![]()
4 Chuyển đổi sang R
Dưới đây, chúng tôi cung cấp một số lời khuyên và tài nguyên nếu bạn đang chuyển đổi sang R.
R được giới thiệu vào cuối những năm 1990 và kể từ đó đã phát triển quy mô mạnh mẽ. Khả năng của nó rộng đến mức các lựa chọn thương mại thay thế đã phản ứng với sự phát triển của R để duy trì tính cạnh tranh! (đọc bài viết so sánh R, SPSS, SAS, STATA và Python).
Hơn thế nữa, R đã dễ học hơn nhiều so với 10 năm trước. Trước đây, R nổi tiếng là khó sử dụng cho những người mới bắt đầu. Giờ đây việc này trở nên dễ dàng hơn nhiều với giao diện người dùng thân thiện như RStudio, code trực quan như tidyverse và có nhiều tài nguyên hướng dẫn.
Đừng ngần ngại - hãy đến khám phá thế giới của R!
4.1 Từ Excel
Chuyển đổi từ Excel trực tiếp sang R hoàn toàn là mục tiêu có thể đạt được. Nó dường như có vẻ khó khăn, nhưng bạn có thể làm được!
Sự thật là một người có kỹ năng Excel tốt có thể thực hiện các thao tác nâng cao chỉ trong Excel - ngay cả khi sử dụng các công cụ tạo script như VBA. Excel được sử dụng trên toàn thế giới và là một công cụ cần thiết cho một nhà dịch tễ học. Tuy nhiên, kết hợp nó với R có thể cải thiện và mở rộng đáng kể quy trình công việc của bạn.
Lợi ích
Bạn sẽ thấy rằng việc sử dụng R mang lại những lợi ích to lớn trong việc tiết kiệm thời gian, giúp phân tích nhất quán và chính xác hơn, có khả năng tái lập, khả năng chia sẻ và sửa lỗi nhanh hơn. Giống như bất kỳ phần mềm mới nào, bạn phải đầu tư một “đường cong” thời gian học tập để trở nên quen thuộc. Bạn sẽ được mở ra những kĩ năng mới trên một phạm vi rộng đáng kể với R.
Excel là một phần mềm phổ biến mà người dùng mới bắt đầu có thể dễ dàng sử dụng để tạo ra các phân tích và sơ đồ hóa đơn giản với các thao tác “trỏ và nhấp”. Trong khi đó, có thể mất vài tuần để trở nên quen thuộc với các chức năng và giao diện của R. Tuy nhiên, R đã phát triển trong những năm gần đây để trở nên thân thiện hơn với người mới bắt đầu.
Nhiều quy trình làm việc của Excel phụ thuộc vào trí nhớ và sự lặp lại - do đó, có nhiều khả năng xảy ra lỗi. Hơn nữa, nhìn chung, việc làm sạch dữ liệu, phương pháp phân tích và các phương trình được sử dụng đều bị ẩn đi trong trang tính. Có thể cần đến một khoảng thời gian đáng kể để những người mới bắt đầu hiểu trang tính Excel đang làm gì và cách khắc phục sự cố. Với R, tất cả các bước được viết rõ ràng trong script và có thể dễ dàng xem, chỉnh sửa, sửa lỗi và áp dụng cho các bộ dữ liệu khác.
Để bắt đầu chuyển đổi từ Excel sang R, bạn phải điều chỉnh tư duy của mình theo một số hướng quan trọng:
Tidy data
Sử dụng “tidy” data để máy có thể đọc được thay vì dữ liệu lộn xộn “con người có thể đọc được”. Dưới đây là ba yêu cầu chính đối với “tidy” data”, đã được giải thích trong hướng dẫn này về “tidy” data trong R:
- Mỗi biến số nằm trên một cột
- Mỗi quan sát phải nằm trên một hàng
- Mỗi giá trị phải có ô riêng
Đối với người dùng Excel - hãy nghĩ đến vai trò của “bảng” Excel trong việc chuẩn hóa dữ liệu và làm cho định dạng trở nên dễ đoán hơn.
Một ví dụ về “tidy” data là trường hợp bộ dữ liệu linelist được sử dụng trong cuốn sổ tay này - mỗi biến được chứa trong một cột, mỗi quan sát (mỗi trường hợp) có hàng riêng và mọi giá trị chỉ nằm trong một ô. Dưới đây, bạn có thể xem 50 hàng đầu tiên của bộ dữ liệu linelist:
Nguyên nhân chính khiến người dùng gặp phải tình trạng non-tidy data là do nhiều bảng tính Excel được thiết kế để ưu tiên con người dễ đọc chứ không phải máy móc/phần mềm dễ đọc.
Để giúp bạn thấy sự khác biệt, dưới đây là một số ví dụ mô phỏng về non-tidy data mà ưu tiên khả năng đọc của con người hơn khả năng đọc của máy:
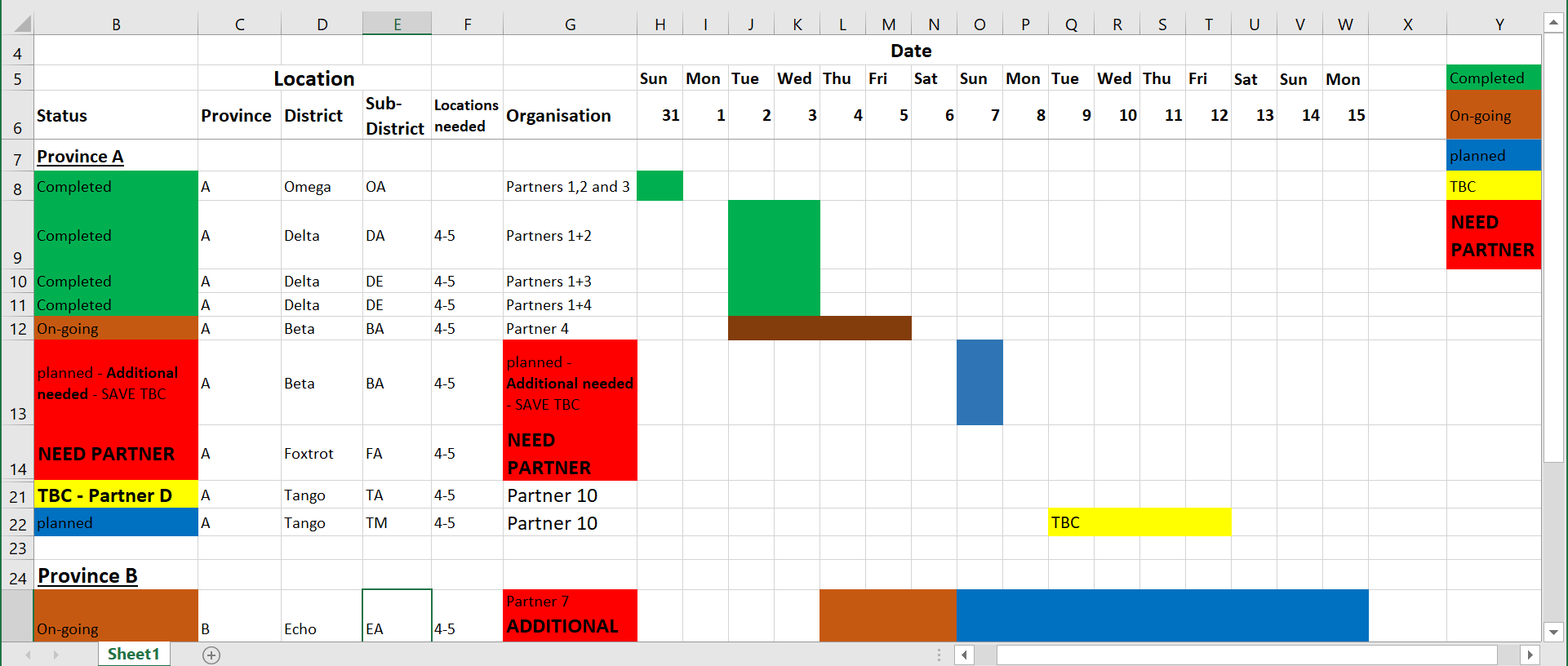
Vấn đề: Trong bảng tính ở trên, một số ô đã được ghép với nhau - khiến chúng trở nên khó đọc bởi R. Hàng nào nên được coi là “tiêu đề” không rõ ràng. Từ điển dựa trên màu sắc nằm ở phía bên phải và các giá trị ô được biểu thị bằng màu sắc - điều này cũng không dễ dàng được giải thích bởi R (cũng như những người bị mù màu!). Hơn nữa, các phần thông tin khác nhau được kết hợp thành một ô (nhiều tổ chức đối tác hoạt động trong cùng một khu hoặc trạng thái “TBC” trong cùng ô với “Partner D”).
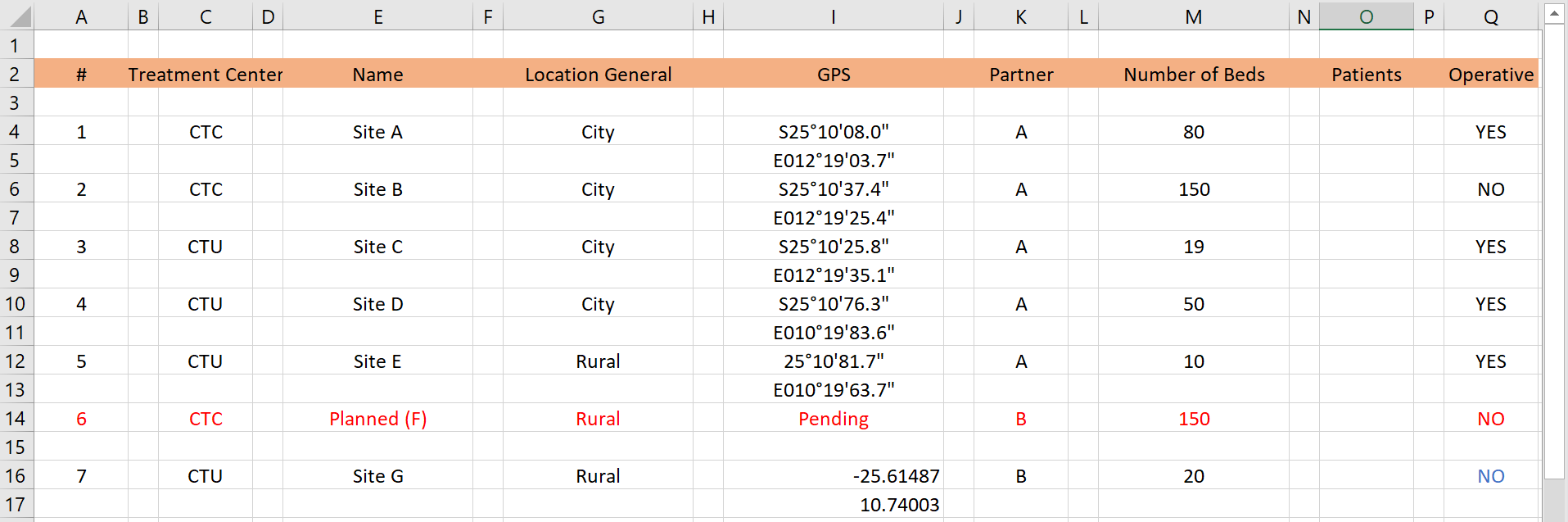
Vấn đề: Trong bảng tính ở trên, có rất nhiều hàng và cột trống trong bộ dữ liệu - điều này sẽ gây phiền toái khi làm sạch trong R. Hơn nữa, tọa độ GPS được trải rộng trên hai hàng cho một trung tâm điều trị nhất định. Một lưu ý nhỏ - tọa độ GPS có hai định dạng khác nhau!
Các bộ dữ liệu “tidy” có thể không đọc được bằng mắt người, nhưng chúng giúp việc làm sạch và phân tích dữ liệu dễ dàng hơn rất nhiều! Tidy data có thể được lưu trữ ở nhiều định dạng khác nhau, chẳng hạn như dạng “dọc” hoặc “ngang”“(xem chương về Xoay trục dữ liệu), tuy nhiên các nguyên tắc trên vẫn được tuân thủ.
Hàm
Từ “hàm (function)” trong R có thể mới, nhưng khái niệm này cũng tồn tại trong Excel dưới dạng công thức (formulas). Công thức trong Excel cũng yêu cầu cú pháp chính xác (ví dụ: vị trí của dấu chấm phẩy và dấu ngoặc đơn). Tất cả những gì bạn cần làm là tìm hiểu một vài hàm mới và cách chúng hoạt động cùng nhau trong R.
Script
Thay vì nhấp vào các biểu tượng và kéo các ô, bạn sẽ viết mọi bước và quy trình thành một “script”. Người dùng Excel có thể quen thuộc với “VBA macros”, thứ mà cũng sử dụng cách tiếp cận script.
R script bao gồm các hướng dẫn từng bước. Điều này cho phép bất kỳ đồng nghiệp nào cũng có thể đọc script và dễ dàng xem các bước bạn đã thực hiện. Điều này cũng giúp loại bỏ lỗi hoặc các tính toán không chính xác. Xem phần R cơ bản về script để có thêm các ví dụ.
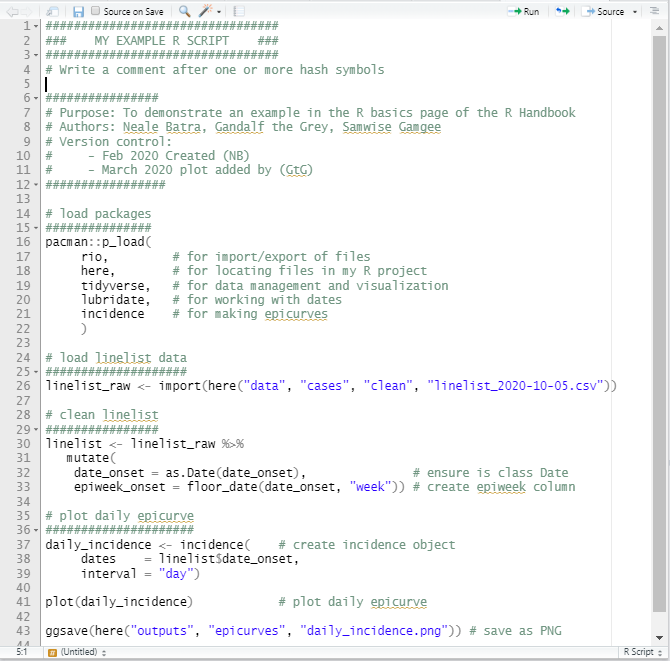
Dưới đây là một ví dụ của một R script:
Tài liệu liên quan đến chuyển đổi từ Excel-sang-R
Dưới đây là một vài đường link hướng dẫn giúp bạn chuyển đổi sang R từ Excel:
Tương tác giữa R và Excel
R có khả năng mạnh trong việc nhập các Excel workbook, làm việc với dữ liệu, xuất/lưu tệp Excel và làm việc với các sắc thái của các trang tính Excel.
Đúng là một số định dạng Excel có tính thẩm mỹ hơn có thể bị mất trong quá trình chuyển đổi (ví dụ: chữ nghiêng, chữ nằm ngang, v.v.). Nếu quy trình công việc của bạn yêu cầu chuyển tài liệu qua lại giữa R và Excel trong khi vẫn giữ nguyên định dạng Excel ban đầu, hãy thử các package như openxlsx.
4.2 Từ Stata
Chuyển đến R từ Stata
Nhiều nhà dịch tễ học được dạy cách sử dụng Stata ngay từ đầu, và có vẻ khó khăn khi chuyển sang R. Tuy nhiên, nếu bạn là một người dùng quen Stata thì việc chuyển sang R chắc chắn sẽ dễ quản lý hơn bạn nghĩ. Mặc dù có một số khác biệt chính giữa Stata và R về cách tạo và sửa đổi dữ liệu, cũng như cách triển khai các chức năng phân tích – sau khi tìm hiểu những khác biệt chính này, bạn sẽ có thể chuyển đổi các kỹ năng của mình.
Dưới đây là một số cách chuyển đổi chính giữa Stata và R, điều mà có thể hữu ích khi bạn xem lại hướng dẫn này.
Những lưu ý chung
5 STATABạn chỉ có thể xem và thao tác với một bộ dữ liệu tại một thời điểm |
6 RBạn có thể xem và thao tác với nhiều bộ dữ liệu cùng một lúc, do đó, bạn sẽ thường xuyên phải xác định bộ dữ liệu của mình trong code |
|
| Cộng đồng trực tuyến có sẵn trên https://www.statalist.org/ | Cộng đồng trực tuyến có sẵn trên RStudio, StackOverFlow và R-bloggers | |
| Thao tác trỏ và nhấp chuột như một tùy chọn | Thao tác trỏ và nhấp chuột được giảm tối thiểu | |
Trợ giúp cho các lệnh có sẵn trong help [command]
|
Trợ giúp có sẵn trong [function]? hoặc tìm kiếm trong cửa sổ Help |
|
| Bình luận code sử dụng * hoặc /// hoặc /* VĂN BẢN */ | Bình luận code sử dụng # | |
| Hầu hết tất cả các lệnh đều được tích hợp sẵn trong Stata. Các lệnh mới do người dùng viết có thể được cài đặt như file ado sử dụng ssc install [package] | R được cài đặt sẵn các lệnh cơ bản, nhưng quá trình sử dụng thông thường cần cài đặt các package khác từ CRAN (xem chương R cơ bản) | |
| Phân tích thường được viết trong do file | Phân tích được viết trong R script ở cửa sổ chính của RStudio. Các script của R markdown là một giải pháp thay thế. |
Thư mục làm việc
7 STATAThư mục làm việc bao gồm các đường dẫn tuyệt đối (Ví dụ: “C:/usename/documents/projects/data/”) |
R | =============================================================================================================================================================+ Thư mục làm việc có thể là đường dẫn tuyệt đối hoặc tương đối đến thư mục gốc của dự án bằng cách sử dụng package here (xem chương Nhập xuất dữ liệu) | |
| Xem thư mục làm việc hiện tại với pwd | Sử dụng getwd() hoặc here() (nếu sử dụng package here), với dấu ngoặc đơn trống |
|
| Cài đặt thư mục làm việc với cd “folder location” | Sử dụng setwd(“folder location”) hoặc set_here("folder location) (nếu sử dụng package here) |
Nhập và xem dữ liệu
8 STATACác lệnh cụ thể cho mỗi loại tệp |
R | =================================================================================================================================================================================================================+ Sử dụng import() từ package rio cho hầu hết tất cả các loại tệp. Các chức năng cụ thể tồn tại dưới dạng lựa chọn thay thế (xem chương Nhập xuất dữ liệu) |
|
| Đọc file csv được thực hiện bằng cách sử dụng import delimited “filename.csv” | Sử dụng import("filename.csv")
|
|
| Đọc file xslx được thực hiện bằng cách sử dụng import excel “filename.xlsx” | Sử dụng import("filename.xlsx")
|
|
| Duyệt dữ liệu của bạn trong một cửa sổ mới bằng lệnh browse | Xem bộ dữ liệu trong cửa sổ nguồn RStudio sử dụng View(dataset). Bạn cần xác định tên bộ dữ liệu của mình cho hàm trong R vì nhiều bộ dữ liệu có thể được mở cùng một lúc. Lưu ý viết hoa “V” trong hàm này
|
|
| Có cái nhìn tổng quan hơn về bộ dữ liệu của bạn bằng cách sử dụng summarize, lệnh này cung cấp tên biến và các thông tin cơ bản của bộ dữ liệu | Có cái nhìn tổng quan hơn về bộ dữ liệu của bạn bằng cách sử dụng summary(dataset)
|
Thao tác dữ liệu cơ bản
9 STATACác cột của bộ dữ liệu thường được gọi là “các biến (variables)” |
10 RThường được gọi là “các cột (columns)” hoặc thỉnh thoảng là “các véctơ (vectors)” hoặc “các biến (variables)” |
|
| Không cần xác định bộ dữ liệu | Trong mỗi lệnh dưới đây, bạn cần xác định bộ dữ liệu - xem ví dụ trong chương Làm sạch số liệu và các hàm quan trọng | |
| Các biến mới được tạo bằng lệnh generate varname = | Tạo các biến mới bằng cách sử dụng lệnh mutate(varname = ). Xem chương Làm sạch số liệu và các hàm quan trọng để biết tất cả chi tiết về câu lệnh dplyr bên dưới |
|
| Các biến được đổi tên bằng cách sử dụng rename old_name new_name | Các cột có thể được đổi tên bằng cách sử dụng lệnh rename(new_name = old_name)
|
|
| Các biến được lược bỏ sử dụng drop varname | Có thể lược bỏ các cột bằng cách sử dụng lệnh select() với tên cột trong ngoặc đơn sau dấu trừ |
|
| Các biến factor có thể được gán nhãn bằng cách sử dụng một loạt lệnh như label define | Việc gán nhãn các giá trị có thể được thực hiện bằng cách chuyển đổi cột thành nhóm Factor và chỉ định thứ bậc. Xem chương Factors. Tên cột thường không được gán nhãn như trong Stata. | |
Phân tích mô tả
11 STATAĐếm số lượng bảng của một biến sử dụng tab varname |
R | ======================================================================================================================================================================================================+ Cung cấp bộ dữ liệu và tên cột cho table() ví dụ như table(dataset$colname). Ngoài ra, có thể sử dụng lệnh count(varname) từ package dplyr, đã được giải thích trong chương Nhóm dữ liệu
|
|
| Lập bảng chéo của hai biến trong bảng 2x2 được thực hiện bằng tab varname1 varname2 | Sử dụng table(dataset$varname1, dataset$varname2 hoặc count(varname1, varname2)
|
Mặc dù danh sách này cung cấp một cái nhìn tổng quan về những điều cơ bản trong việc chuyển các lệnh Stata sang R, nhưng nó vẫn chưa đầy đủ. Bạn có thể quan tâm tới nhiều nguồn tài nguyên tuyệt vời khác dành cho người dùng Stata chuyển sang R:
11.1 Từ SAS
Chuyển từ SAS sang R
SAS thường được sử dụng tại các cơ quan y tế công cộng và các lĩnh vực nghiên cứu học thuật. Mặc dù chuyển đổi sang một ngôn ngữ mới hiếm khi là một quá trình đơn giản, nhưng hiểu được những điểm khác biệt chính giữa SAS và R có thể giúp bạn bắt đầu chuyển hướng ngôn ngữ mới bằng ngôn ngữ mẹ đẻ của mình. Dưới đây là phác thảo các bước chuyển đổi chính trong quản lý dữ liệu và phân tích mô tả giữa SAS và R.
Những lưu ý chung
12 SASCộng đồng trực tuyến có sẵn trên SAS Customer Support |
13 RCộng đồng trực tuyến có sẵn trên RStudio, StackOverFlow và R-bloggers |
|
Trợ giúp cho các lệnh có sẵn trong help [command]
|
Trợ giúp có sẵn trong [function]? hoặc tìm kiếm trong cửa sổ Help |
|
Bình luận code sử dụng * VĂN BẢN ; hoặc /* VĂN BẢN */
|
Bình luận code sử dụng # | |
Hầu hết tất cả các lệnh đều được tích hợp sẵn. Người dùng có thể viết lệnh mới bằng cách sử dụng SAS macro, SAS/IML, SAS Component Language (SCL) và mới đây nhất là, được thực hiện bằng Proc Fcmp và Proc Proto
|
R được cài đặt sẵn các lệnh **cơ bản**, nhưng quá trình sử dụng thông thường cần cài đặt các package khác từ CRAN (xem chương R cơ bản) | |
| Phân tích thường được viết trong chương trình SAS ở cửa sổ Editor. | Phân tích được viết trong R script trong cửa sổ chính của RStudio. Các script của R markdown là một giải pháp thay thế. |
Thư mục làm việc
14 SASThư mục làm việc có thể là đường dẫn tuyệt đối hoặc tương đối đến thư mục gốc của dự án bằng cách sử dụng |
R | =============================================================================================================================================================+ Thư mục làm việc có thể là đường dẫn tuyệt đối hoặc tương đối đến thư mục gốc của dự án bằng cách sử dụng package here (xem chương Nhập xuất dữ liệu) | |
Xem thư mục làm việc hiện tại với %put %sysfunc(getoption(work));
|
Sử dụng getwd() hoặc here() (nếu sử dụng package here), với dấu ngoặc đơn trống |
|
Cài đặt thư mục làm việc với libname “folder location”
|
Sử dụng setwd(“folder location”) hoặc set_here("folder location) (nếu sử dụng package here) |
Nhập và xem dữ liệu
15 SASSử dụng lệnh |
R | =============================================================================================================================================================================================================+ Sử dụng import() từ package rio cho hầu hết tất cả các loại tệp. Các chức năng cụ thể tồn tại dưới dạng lựa chọn thay thế (xem chương Nhập xuất dữ liệu) |
|
Đọc file csv được thực hiện bằng cách sử dụng Proc Import datafile=”filename.csv” out=work.filename dbms=CSV; run; HOẶC sử dụng Data Step Infile statement
|
Sử dụng import("filename.csv")
|
|
Đọc các tệp xslx được thực hiện bằng cách sử dụng Proc Import datafile=”filename.xlsx” out=work.filename dbms=xlsx; run; HOẶC sử dụng Data Step Infile statement
|
Sử dụng import("filename.xlsx")
|
|
| Duyệt bộ dữ liệu của bạn trong cửa sổ mới bằng cách mở cửa sổ Explorer và chọn thư viện và tập dữ liệu mong muốn. | Xem bộ dữ liệu trong cửa sổ nguồn RStudio sử dụng View(dataset). Bạn cần xác định tên bộ dữ liệu của mình cho hàm trong R vì nhiều bộ dữ liệu có thể được mở cùng một lúc. Lưu ý viết hóa “V” trong hàm này | |
Thao tác dữ liệu cơ bản
16 SASCác cột của bộ dữ liệu thường được gọi là “các biến (variables)” |
17 RThường được gọi là “các cột (columns)” hoặc thỉnh thoảng là “các véctơ (vectors)” hoặc “các biến (variables)” |
|
| Không cần thao tác đặc biệt để tạo ra một biến. Các biến mới được tạo đơn giản bằng cách nhập tên biến mới, theo sau là dấu bằng, sau đó là biểu thức cho giá trị | Tạo các biến mới bằng cách sử dụng hàm mutate(varname = ). Xem chương Làm sạch số liệu và các hàm quan trọng để biết tất cả chi tiết về câu lệnh dplyr bên dưới |
|
Các biến được đổi tên bằng cách sử dụng rename *old_name=new_name*
|
Các cột có thể được đổi tên bằng cách sử dụng ệnh rename(new_name = old_name)
|
|
Các biến được giữ bằng cách sử dụng **keep**=varname
|
Các cột có thể được chọn bằng cách sử dụng lệnh select() với tên cột trong ngoặc đơn |
|
Các biến được lược bỏ sử dụng **drop**=varname
|
Có thể lược bỏ các cột bằng cách sử dụng lệnh select() với tên cột trong ngoặc đơn sau dấu trừ |
|
Các biến Factor có thể được gán nhãn trong Data Step bằng cách sử dụng lệnh Label
|
Việc gán nhãn các giá trị có thể được thực hiện bằng cách chuyển đổi cột thành nhóm Factor và chỉ định thứ bậc. Xem chương Factors. Tên cột thường không được gán nhãn. | | |
Các bản ghi được chọn bằng cách sử dụng lệnh Where hoặc If trong Data Step. Nhiều điều kiện lựa chọn được phân tách bằng lệnh “and”. |
Các bản ghi được chọn bằng cách sử dụng lệnh filter() với nhiều điều kiện lựa chọn được phân tách bằng toán tử AND (&) hoặc dấu phẩy |
|
Bộ dữ liệu được hợp nhất bằng cách sử dụng lệnh Merge trong Data Step. Các bộ dữ liệu được hợp nhất cần phải được sắp xếp trước bằng cách sử dụng thao tác Proc Sort. |
Package dplyr cung cấp một số chức năng để hợp nhất các tập dữ liệu. Xem chi tiết trong chương [Nối dữ liệu]. |
Phân tích mô tả
18 SASCó cái nhìn tổng quan hơn về bộ dữ liệu của bạn bằng cách sử dụng thao tác |
19 RCó cái nhìn tổng quan hơn về bộ dữ liệu của bạn bằng cách sử dụng |
|
Đếm số lượng bảng của một biến sử dụng proc freq data=Dataset; Tables varname; Run;
|
Xem chương Bảng mô tả. Các tùy chọn trong số tất cả các tùy chọn khác bao gồm table() từ base R và tabyl() từ package janitor. Lưu ý rằng bạn sẽ cần xác định bộ dữ liệu và tên cột vì R chứa nhiều tập dữ liệu. | |
|
Lập bảng chéo của hai biến trong bảng 2x2 được thực hiện bằng proc freq data=Dataset; Tables rowvar*colvar; Run;
|
Một lần nữa, bạn có thể sử dụng table(), tabyl() hoặc những cách khác đã được mô tả trong chương Bảng mô tả. |
Một số tài nguyên hữu ích:
19.1 Khả năng tương tác dữ liệu
Xem chương Nhập xuất dữ liệu để biết chi tiết về cách R package rio có thể nhập và xuất các file như file STATA .dta, file SAS .xpt và .sas7bdat, file SPSS .por và .sav và nhiều file khác.