Процесс циклов for можно объяснить словами следующим образом: “для каждого элемента последовательности чисел от 1 до общего количества строк в моем датафрейме, выполнить X”. Для первой итерации цикла значеним элемента (“item”) i будет 1. Для второй - i будет 2 и т.п.
Вот так выглядит последовательность в виде кода: for (i в 1:nrow(linelist)) {КОД ОПЕРАЦИЙ} где i отражает “item” (элемент), а 1:nrow(linelist) создает последовательность последовательно идущих чисел от 1 до количества строк в linelist.
for (i in 1:nrow(linelist)) { # применяем к датафрейму
# ЗДЕСЬ ОПЕРАЦИИ
} Если вы хотите, чтобы последовательность была числами, но вы начинаете с вектора (а не датафрейма), используйте seq_along(), чтобы выдать последовательность чисел для каждого элемента вектора. Например, for (i in seq_along(hospital_names) {КОД ОПЕРАЦИЙ}.
Приведенный ниже код выдает числа, которые станут значением i в своем соответствующем цикле.
seq_along(hospital_names) # используем для именованного вектора[1] 1 2 3 4 5 6Преимуществом использования чисел в последовательности является то, что легко использовать число i для индексации контейнера, который хранит выходные результаты цикла. Пример представлен в разделе Операции ниже.
Операции
Этот код записан внутри фигурных скобок { } в цикле for. Вам нужно, чтобы этот код выполнялся для каждого “элемента” в последовательности. Следовательно, будьте внимательны, чтобы каждая часть вашего кода, которая меняет “элемент”, была правильно закодирована таким образом, чтобы он действительно изменился! Например, помните, что для индексирования нужно использовать [[ ]].
В примере ниже мы проводим итерацию для каждой строки в linelist. Значения пола (gender) и возраста (age) каждой строки вставляются вместе и хранятся в векторе-контейнере cases_demographics. Обратите внимание, как мы также используем индексирование [[i]], чтобы сохранить выходные результаты цикла в правильной позиции в векторе “контейнере”.
# создаем контейнер для хранения результатов - текстовый вектор
cases_demographics <- vector(mode = "character", length = nrow(linelist))
# цикл for
for (i in 1:nrow(linelist)){
# ОПЕРАЦИИ
# извлекаем значения из построчного списка для строки i, используя квадратные скобки для индексирования
row_gender <- linelist$gender[[i]]
row_age <- linelist$age_years[[i]] # не забудьте индексировать!
# объединяем пол-возраст и храним в векторе-контейнере в указанной индексом локации
cases_demographics[[i]] <- str_c(row_gender, row_age, sep = ",")
} # окончание цикла
# отображаем первые 10 строк контейнера
head(cases_demographics, 10) [1] "m,2" "f,3" "m,56" "f,18" "m,3" "f,16" "f,16" "f,0" "m,61" "f,27"Контейнер
Иногда результаты циклов for будут печататься в консоли или на панели RStudio Plots (Графики). А иногда вам нужно будет сохранить выходные данные в “контейнере” для использования позже. Такой контейнер может быть вектором, датафреймом или даже списком.
Наиболее эффективным способом является создание контейнера для результатов еще до начала цикла for. На практике это означает, что необходимо создать пустой вектор, датафрейм или список. Их можно создать с помощью функции vector() для векторов или списков, либо с помощью matrix() и data.frame() для датафрейма.
Пустой вектор
Используйте vector() и уточните mode = на основе ожидаемого класса объектов, которые вы вставите, либо “double” (двойной точности - для чисел), “character” (текстовый), или “logical” (логический). Вам также нужно заранее задать длину length =. Это должна быть длина вашей последовательности циклов for.
Допустим, вы хотите сохранить медианную задержку госпитализации для каждой больницы. Вы можете использовать “double” (число двойной точности) и установить длину на количество ожидаемых выходных данных (количество уникальных больниц в наборе данных).
delays <- vector(
mode = "double", # мы ожидаем, что нужно сохранить числа
length = length(unique(linelist$hospital))) # число уникальных больниц в наборе данныхПустой датафрейм
Вы можете создать пустой датафрейм, указав количество строк и столбцов следующим образом:
delays <- data.frame(matrix(ncol = 2, nrow = 3))Пустой список
Вы можете также сохранить некоторые графики, созданные циклом for, в виде списка. Список похож на вектор, но содержит другие объекты R внутри себя, которые могут быть разных классов. Элементы в списке могут быть отдельным числом, датафреймом, вектором или даже еще одним списком.
Вы создаете пустой список, используя ту же команду vector(), что указана выше, но с аргументом mode = "list". Уточните любую желаемую длину.
plots <- vector(mode = "list", length = 16)Печать
Обратите внимание, что для печати изнутри цикла for вам скорее всего нужно будет дополнительно обернуть с помощью функции print().
В примере ниже последовательность является текстовым вектором, который используется для создания подмножества из построчного списка по больницам. Результаты не сохраняются в контейнере, а печатаются в консоли с помощью функции print().
for (hosp in hospital_names){
hospital_cases <- linelist %>% filter(hospital == hosp)
print(nrow(hospital_cases))
}[1] 885
[1] 1469
[1] 422
[1] 1762
[1] 896
[1] 454Тестирование цикла for
Чтобы протестировать ваш цикл, вы можете выполнить команду для временного присваивания “элемента”, например, i <- 10 или hosp <- "Central Hospital". Сделайте это за пределами цикла и затем выполните только ваш код операций (код внутри фигурных скобок), чтобы посмотреть, будут ли созданы ожидаемые результаты.
Циклы для графиков
Чтобы объединить все три компонента (контейнер, последовательность и операции), давайте попробуем построить эпидкривую для каждой больницу (см. страницу [Эпидемические кривые]).
Мы можем создать красивую эпидемическую кривую всех случаев по полу, используя пакет incidence2, как показано ниже:
# создаем объект 'incidence' (заболеваемость)
outbreak <- incidence2::incidence(
x = linelist, # датафрейм - полный построчный список
date_index = "date_onset", # столбец дата
interval = "week", # суммарный подсчет по неделе
groups = "gender") # группируем значения по полу
#na_as_group = TRUE) # отсутствующий пол в отдельную группу
# строим эпидемическую кривую
ggplot(outbreak, # имя объекта заболеваемости
aes(x = date_index, #эстетика и оси
y = count,
fill = gender), # цвет заливки столбцов по полу
color = "black" # контур столбцов
) +
geom_col() +
facet_wrap(~gender) +
theme_bw() +
labs(title = "Outbreak of all cases", #подписи
x = "Counts",
y = "Date",
fill = "Gender",
color = "Gender")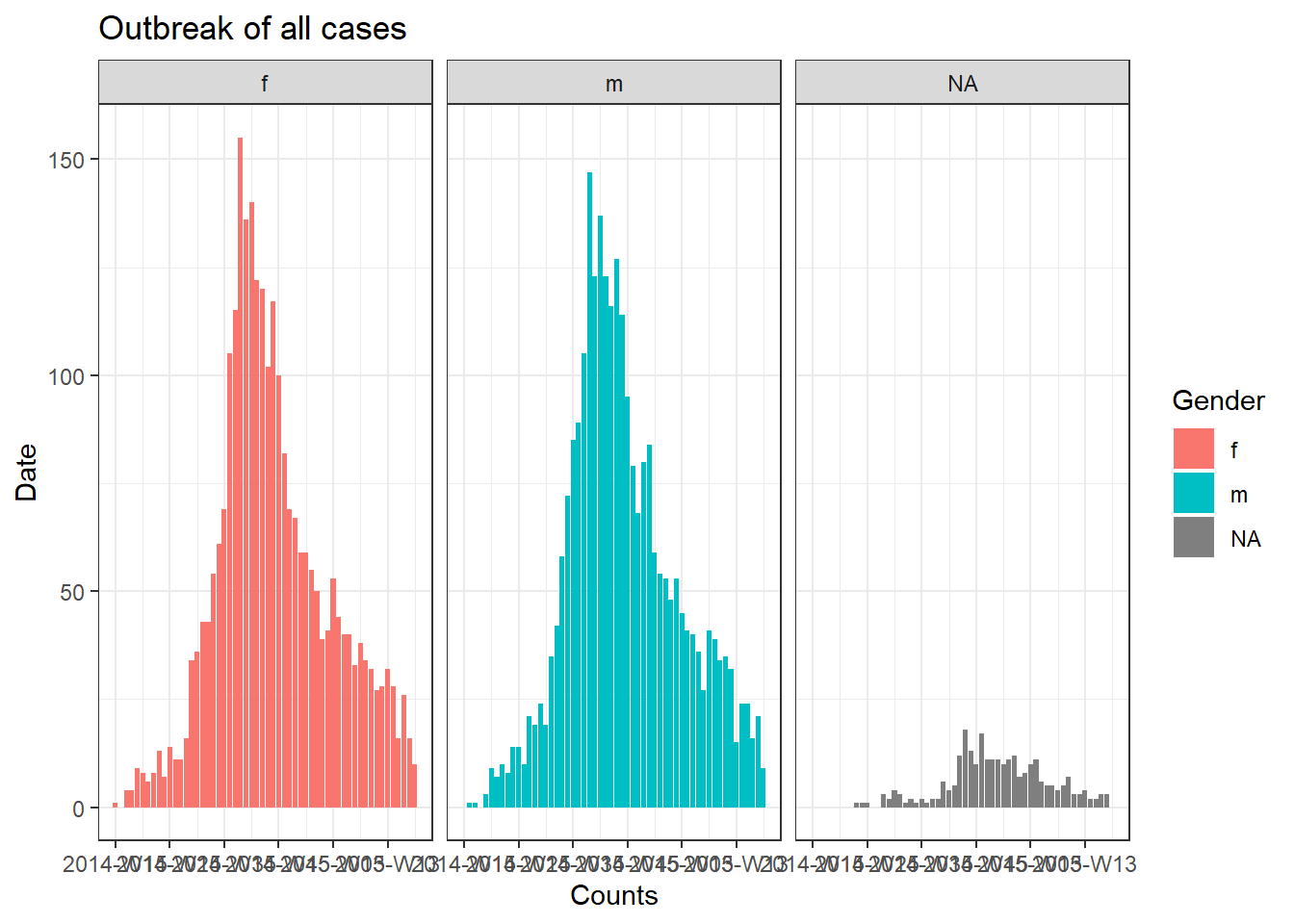
Чтобы создать отдельный график для случаев по каждой больнице, мы можем код эпидкривой заложить в цикл for.
Сначала мы сохраняем именованный вектор уникальных имен больниц, hospital_names. Цикл for будет выполнен один раз для каждого из этих имен: for (hosp in hospital_names). В каждой итерации цикла for, текущее имя больницы из вектора будет представлено как hosp для использования внутри цикла.
Внутри операций цикла вы можете писать код R как обычно, но используйте “элемент” (в данном случае hosp), зная, что его значение будет меняться. Внутри этого цикла:
- Применяется
filter()к построчному спискуlinelist, так чтобы столбецhospitalбыл равен текущему значениюhosp
- Создается объект incidence (заболеваемость) в отфильтрованном построчном списке
- Создается график для текущей больницы с автоматически изменяемым заголовком, который использует
hosp
- График для текущей больницы временно сохраняется и затем печатается
- Затем цикл переходит дальше и повторяет процесс со следующей больницей в
hospital_names
# создаем вектор имен больниц
hospital_names <- unique(linelist$hospital)
# для каждого имени ("hosp") в hospital_names, создаем и печатаем эпидкривую
for (hosp in hospital_names) {
# создаем объект incidence (заболеваемость) конкретно для текущей больницы
outbreak_hosp <- incidence2::incidence(
x = linelist %>% filter(hospital == hosp), # построчный список фильтруется до текущей больницы
date_index = "date_onset",
interval = "week",
groups = "gender"#,
#na_as_group = TRUE
)
plot_hosp <- ggplot(outbreak_hosp, # имя объекта incidence
aes(x = date_index, #axes
y = count,
fill = gender), # цвет заливки по полу
color = "black" # цвет контура столбца
) +
geom_col() +
facet_wrap(~gender) +
theme_bw() +
labs(title = stringr::str_glue("Epidemic of cases admitted to {hosp}"), #заголовок
x = "Counts",
y = "Date",
fill = "Gender",
color = "Gender")
# В более старых версиях R удалите # перед na_as_group и используйте вместо этого эту команду для графика
# plot_hosp <- plot(
# outbreak_hosp,
# fill = "gender",
# color = "black",
# title = stringr::str_glue("Epidemic of cases admitted to {hosp}")
# )
#печать графика больниц
print(plot_hosp)
} # цикл for заканчивается. когда он пройдет по каждой больнице hospital_names 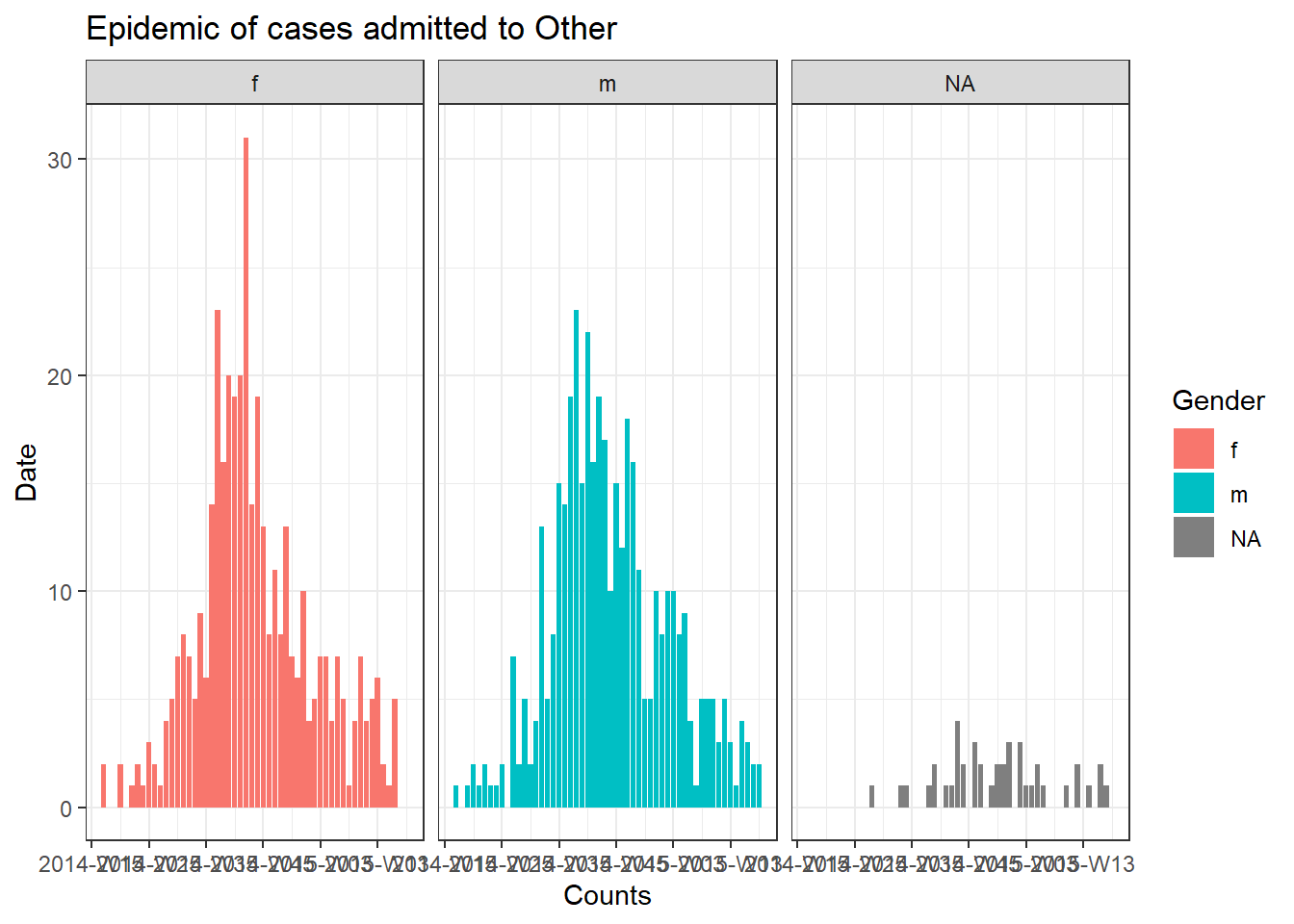
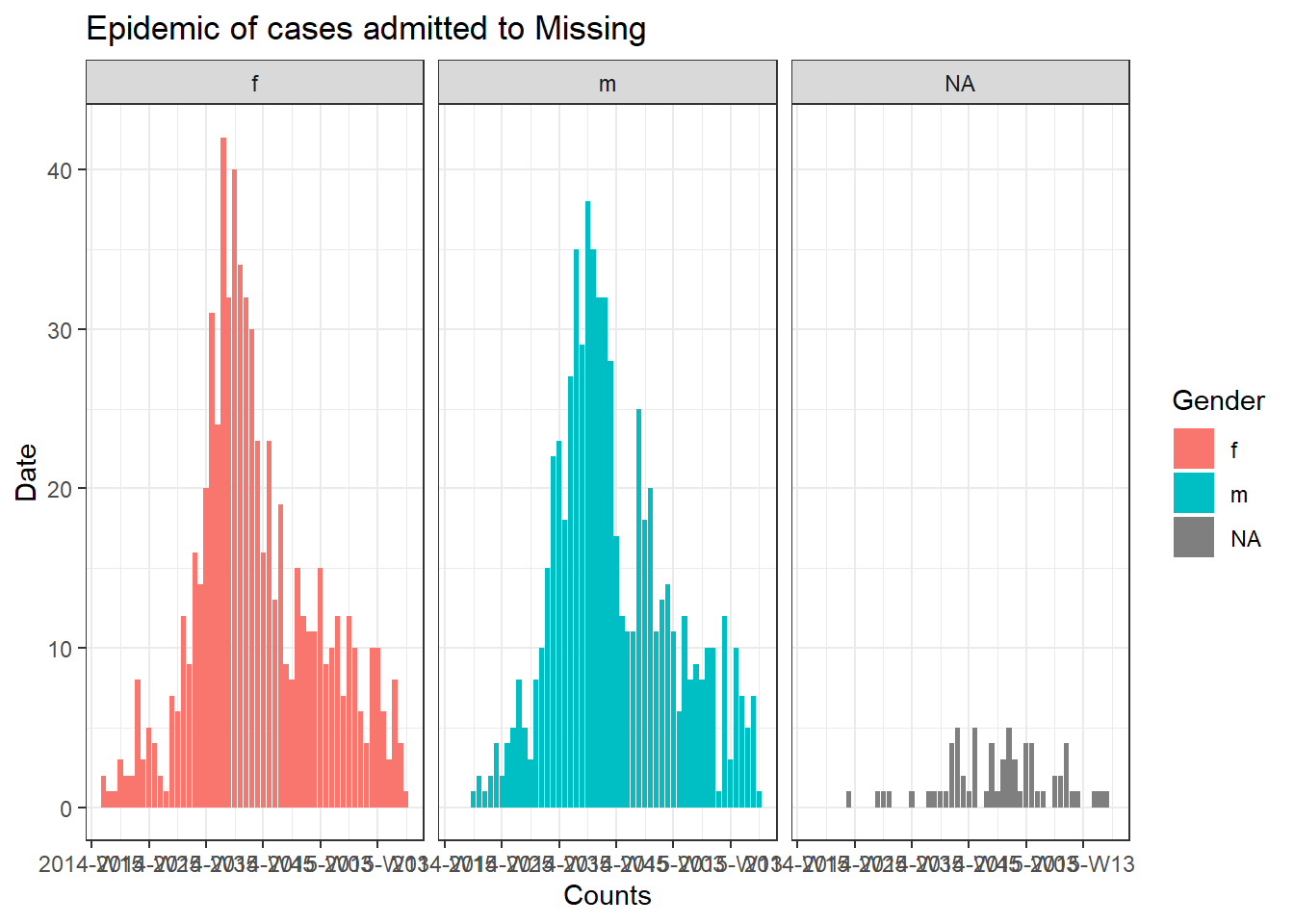
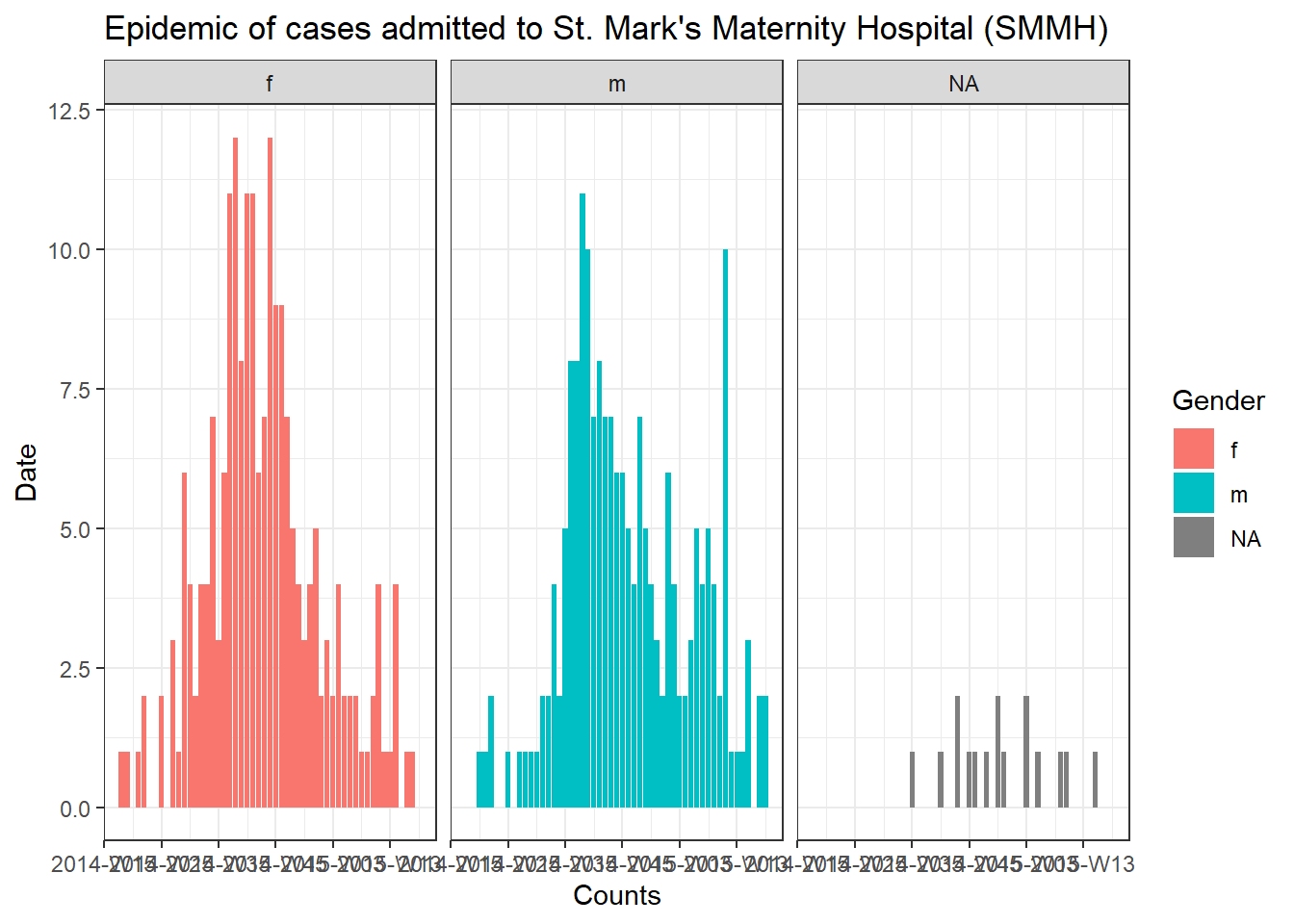
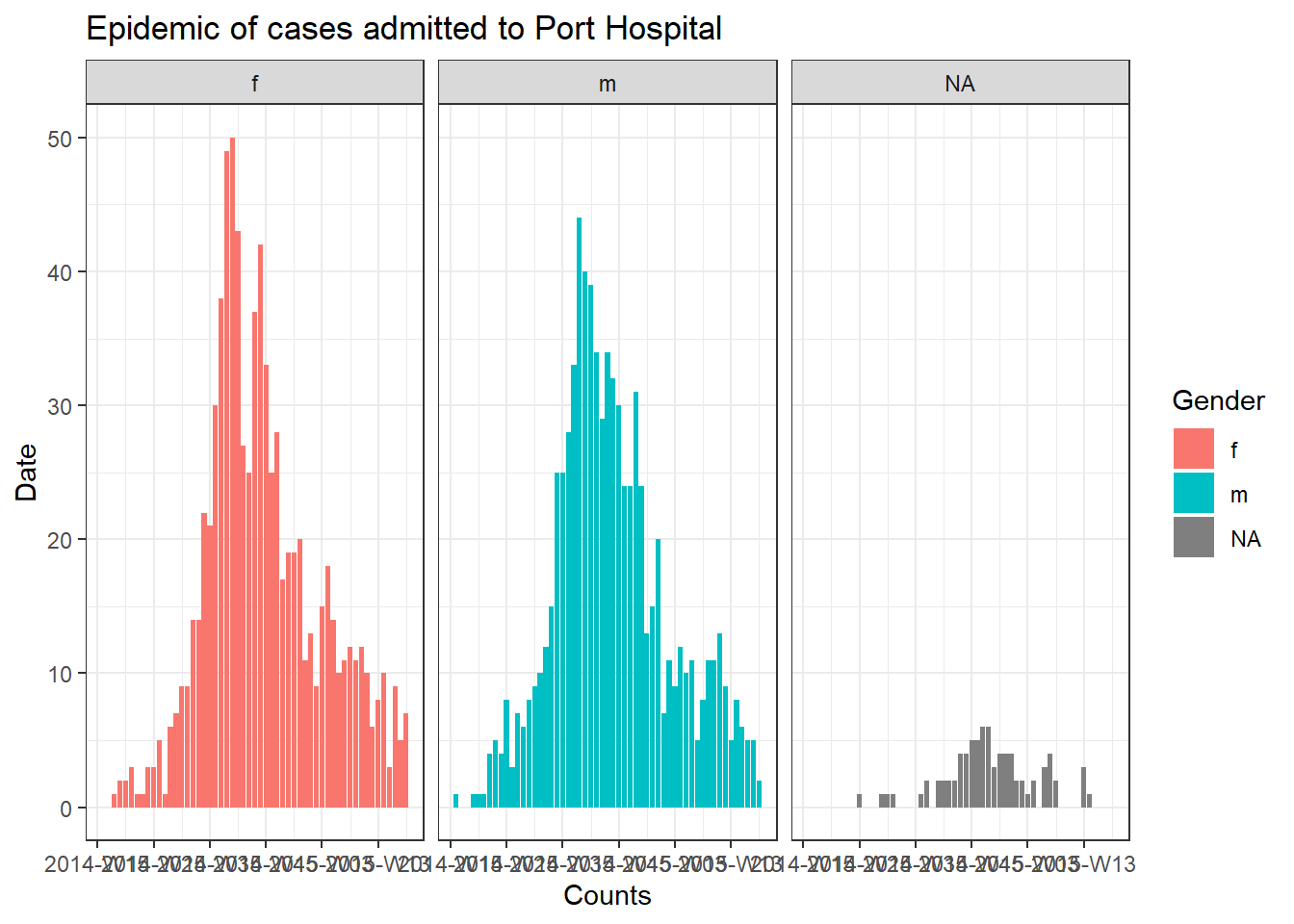
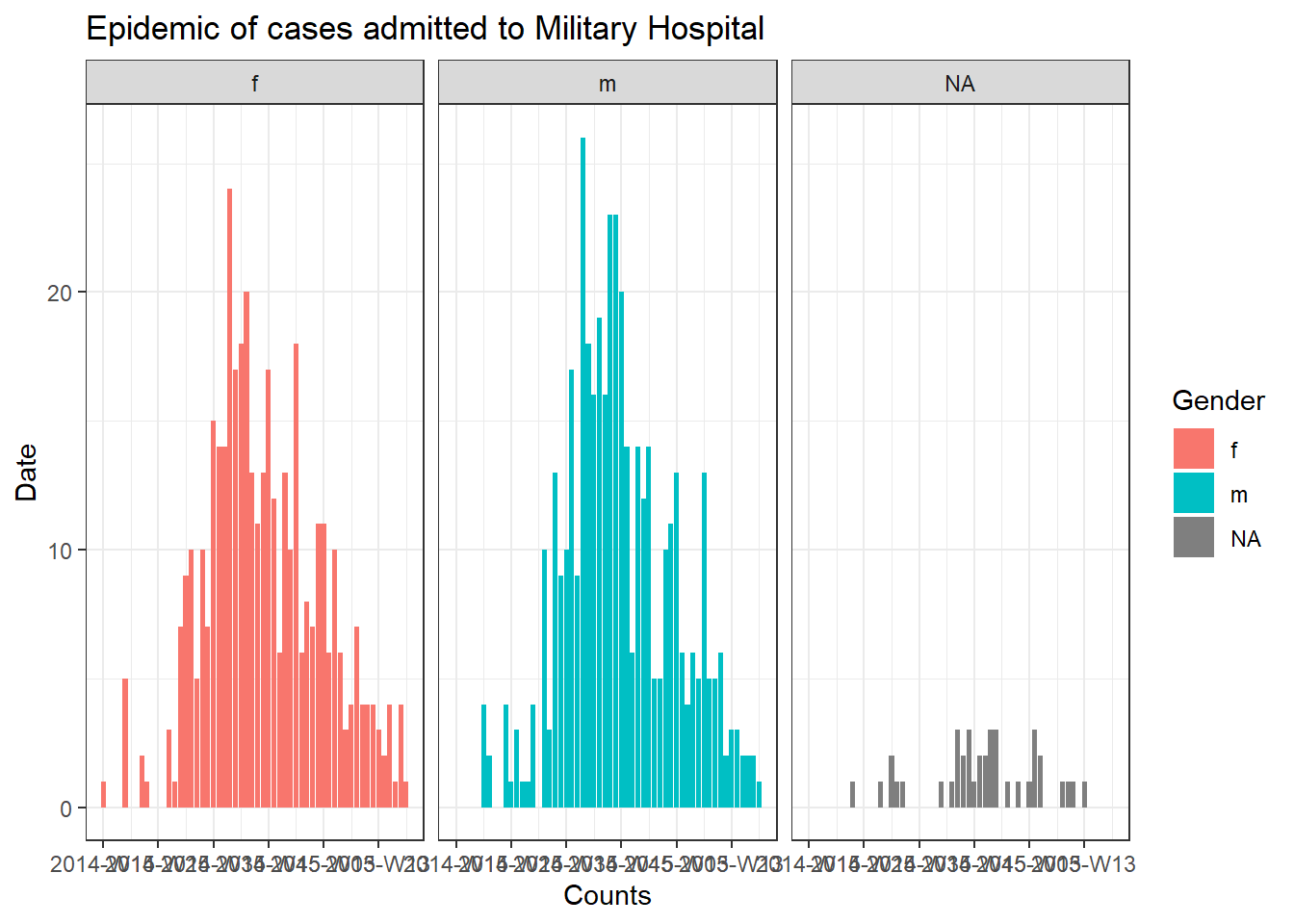
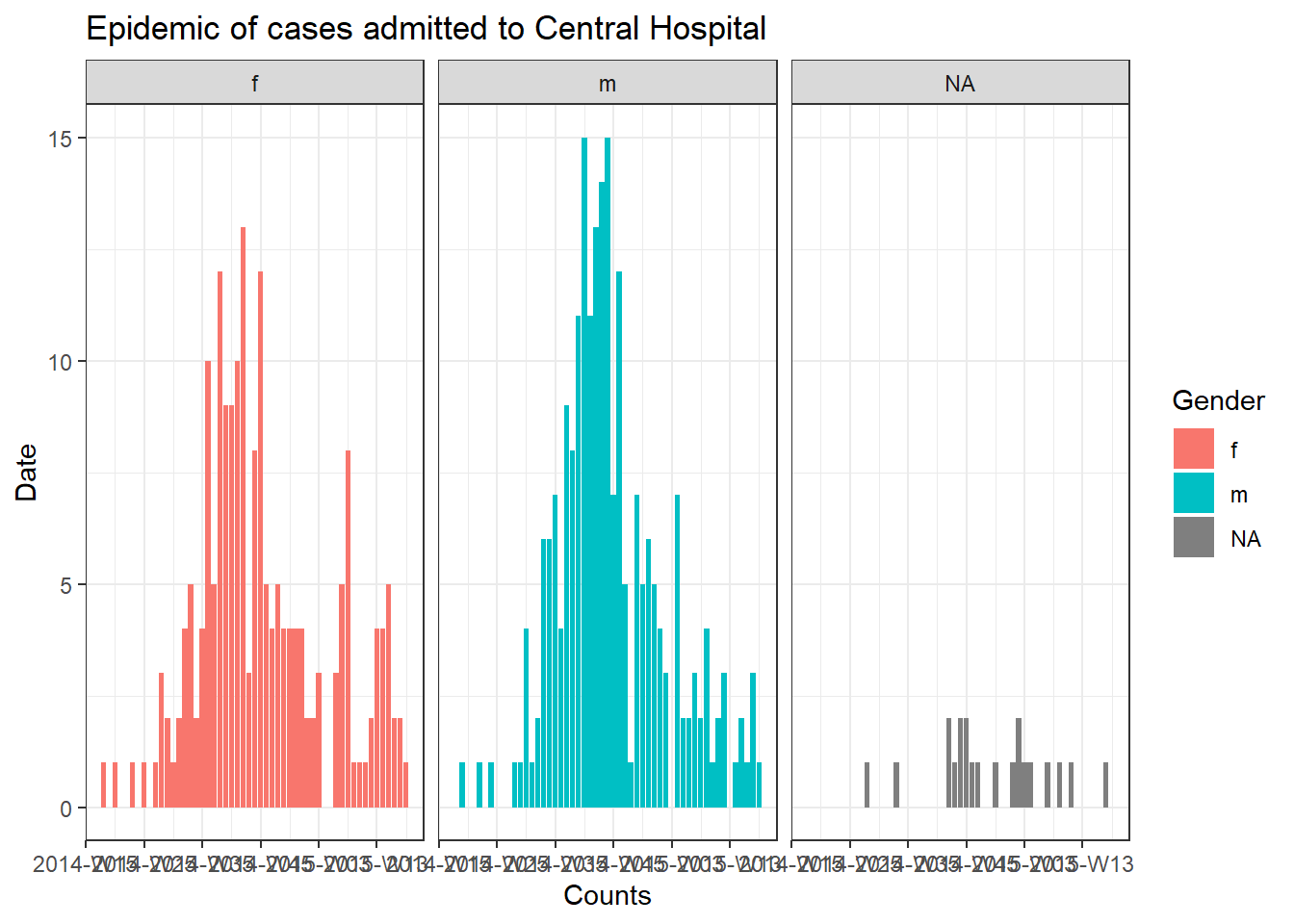
Отслеживание прогресса цикла
Цикл с большим количеством итераций может занять минуты или даже часы. Поэтому может полезным печатать прогресс в консоли R. Утверждение if ниже можно разместить внутри операций цикла, чтобы печатать каждое 100е число. Просто скорректируйте его таким образом, чтобы i была “элементом” в вашем цикле.
# цикл с кодом для печати прогресса каждые 100 итераций
for (i in seq_len(nrow(linelist))){
# печать прогресса
if(i %% 100==0){ # оператор %% - это остаток
print(i)
}16.3 purrr и списки
Еще один подход к итеративным операциям - это пакет purrr - это подход к итерациям из tidyverse.
Если вы столкнулись с выполнением одной и той же задачи несколько раз, наверное, имеет смысл создать обобщенное решение, которое вы можете использовать со многими входными данными. Например, создание графиков для нескольких юрисдикций, либо импорт и объединение множества файлов.
Есть также другие преимущества purrr - вы можете использовать его с операторами канала %>%, он справляется с ошибками лучше обычного цикла for, а синтаксис является весьма чистым и простым! Если вы используете цикл for, вы, скорее всего, сможете сделать то же самое более понятным и коротким образом с помощью purrr!
Помните, что purrr является инструментом функционального программирования. То есть, операции, которые будут применяться циклично, оборачиваются в функции. См. страницу [Написание функций], чтобы узнать, как писать собственные функции.
purrr также почти полностью основана на списках и векторах - поэтому воспринимайте ее как применение функции к каждому элементу этого списка/вектора!
Загрузка пакетов
purrr является частью tidyverse, поэтому нет необходимости устанавливать/загружать отдельный пакет.
pacman::p_load(
rio, # импорт/экспорт
here, # относительные пути к файлу
tidyverse, # управление данными и визуализация
writexl, # написание файла Excel с несколькими листами
readxl # импорт Excel с несколькими листами
)map()
Одна из ключевых функций purrr - это функция map(), которая “сопоставляет” (применяет) функцию к каждому входному элементу списка/вектора, который вы зададите.
Базовый синтаксис: map(.x = ПОСЛЕДОВАТЕЛЬНОСТЬ, .f = ФУНКЦИЯ, ДРУГИЕ АРГУМЕНТЫ). Если смотреть более детально:
-
.x =это входные данные, к которым будет итеративно применяться функция.f- например, вектор имен юрисдикций, столбцов в датафрейме или списка датафреймов
-
.f =это функция, которая применяется в каждому элементу входных данных.x- это может быть такая функция, какprint()которая уже существует, либо это может быть пользовательская функция, которую вы создадите. Функция часто записывается после тильды~(детали ниже).
Еще несколько комментариев по синтаксису:
- Если для функции не требуется уточнять дополнительные аргументы, ее можно записать без скобок и без тильды (например,
.f = mean). Чтобы указать аргументы, которые будут иметь одинаковое значение для каждой итерации, задайте их с помощьюmap(), но за пределами аргумента.f =, например,na.rm = Tвmap(.x = my_list, .f = mean, na.rm=T).
- Вы можете использовать
.x(или просто.) внутри функции.f =в качестве заполнителя для значения.xдля этой итерации
- Используйте синтаксис тильды (
~), чтобы обеспечить больший контроль над функцией - запишите функцию как обычно со скобками, например:map(.x = my_list, .f = ~mean(., na.rm = T)). В частности, используйте этот синтаксис, если значение аргумента будет меняться каждую итерацию, либо если это значение самого.x(см. примеры ниже)
Выходным результатом использования map() будет список list - list (список) является классом объектов, как и вектор, но его элементы могут относиться к разным классам. Таким образом, если список, созданный с помощью map(), может содержать много датафреймов, либо много векторов, много отдельных значений или даже много списков! Существуют альтернативные версии map(), объясненные ниже, которые создают другие типы выходных данных (например, map_dfr() для создания датафрейма, map_chr() для создания текстовых векторов, и map_dbl() для создания числовых векторов).
Пример - импорт и объединение листов Excel
Давайте продемонстрируем на примере частой задачи эпидемиолога: - Вам нужно импортировать рабочую книгу Excel с данными о случаях, но данные разделены на разные именованные листы рабочей книги. Как эффективно импортировать и объединить эти листы в один датафрейм?
Представим, что нам прислали указанную ниже рабочую книгу Excel. На каждом листе содержатся случаи из конкретной больницы.
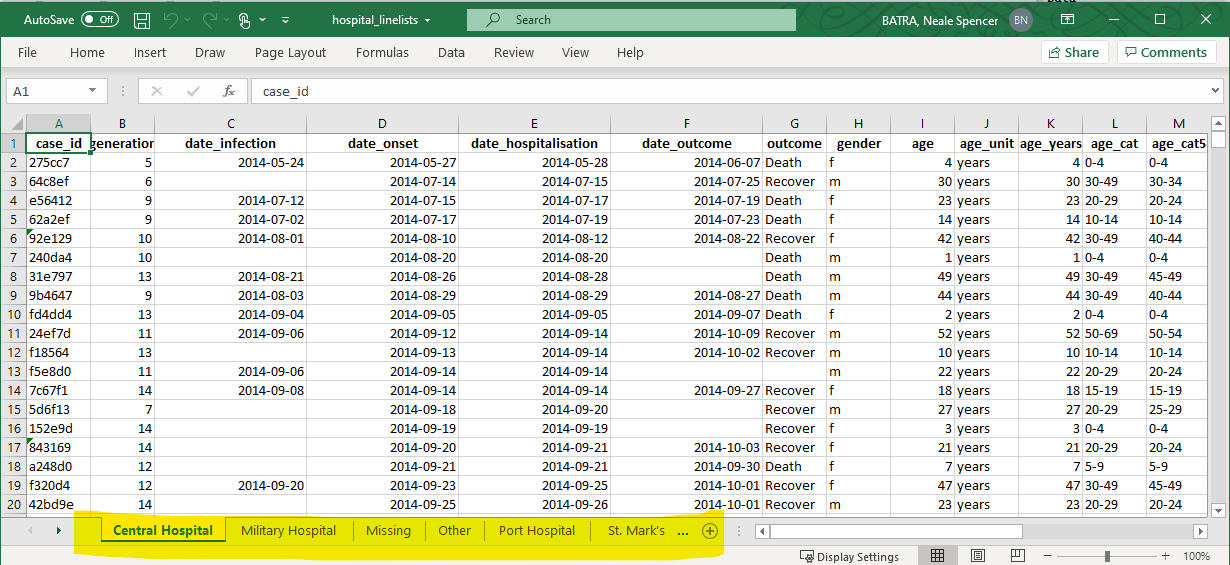
Вот один подход, который использует map():
- используйте
map()для функцииimport(), чтобы она выполнялась для каждого листа Excel
- комбинируйте импортированные датафреймы в один, используя
bind_rows()
- по ходу выполнения сохраните оригинальное имя листа для каждой строки, сохраняя эту информацию в новом столбце итогового датафрейма
Во-первых, нам нужно извлечь имена листов и сохранить их. Мы зададим путь к файлу рабочей книги Excel для функции excel_sheets() из пакета readxl, который извлекает имена листов. Мы их храним в текстовом векторе, называемом sheet_names.
sheet_names <- readxl::excel_sheets("hospital_linelists.xlsx")Вот эти имена:
sheet_names[1] "Central Hospital" "Military Hospital"
[3] "Missing" "Other"
[5] "Port Hospital" "St. Mark's Maternity Hospital"Теперь, когда у нас есть этот вектор имен, map() может задавать их по одному функции import(). В этом примере sheet_names - это .x, а import() - это функция .f.
Вспомните, на странице [Импорт и экспорт] мы говорили, что при использовании для рабочих книг Excel, import() может принять аргумент which =, указывающий, какой лист импортировать. Внутри функции .f import(), мы задаем which = .x, чье значение будет меняться при каждой итерации по вектору sheet_names - сначала “Central Hospital”, потом “Military Hospital” и т.п.
Следует отметить - поскольку мы использовали map(), данные из каждого листа Excel будут сохранены как отдельный датафрейм внутри списка. Мы хотим, чтобы у каждого из этих элементов списка (датафреймов) было имя, поэтому до того, как мы подставим sheet_names к map(), мы передаем его через set_names() из purrr, чтобы у каждого элемента списка было соответствующее имя.
Мы сохраняем полученный в результате список как combined.
combined <- sheet_names %>%
purrr::set_names() %>%
map(.f = ~import("hospital_linelists.xlsx", which = .x))При рассмотрении выходного результата мы видим, что данные из каждого листа Excel сохранены в списке с определенным именем. Это хорошо, но мы еще не закончили.
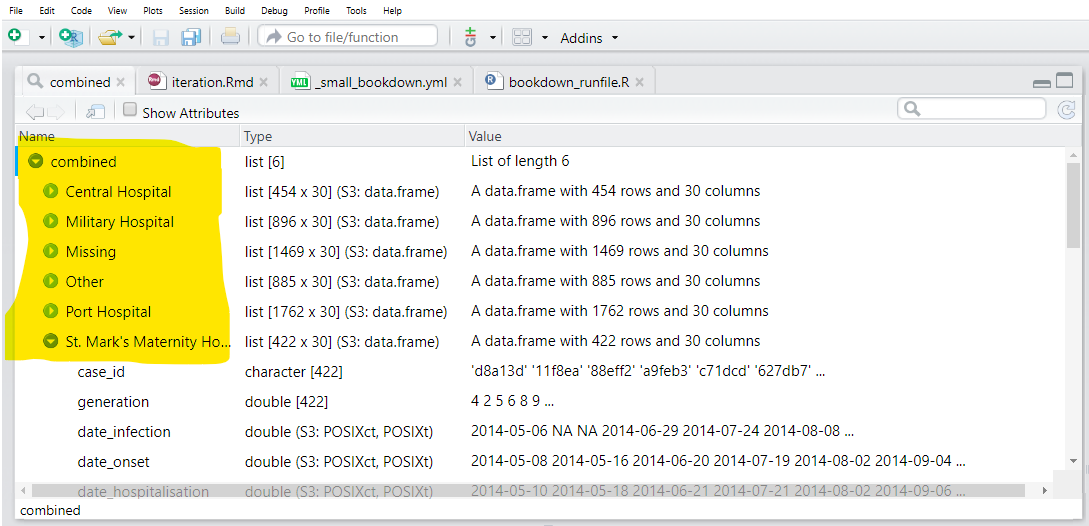
Наконец, мы используем функцию bind_rows() (из dplyr), которая принимает список аналогичным образом структурированных датафреймов и комбинирует их в один датафрейм. Чтобы создать новый столбец из элемента списка names (имена), мы используем аргумент .id = и задаем ему желаемое имя для нового столбца.
Ниже представлена полная последовательность команд:
sheet_names <- readxl::excel_sheets("hospital_linelists.xlsx") # извлекаем имена листов
combined <- sheet_names %>% # начинаем с имен листов
purrr::set_names() %>% # задаем их имена
map(.f = ~import("hospital_linelists.xlsx", which = .x)) %>% # проводим итерации, импорт, сохраняем в списке
bind_rows(.id = "origin_sheet") # объединяем список датафреймов, сохраняем их источник в новом столбце Теперь у нас есть один датафрейм со столбцом, содержащим лист происхождения!
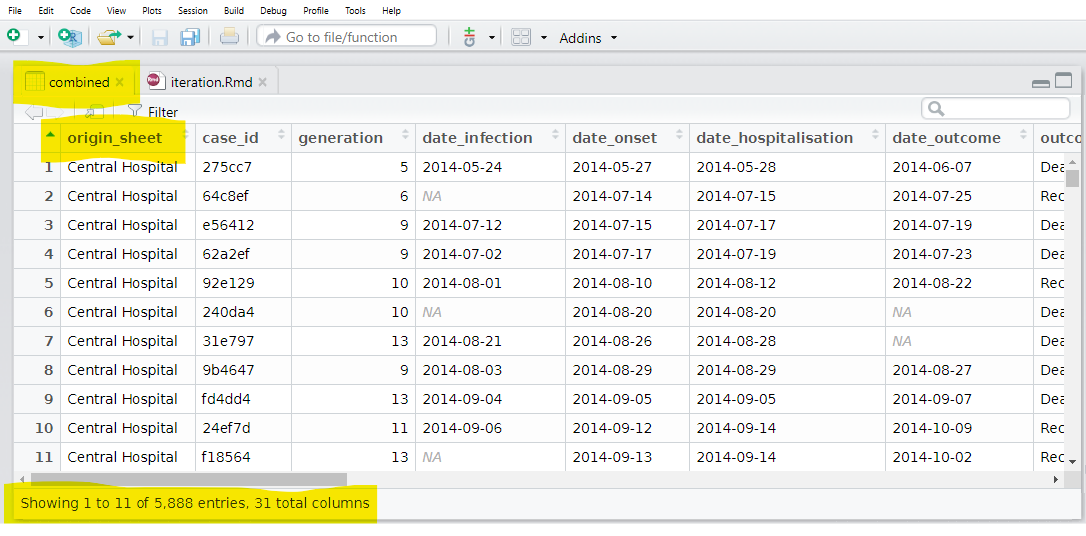
Существуют вариации map(), о которых вам нужно знать. Например, map_dfr() выдает датафрейм, а не список. Таким образом, мы могли бы использоватьт ее для указанной выше задачи и нам не пришлось бы связывать строки. Но тогда мы бы не смогли зафиксировать, из какого листа (больницы) мы получили каждый случай.
Другие вариации включают map_chr(), map_dbl(). Эти функции очень полезны по двум причинам. Во-первых, они автоматически конвертируют выходные данные итеративной функции в вектор (не список). Во-вторых, они могут четко контролировать, в каком классе будут выданы данные, вы можете обеспечить текстовый вектор на выходе с помощью map_chr(), либо числовой вектор с помощью map_dbl(). Вернемся к ним позднее в этом разделе!
Функции map_at() и map_if() также очень полезны для итерации - они позволяют вам уточнить, по каким элементам списка вам нужна итерация! Они работают просто с помощью применения вектора индексов/имен (в случае map_at()) или логического теста (в случае map_if()).
Давайте используем пример, где мы не хотим прочитывать первый лист данных по больнице. Мы используем map_at() вместо map(), и уточняем аргумент .at = в c(-1), что означает не использовать первый элемент .x. Альтернативно вы можете задать вектор положительных чисел или имен в .at =, чтобы уточнить, какие элементы использовать.
sheet_names <- readxl::excel_sheets("hospital_linelists.xlsx")
combined <- sheet_names %>%
purrr::set_names() %>%
# exclude the first sheet
map_at(.f = ~import( "hospital_linelists.xlsx", which = .x),
.at = c(-1))Обратите внимание, что имя первого листа все еще будет появляться как элемент выходного списка - но это только текстовое имя (не датафрейм). Вам нужно удалить этот элемент до связывания строк. Мы рассмотрим, как удалять и модифицировать элементы списка в одном из разделов ниже.
Разделение набора данных и экспорт
Ниже мы приведем пример того, как разделять набор данных на части и затем использовать итерацию map() для экспорта каждой части как отдельного листа Excel, либо как отдельного файла CSV.
Разделение набора данных
Представим, что у нас есть полный построчный список случаев linelist в виде датафрейма, и теперь мы хотим создать отдельный построчный список для каждой больницы и экспортировать его как отдельный CSV файл. Ниже мы выполним следующие шаги:
Используем group_split() (из dplyr), чтобы разделить датафрейм linelist по уникальным значениям в столбце hospital. На выходе мы получим список, содержащий по одному датафрейму на подмножество больниц.
linelist_split <- linelist %>%
group_split(hospital)Мы можем выполнить View(linelist_split) и увидеть, что в этом списке есть 6 датафреймов (таблицы”tibble”), каждая из которых представляет случаи из одной больницы.
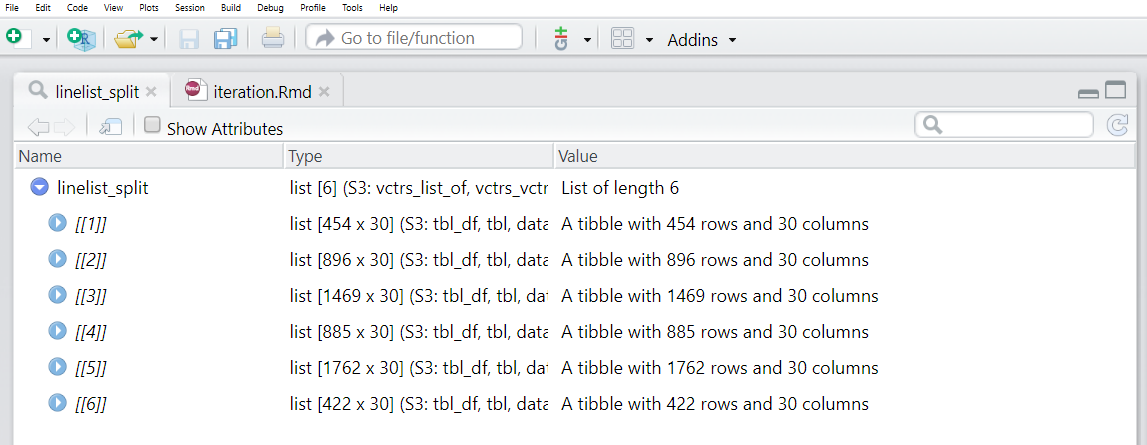
Однако обратите внимание, что датафреймы в списке по умолчанию не имеют имен! Мы хотим, чтобы у каждого было имя, а затем использовать это имя при сохранении CSV файла.
Одним из подходов к извлечению имен будет использовать pull() (из dplyr), чтобы извлечь столбец hospital для каждого датафрейма в списке. Затем, чтобы перестраховаться, мы конвертируем значения в текстовые и затем используем unique(), чтобы получить имя для этого конкретного датафрейма. Все эти шаги применяются к каждому датафрейму с помощью map().
names(linelist_split) <- linelist_split %>% # присваиваем именам указанных датафреймов
# извлекаем имена, выполнив нижеследующее для каждого датафрейма:
map(.f = ~pull(.x, hospital)) %>% # берем столбец hospital
map(.f = ~as.character(.x)) %>% # конвертируем на всякий случай в текстовый
map(.f = ~unique(.x)) # берем уникальное имя больницыТеперь мы можем увидеть, что у каждого элемента списка есть имя. Эти имена мы можем увидеть с помощью names(linelist_split).
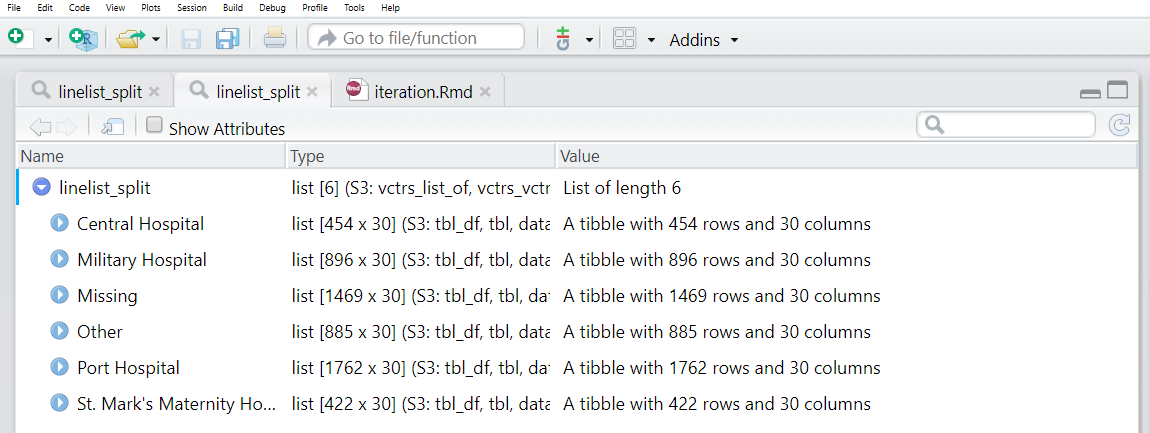
names(linelist_split)[1] "Central Hospital"
[2] "Military Hospital"
[3] "Missing"
[4] "Other"
[5] "Port Hospital"
[6] "St. Mark's Maternity Hospital (SMMH)"Более одного столбца group_split()
Если вы хотите разделить построчный список более чем по одному столбцу группировки, например, создать подмножество из построчного списка на пересечении больницы И пола, вам нужен другой подход к именованию элементов списка. Это требует сбора уникальных “ключей групп”, используя group_keys() из dplyr - они выдаются как датафрейм. Затем вы можете комбинировать групповые ключи в значения с помощью unite(), как показано ниже, и присвоить эти составные имена к linelist_split.
# разделяем построчный список по уникальным комбинациям больницы-пола
linelist_split <- linelist %>%
group_split(hospital, gender)
# извлекаем group_keys() в виде датафрейма
groupings <- linelist %>%
group_by(hospital, gender) %>%
group_keys()
groupings # показываем уникальные группы # A tibble: 18 × 2
hospital gender
<chr> <chr>
1 Central Hospital f
2 Central Hospital m
3 Central Hospital <NA>
4 Military Hospital f
5 Military Hospital m
6 Military Hospital <NA>
7 Missing f
8 Missing m
9 Missing <NA>
10 Other f
11 Other m
12 Other <NA>
13 Port Hospital f
14 Port Hospital m
15 Port Hospital <NA>
16 St. Mark's Maternity Hospital (SMMH) f
17 St. Mark's Maternity Hospital (SMMH) m
18 St. Mark's Maternity Hospital (SMMH) <NA> Теперь мы объединяем эти группировки, разделенные дефисами, и присваиваем их как имена элементов списка в linelist_split. Здесь потребуются несколько дополнительных строк кода, так как мы меняем NA на “Missing”, используем unite() из dplyr для объединения значений столбца (разделенных дефисами), а затем конвертируем в неименованный вектор, чтобы он мог быть использован в качестве имен linelist_split.
# Комбинируем в одно значение имени
names(linelist_split) <- groupings %>%
mutate(across(everything(), replace_na, "Missing")) %>% # меняем NA на "Missing" во всех столбцах
unite("combined", sep = "-") %>% # рбъединяем все значения столбца в одно
setNames(NULL) %>%
as_vector() %>%
as.list()Экспорт в виде листов Excel
Чтобы экспортировать построчные списки больниц в виде рабочей книги Excel с одним построчным списком на лист, мы можем просто указать именованный список linelist_split в функции write_xlsx() из пакета writexl. Это позволит сохранить одну рабочую книгу Excel с несколькими листами. Имена элементов списка автоматически будут применены к именам листов.
linelist_split %>%
writexl::write_xlsx(path = here("data", "hospital_linelists.xlsx"))Теперь вы можете открыть Excel файл и увидеть, что у каждой больницы есть свой лист.
Экспорт в виде CSV файлов
Это чуть более сложная команда, но вы можете также экспортировать каждый построчный список по конкретной больнице в виде отдельного CSV файла с названием файла, специфичным для этой больницы.
Опять же, мы используем map(): мы берем вектор имен элементов списка (показан выше) и применяем map(), чтобы провести по ним итерации, применяя export() (из пакета rio, см. страницу [Импорт и экспорт]) к датафрейму в списке linelist_split, у которого такое имя. Мы также используем имя для создания уникального имени файла. Вот как это работает:
- Мы начинаем с вектора текстовых имен, подставляем в
map()как.x
- Функцией
.fявляетсяexport(), которая требует датафрейма и пути к файлу, куда его записать
- Входные данные
.x(имя больницы) используется внутри.fдля извлечения/индекса этого конкретного элемента из спискаlinelist_split. Это приводит к тому, что только один датафрейм за раз указывается дляexport().
- Например, когда
map()проводит итерацию для “Military Hospital”, тогдаlinelist_split[[.x]]на самом деле являетсяlinelist_split[["Military Hospital"]], выдавая таким образом второй элементlinelist_split- а именно, все случаи из больницы Military Hospital.
- Путь к файлу, указанный для
export()является динамичным с помощью использованияstr_glue()(см. страницу [Текст и последовательности]):-
here()используется, чтобы получить базовый путь к файлу и указать папку “data” (обратите внимание на одинарные кавычки, чтобы не прерывать двойные кавычкиstr_glue())
-
- Затем слэш
/, а затем снова.x, что напечатает текущее имя больницы, чтобы сделать файл идентифицируемым
- Наконец, расширение “.csv”, которое
export()использует для создания CSV файла
names(linelist_split) %>%
map(.f = ~export(linelist_split[[.x]], file = str_glue("{here('data')}/{.x}.csv")))Now you can see that each file is saved in the “data” folder of the R Project “Epi_R_handbook”!
Пользовательские функции
Вы можете захотеть создать собственную функцию, которую зададите в map().
Представим, что вы хотите создать эпидемические кривые для случаев по каждой больнице. Чтобы это сделать, используя purrr, наша функция .f может быть ggplot() и расширения с помощью +, как обычно. В качестве выходных данных map() мы всегда получаем список, графики сохраняются в списке (list). Поскольку это графики, их можно извлечь и построить с помощью функции ggarrange() из пакета ggpubr (документация).
# загрузите пакет для построения элементов из списка
pacman::p_load(ggpubr)
# постройте по вектору 6 имен больниц (созданных ранее)
# используйте указанную функцию ggplot
# выходным результатом будет список с 6 графиками ggplot
hospital_names <- unique(linelist$hospital)
my_plots <- map(
.x = hospital_names,
.f = ~ggplot(data = linelist %>% filter(hospital == .x)) +
geom_histogram(aes(x = date_onset)) +
labs(title = .x)
)
# напечатайте графики ggplot (они хранятся в списке)
ggarrange(plotlist = my_plots, ncol = 2, nrow = 3)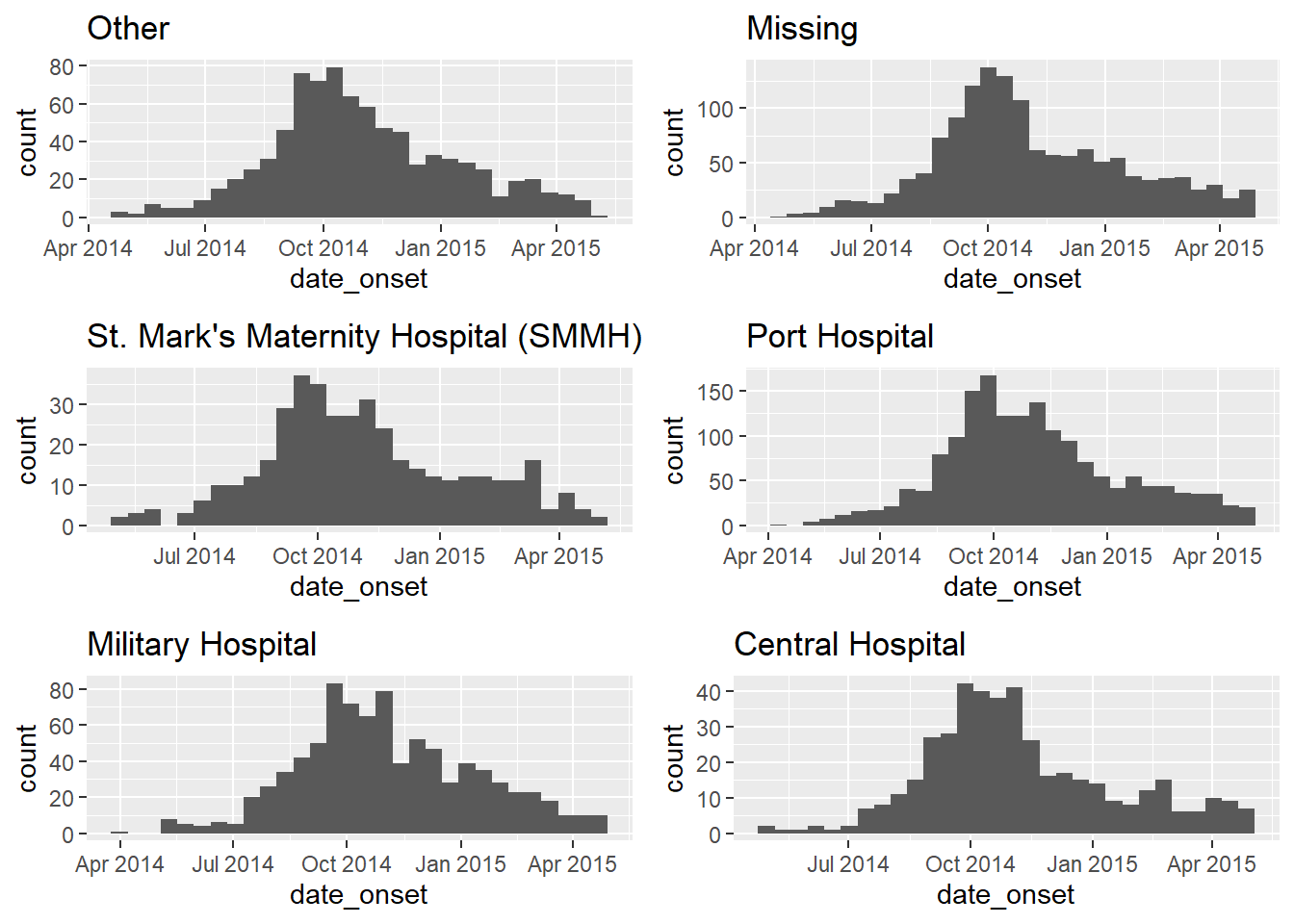
Если этот код map() выглядит слишком хаотично, вы можете получить тот же результат, сохранив вашу конкретную команду ggplot() как пользовательскую функцию, например, мы можем ее назвать make_epicurve()). Эта функция затем используется внутри map(). .x будет итеративно замещаться именем больницы и будет использован как hosp_name в функции make_epicurve(). См. страницу [Написание функций].
# Создаем функцию
make_epicurve <- function(hosp_name){
ggplot(data = linelist %>% filter(hospital == hosp_name)) +
geom_histogram(aes(x = date_onset)) +
theme_classic()+
labs(title = hosp_name)
}# сопоставляем
my_plots <- map(hospital_names, ~make_epicurve(hosp_name = .x))
# печатаем графики ggplot (они хранятся в списке)
ggarrange(plotlist = my_plots, ncol = 2, nrow = 3)Применение функций к нескольким столбцам
Еще один частый пример - применить функцию к нескольким столбцам. Ниже мы применяем функцию t.test() с помощью map() к числовым столбцам в датафрейме linelist, сравнивая числовые значения по полу.
Вспмоните из страницы [Простые статистические тесты], что t.test() может принять входные данные в формате формулы, такие как t.test(числовой столбец ~ двоичный столбец). В этом примере мы делаем нижеследующее:
- Интересующие числовые столбцы выбираются из
linelist- они становятся входными данными.xдляmap()
- Функция
t.test()указывается как функция.f, которая применяется к каждому числовому столбцу
- Внутри скобок
t.test():- первая
~стоит перед.f, по которойmap()будет проводить итерацию.x
-
.xотражает текущий столбец, который подается в функциюt.test()
- вторая
~является частью уравнения t-test, описанного выше
- функция
t.test()ожидает двоичный столбец с правой стороны уравнения. Мы задаем векторlinelist$genderнезависимо и статично (обратите внимание, что он не включен вselect()).
- первая
map() выдает список, поэтому выходными результатами является список результатов t-теста - по одному элементу списка для каждого проанализированного числового столбца.
# Результаты сохраняются как список
t.test_results <- linelist %>%
select(age, wt_kg, ht_cm, ct_blood, temp) %>% # сохраняем только некоторые числовые столбцы для map across
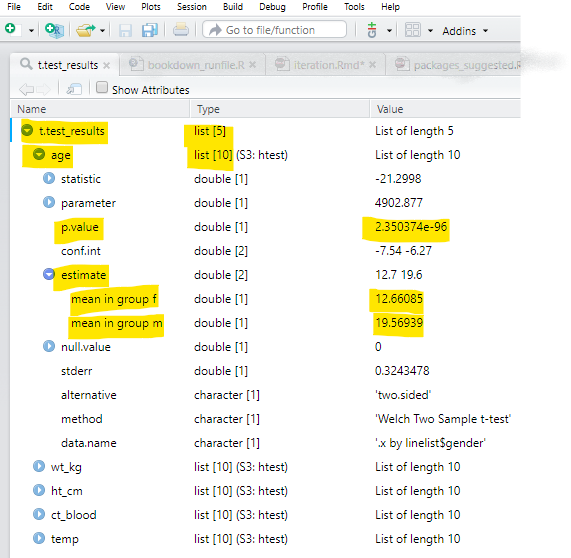
map(.f = ~t.test(.x ~ linelist$gender)) # функция t.test, с уравнением ЧИСЛОВОЕ ~ КАТЕГОРИАЛЬНОЕВот как выглядит список t.test_results при открытии (просмотре) в RStudio. Мы выделили те части, которые важны для примеров на этой странице.
- Вы можете увидеть сверху, что весь список называется
t.test_resultsи содержит пять элементов. Эти пять элементов называютсяage,wt_km,ht_cm,ct_blood,tempпо каждой переменной, которая использовалась в t-тесте сgender(пол) из построчного спискаlinelist.
- Каждый из этих пяти элементов сам по себе является списком с такими элементами внутри, как
p.valueиconf.int. Некоторые из этих элементов, такие какp.valueявляются отдельными числами, а некоторы - например,estimate, состоят из двух или более элементов (mean in group f(среднее в группе f) иmean in group m(среднее в группе m)).
Примечание: Помните, что если вы хотите применить функцию только к определенным столбцам в датафрейме, вы можете просто использовать mutate() и across(), как объяснялось на странице [Вычистка данных и ключевые функции]. Ниже приведен пример применения as.character() только к столбцу “age” (возраст). Обратите внимание на размещение скобок и запятых.
# конвертируем столбцы с именем столбца, содержащим "age" в текстовый класс
linelist <- linelist %>%
mutate(across(.cols = contains("age"), .fns = as.character)) Извлечение из списков
Так как map() выдает выходной результат в классе список, мы обсудим, как извлекать данные из списков, используя соответствующие функции purrr. Чтобы это продемонстрировать, мы будем использовать список t.test_results из предыдущего раздела. Это список из 5 списков - каждый из 5 списков содержит результаты t-теста между столбцом из датафрейма linelist и его двоичным столбцом gender. См. изображение в разделе выше, где показана структура списка визуально.
Имена элементов
Чтобы извлечь имена самих элементов, просто используйте names() из базового R. В таком случае мы используем names() для t.test_results, чтобы выдать имена каждого под-списка, которые являются именами 5 переменных, по которым проводились t-тесты.
names(t.test_results)[1] "age" "wt_kg" "ht_cm" "ct_blood" "temp" Элементы по имени или позиции
Чтобы извлечь элементы списка по именам или по позиции, вы можете использовать квадратные скобки [[ ]], как описано на странице [Основы R]. Ниже мы используем двойные квадратные скобки, чтобы индексировать список t.tests_results и отобразить первый элемент, который является результатом t-теста по age (возраст).
t.test_results[[1]] # первый элемент по позиции
Welch Two Sample t-test
data: .x by linelist$gender
t = -21.3, df = 4902.9, p-value < 2.2e-16
alternative hypothesis: true difference in means between group f and group m is not equal to 0
95 percent confidence interval:
-7.544409 -6.272675
sample estimates:
mean in group f mean in group m
12.66085 19.56939 t.test_results[[1]]["p.value"] # выдает элемент с именем "p.value" из первого элемента $p.value
[1] 2.350374e-96Однако ниже мы продемонстрируем использование простых и гибких функций purrr map() и pluck() для достижения таких же результатов.
pluck()
pluck() извлекает элемент по имени или позиции. Например - чтобы извлечь результаты t-теста для возраста, вы можете использовать pluck() следующим образом:
t.test_results %>%
pluck("age") # альтернативно, используем pluck(1)
Welch Two Sample t-test
data: .x by linelist$gender
t = -21.3, df = 4902.9, p-value < 2.2e-16
alternative hypothesis: true difference in means between group f and group m is not equal to 0
95 percent confidence interval:
-7.544409 -6.272675
sample estimates:
mean in group f mean in group m
12.66085 19.56939 Индексируйте более глубокие уровни, указывая последующие уровни запятыми. Приведенный ниже код извлекает элемент под названием “p.value” из списка age внутри списка t.test_results. Вы можете также использовать числа вместо текстовых имен.
t.test_results %>%
pluck("age", "p.value")[1] 2.350374e-96Вы можете извлекать такие внутренние элементы из всех элементов первого уровня, используя map(), чтобы выполнить функцию pluck() по каждому элементу первого уровня. Например, код ниже извлекает элементы “p.value” из всех списков внутри t.test_results. Список результатов т-теста является .x, по которому проводится итерация, pluck() является функцией .f, которая подлежит итерации, а значение “p-value” задается в функцию.
t.test_results %>%
map(pluck, "p.value") # выдать каждое p-значение$age
[1] 2.350374e-96
$wt_kg
[1] 2.664367e-182
$ht_cm
[1] 3.515713e-144
$ct_blood
[1] 0.4473498
$temp
[1] 0.5735923В качестве еще одной альтернативы map() предлагает сокращение, где вы можете записать имя элемента в кавычках, и она его извлечет. Если вы используете map(), выходным результатом будет список, а если вы используете map_chr() - это будет именованный текстовый вектор, а если вы используете map_dbl() - то именованный числовой вектор.
t.test_results %>%
map_dbl("p.value") # выдать p-значения как именованный числовой вектор age wt_kg ht_cm ct_blood temp
2.350374e-96 2.664367e-182 3.515713e-144 4.473498e-01 5.735923e-01 Более детально о pluck() вы можете прочитать в purrr документации. У нее есть родственная функция chuck(), которая выдаст ошибку вместо NULL, если элемент не существует.
Конвертация списка в датафрейм
Это сложная тема - см. раздел Ресурсы с более полными самоучителями. Тем не менее, мы продемонстрируем конвертацию списка результатов t-теста в датафрейм. Мы создадим датафрейм со столбцами для переменной, ее p-значения и со средними значениями из двух групп (мужчины и женщины).
Вот некоторые из новых подходов и функций, которые будут использованы:
- Фнукция
tibble()будет использована для создания таблицы tibble (как датафрейм)- Мы заключаем функцию
tibble()в фигурные скобки{ }, чтобы предотвратить сохранение всехt.test_resultsв качестве первого столбца tibble
- Мы заключаем функцию
- Внутри
tibble()создается каждый столбец, похожим образом как в синтаксисеmutate():-
.представляетt.test_results - Чтобы создать столбец с именами переменных t-теста (имена каждого элемента списка), мы используем
names(), как описано выше
- Чтобы создать столбец с p-значениями, мы используем
map_dbl()как описано выше, чтобы извлечь элементыp.valueи конвертировать их в числовой вектор
-
t.test_results %>% {
tibble(
variables = names(.),
p = map_dbl(., "p.value"))
}# A tibble: 5 × 2
variables p
<chr> <dbl>
1 age 2.35e- 96
2 wt_kg 2.66e-182
3 ht_cm 3.52e-144
4 ct_blood 4.47e- 1
5 temp 5.74e- 1Но теперь давайте добавим столбцы, содержащие средние значения для каждой группы (мужчины и женщины).
Нам нужно извлечь элемент estimate, но он на самом деле содержит два элемента (mean in group f (среднее значение в группе f) и mean in group m(среднее значение в группе m)). Таким образом, его невозможно упростить в вектор с помощью map_chr() или map_dbl(). Вместо этого, мы используем map(), которая при использовании внутри tibble() создаст столбец класса список (list) внутри tibble! Да, это возможно!
t.test_results %>%
{tibble(
variables = names(.),
p = map_dbl(., "p.value"),
means = map(., "estimate"))}# A tibble: 5 × 3
variables p means
<chr> <dbl> <named list>
1 age 2.35e- 96 <dbl [2]>
2 wt_kg 2.66e-182 <dbl [2]>
3 ht_cm 3.52e-144 <dbl [2]>
4 ct_blood 4.47e- 1 <dbl [2]>
5 temp 5.74e- 1 <dbl [2]> Как только у вас будет этот столбец в классеп список, есть несколько функций tidyr (часть tidyverse), которые помогут вам разложить эти столбцы “многоуровневого списка”. Более подробно прочитайте об этом тут, либо введя vignette("rectangle"). Вкратце:
-
unnest_wider()- дает каждому элементу столбца-списка свой собственный столбец
-
unnest_longer()- дает каждому элементу столбца-списка свою собственную строку -
hoist()- действует какunnest_wider(), но вы уточняете, какие элементы разложить
Ниже мы задаем tibble в unnest_wider(), уточняя столбец из tibble means (который является многоуровневым списком). Результатом будет то, что вместо means мы получаем два новых столбца, каждый из которых отображает два элемента, которые раньше находились в каждой ячейке means.
t.test_results %>%
{tibble(
variables = names(.),
p = map_dbl(., "p.value"),
means = map(., "estimate")
)} %>%
unnest_wider(means)# A tibble: 5 × 4
variables p `mean in group f` `mean in group m`
<chr> <dbl> <dbl> <dbl>
1 age 2.35e- 96 12.7 19.6
2 wt_kg 2.66e-182 45.8 59.6
3 ht_cm 3.52e-144 109. 142.
4 ct_blood 4.47e- 1 21.2 21.2
5 temp 5.74e- 1 38.6 38.6Удаление, сохранение и сжатие списков
Поскольку работа с purrr так часто предполагает списки, мы кратко рассмотрим некоторые функции purrr для модификации списков. См. раздел Ресурсы, где указаны более подробные самоучители по функциям purrr.
-
list_modify()имеет множество применений, в том числе для удаления элемента списка
-
keep()сохраняет элементы, указанные в.p =, либо там, где функция, указанная в.p =оценена как TRUE (ИСТИНА)
-
discard()удаляет элементы, указанные в.p, либо там, где функция, указанная в.p =оценена как TRUE (ИСТИНА)
-
compact()удаляет все пустые элементы
Вот некоторые примеры использования списка combined, созданного в разделе выше использование map() для импорта и объединения нескольких файлов (он содержит 6 датафреймов построчного списка случаев):
Элементы могут быть удалены по имени с помощью list_modify() и установки имени (name) равного NULL.
combined %>%
list_modify("Central Hospital" = NULL) # удаляем элемент списка по имениВы можете также удалить элементы по критериям, задасв “предикативное” уравнение в .p = (уравнение, которое оценивает как TRUE (ИСТИНА) или FALSE(ЛОЖЬ)). Разместите тильду ~ до функции и используйте .x, чтобы отобразить элемент списка. При использовании keep() элементы списка, оцененые как TRUE (ИСТИНА) будут сохранены. И наборот, при использовании discard() элементы списка, оцененные как TRUE (ИСТИНА) будут удалены.
# сохраняем только элементы списка, где более 500 строк
combined %>%
keep(.p = ~nrow(.x) > 500) В примере ниже, элементы списка удаляются, если они не относятся к классу датафрейма.
# удаляем все элементы списка, которые не являются датафреймами
combined %>%
discard(.p = ~class(.x) != "data.frame")Ваша предикативная функция также может ссылаться на элементы/столбцы внутри каждого элемента списка. Например, ниже удаляются элементы списка, где среднее значение столбца ct_blood составляет более 25.
# сохраняем только те элементы списка, где среднее значение столбца ct_blood выше 25
combined %>%
discard(.p = ~mean(.x$ct_blood) > 25) Эта команда удалит все пустые элементы списка:
# Удаляем все пустые элементы списка
combined %>%
compact()pmap()
РАЗДЕЛ НАХОДИТСЯ В РАЗРАБОТКЕ
16.4 Функции Apply
Семейство фукнций “apply” является альтернативой purrr для итеративных операций из базового R. Более подробно можно об этом почитать тут.
16.5 Ресурсы
R для науки о данных страница по итерациям
Виньетка по написанию/прочтению Excel файлов
purrr самоучитель от jennybc
Еще один purrr самоучитель от Rebecca Barter
purrr самоучитель по map, pmap, и imap
{kind=link}