32 流行曲線(エピカーブ)
流行曲線(「エピカーブ」とも呼ばれる)は、流行集団(クラスター)における疾病の発症の時間的パターンを可視化するための基本的な疫学グラフです。
流行曲線を分析することで、時間的な傾向、異常値、アウトブレイクの規模、曝露の可能性が最も高い時期、症例の世代間の時間間隔などが明らかになり、さらには未知の新しい疾患の伝播様式(点源、継続的な共通感染源、人から人への伝播など)を特定するのにも役立ちます。流行曲線の解釈に関するオンライン上の資料の 1 つとして、米国疾病予防管理センター(Centers for Disease Control and Prevention; CDC)の 公式ウェブサイト があります。
In this page we demonstrate making epidemic curves with the ggplot2 package, which allows for advanced customizability.
また、以下のような具体的な使用例も紹介します。
- 集計データのプロット
- ファセット化(小さなグラフを複数作成する)
- 移動平均の適用
- 報告が遅れている「暫定」データの表示
- 累積症例数を第 2 軸で重ね合わせたプロット
The incidence2 package offers alternative approach with easier commands, but as of this writing was undergoing revisions and was not stable. It will be re-added to this chapter when stable.
32.1 準備
パッケージの読み込み
解析に必要な標準パッケージを読み込みます。 このハンドブックでは、パッケージを読み込むために、pacman パッケージの p_load() を主に使用しています。p_load() は、必要に応じてパッケージをインストールし、現在の R セッションで使用するためにパッケージを読み込む関数です。また、すでにインストールされたパッケージは、R の基本パッケージである base の library() を使用して読み込むこともできます。R パッケージについての詳細は、R の基礎 の章を参照してください。
pacman::p_load(
rio, # file import/export
here, # relative filepaths
lubridate, # working with dates/epiweeks
aweek, # alternative package for working with dates/epiweeks
incidence2, # epicurves of linelist data
i2extras, # supplement to incidence2
stringr, # search and manipulate character strings
forcats, # working with factors
RColorBrewer, # Color palettes from colorbrewer2.org
tidyverse # data management + ggplot2 graphics
) 32.1.1 データのインポート
この章では2つのデータセットを使用します。
- 流行のシミュレーションデータから作成された症例ごとのデータ(ラインリスト)
- 同じ流行のシミュレーションデータから作成された病院ごとの症例数の集計値
データセットは、rio パッケージの import() を使ってインポートします。データをインポートする様々な方法については、データのインポート・エクスポート の章を参照してください。
ラインリスト(linelist)
エボラ出血熱の流行をシミュレートしたデータセットをインポートします。この章の内容をお手元の環境で実行したい方は、ハンドブックとデータのダウンロード の章をご覧ください。ファイルが作業ディレクトリにある場合、ファイルパスにはファイル名のみ指定します。
linelist <- import("linelist_cleaned.rds") 以下に、最初の 50 行を表示します。
病院ごとの症例数
以下のコードで、病院ごとの週別の集計数を含んだデータセットを linelist から作成します。
# 集計データをRにインポート
count_data <- linelist %>%
group_by(hospital, date_hospitalisation) %>%
summarize(n_cases = dplyr::n()) %>%
filter(date_hospitalisation > as.Date("2013-06-01")) %>%
ungroup()以下に、最初の 50 行を表示します。
パラメータの設定
レポートを作成する際に、データの現在の日付(「データ日」)を設定することができます。data_date オブジェクトにデータ日を定義することで、データセットをフィルタリングする際や脚注を書く際に用いることができます。
## レポート用に日付を設定
## メモ:Sys.Date()でも最新の日付を設定することができます
## note: can be set to Sys.Date() for the current date
data_date <- as.Date("2015-05-15")日付の確認
各日付列のデータ型が日付型であることを確信し、また、適切な範囲であるかを確認します。欠損値を除外( na.rm=TRUE )した上で range() を用いて範囲を確認することができますし、 ヒストグラムで確認する場合は hist() あるいは以下のように ggplot() を使って簡単に行うこともできます。
# 発症日の範囲を確認
ggplot(data = linelist)+
geom_histogram(aes(x = date_onset))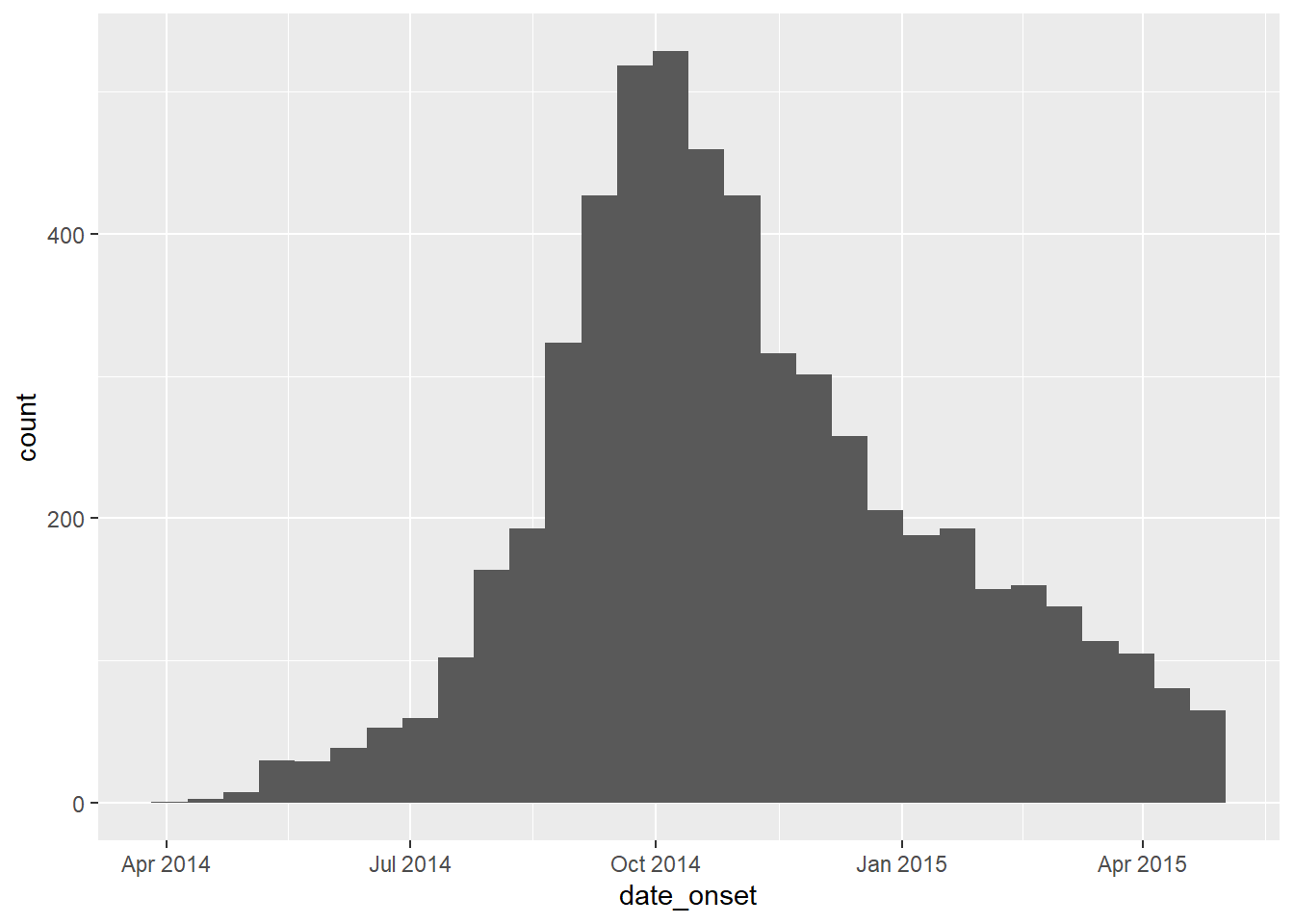
32.2 ggplot2 を用いた流行曲線
ggplot() を使用して流行曲線を作成すると、より柔軟にカスタマイズできますが、多くの手順と ggplot() の動作の理解が必要です。
症例の集計単位(週、月など)や日付軸のラベルの間隔を、_手動で_注意して制御する必要があります。
以下の例では、linelist データセットの一部(Central Hospital の症例のみ)を使用しています。
central_data <- linelist %>%
filter(hospital == "Central Hospital")ggplot() を使用した流行曲線の作成は、以下の 3 つの要素に分かれます。
- ラインリストの症例を、特定の「分割」ポイントで区別される「ビン」に集約したヒストグラム
- 軸のスケールとそのラベル
- タイトル、ラベル、キャプションなど、グラフの見た目に関するテーマ
症例のビンの指定
ここでは、症例をヒストグラムのビン(「バー」とも呼ばれる)に集約する方法を説明します。ここで重要なのは、ヒストグラムのビンへの症例の集約は、必ずしも x 軸に表示される日付と同じ間隔ではないということです。
以下は、日次と週次の流行曲線を作成するための最も簡単なコードです。
ggplot() コマンドでは、データセットを data = で指定します。 この土台の上に、ヒストグラムの形状を + で追加します。geom_histogram() では、date_onset 列が x 軸にマッピングされるように指定します。また、geom_histogram() 内では、aes() 内ではなく、ヒストグラムの binwidth = を日単位で設定します。この ggplot2 の構文が分かりにくい場合は、ggplot の基礎 の章を参照して下さい。
注意:binwidth = 7 を使って週別の症例数をプロットすると、7日間の最初のビンは、最初の症例で開始されます。特定の週を作成するには、以下のセクションを参照してください。
# daily
ggplot(data = central_data) + # データセットの指定
geom_histogram( # ヒストグラムの追加
mapping = aes(x = date_onset), # 日付列をx軸に指定
binwidth = 1)+ # 1日ごとのビンを指定
labs(title = "Central Hospital - Daily") # タイトル
# weekly
ggplot(data = central_data) + # データセットの指定
geom_histogram( # ヒストグラムの追加
mapping = aes(x = date_onset), # 日付列をx軸に指定
binwidth = 7)+ # 7日ごとのビンを指定、最初の症例から始まる(!)
labs(title = "Central Hospital - 7-day bins, starting at first case") # タイトル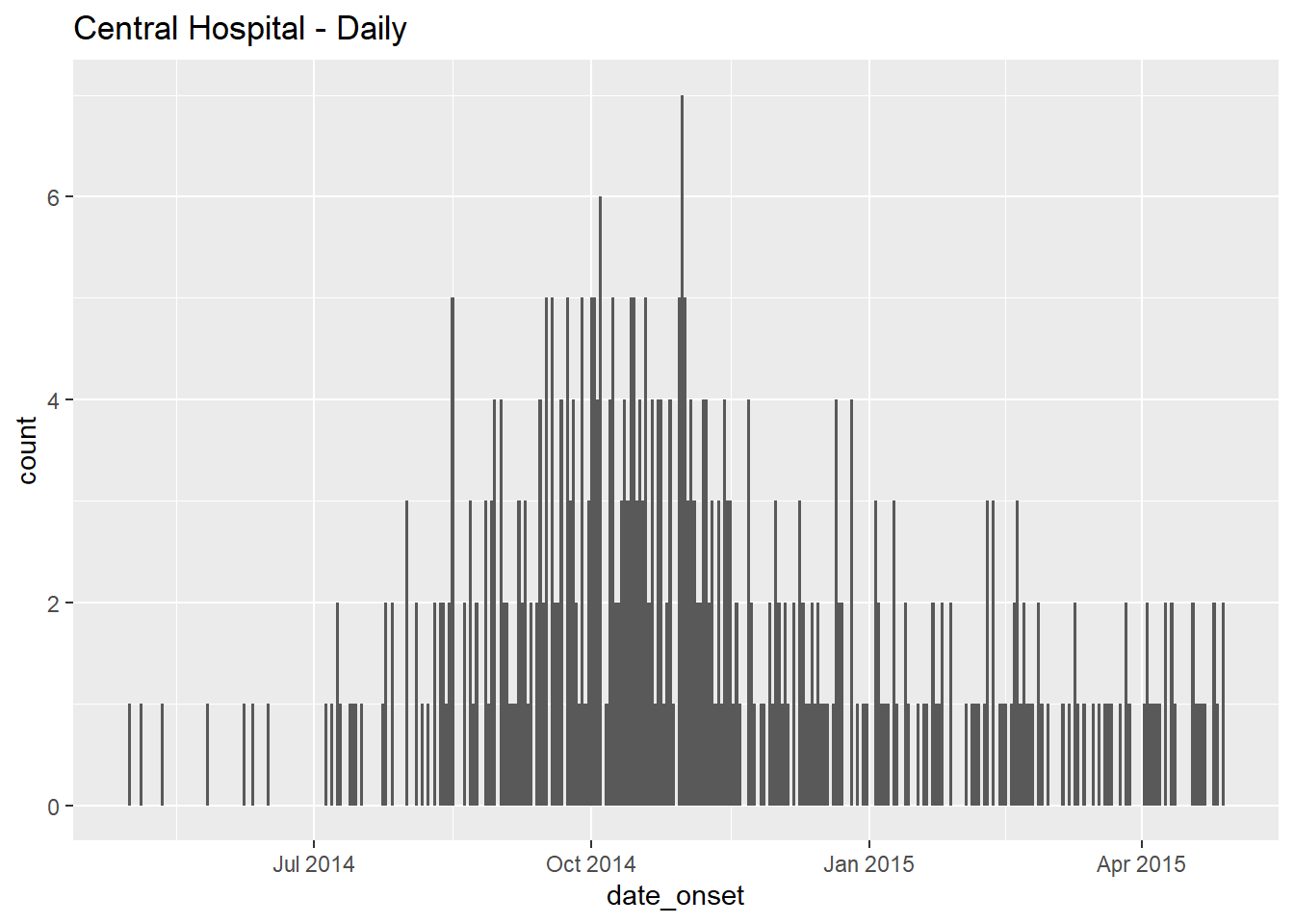
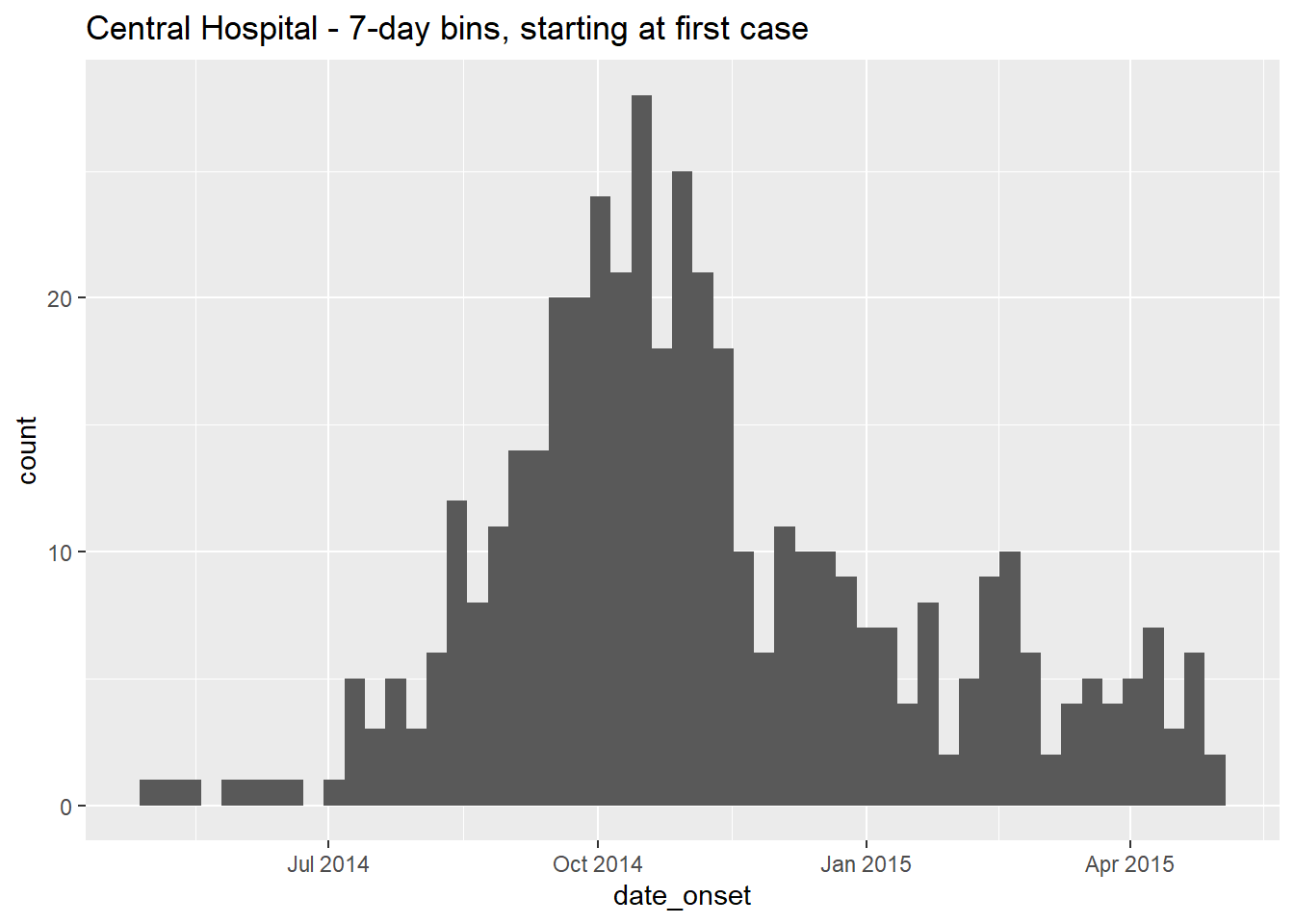
この Central Hospital のデータセットの最初の症例は、症状が出たのが 1 日目だったことに注目しましょう。
format(min(central_data$date_onset, na.rm=T), "%A %d %b, %Y")[1] "Thursday 01 May, 2014"ヒストグラムのビンの区切りをマニュアルで指定するには、binwidth = を使用せず、代わりに breaks = に日付のベクトルを指定します。
日付のベクトルは、R base の seq.Date() で作成します。この関数は、開始日 from = 、終了日 to = と日単位 by = を引数に取ります。例えば、以下のコマンドは、1 月 15 日から 6 月 28 日までの月ごとの日付を返します。
monthly_breaks <- seq.Date(from = as.Date("2014-02-01"),
to = as.Date("2015-07-15"),
by = "months")
monthly_breaks # 表示 [1] "2014-02-01" "2014-03-01" "2014-04-01" "2014-05-01" "2014-06-01"
[6] "2014-07-01" "2014-08-01" "2014-09-01" "2014-10-01" "2014-11-01"
[11] "2014-12-01" "2015-01-01" "2015-02-01" "2015-03-01" "2015-04-01"
[16] "2015-05-01" "2015-06-01" "2015-07-01"このベクトルは、geom_histogram() に breaks = として与えることができます。
# 月ごと
ggplot(data = central_data) +
geom_histogram(
mapping = aes(x = date_onset),
breaks = monthly_breaks)+ # 上で定義した日付ベクトルを指定 vector of breaks
labs(title = "Monthly case bins") # タイトル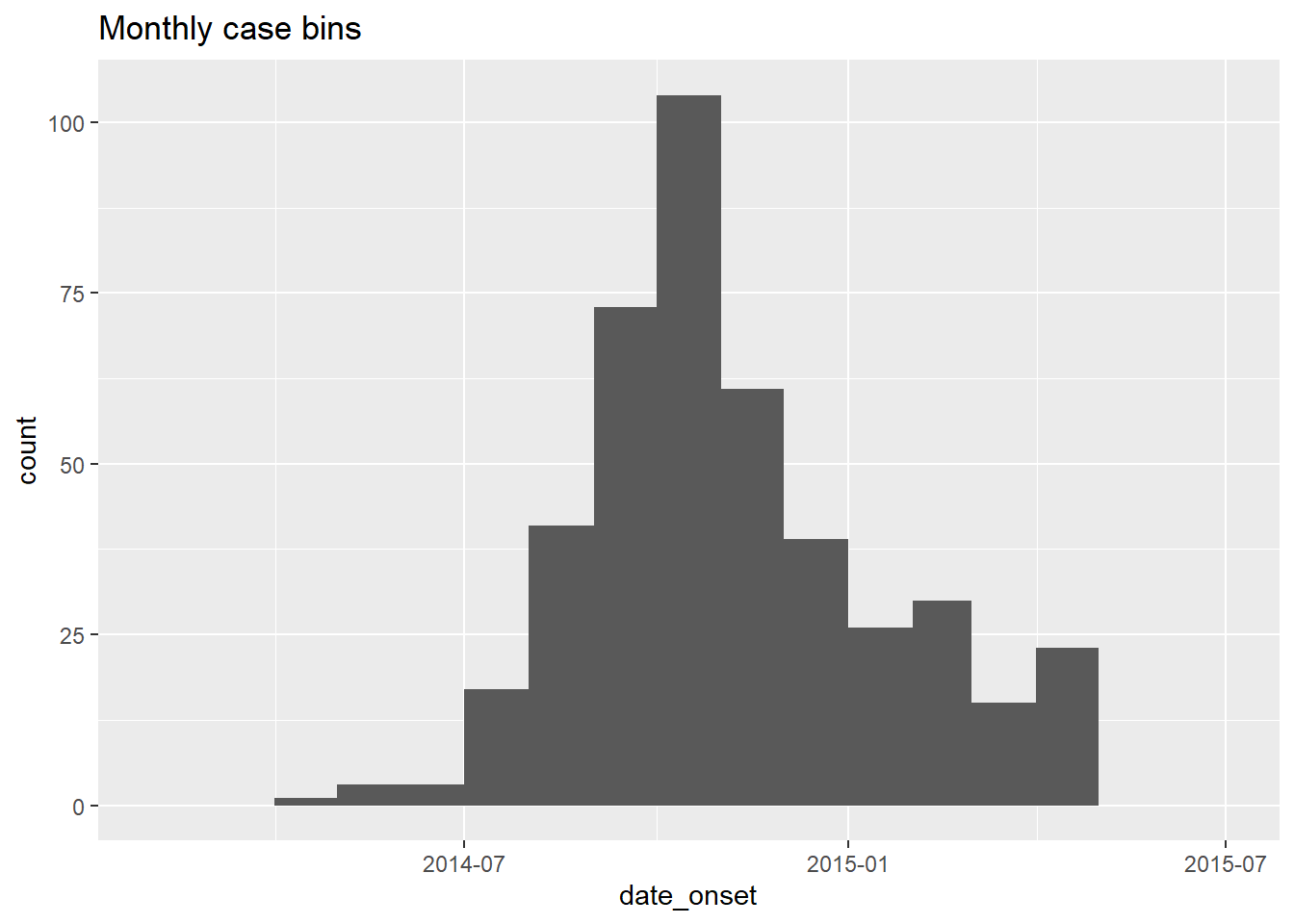
by = "week" を設定すると、単純な週単位の日付列を返すことができます。以下はその一例です。
weekly_breaks <- seq.Date(from = as.Date("2014-02-01"),
to = as.Date("2015-07-15"),
by = "week")また、開始日と終了日を指定する代わりに、週単位のビンが最初の症例の前の月曜日から始まるようにコードを書くこともできます。以下の例では、これらの日付ベクトルを使用します。
# CENTRAL HOSPITAL データにおける月曜日だけを含んだ日付ベクトル
weekly_breaks_central <- seq.Date(
from = floor_date(min(central_data$date_onset, na.rm=T), "week", week_start = 1), # 最初の症例以前の月曜日の日付
to = ceiling_date(max(central_data$date_onset, na.rm=T), "week", week_start = 1), # 最後の症例以後の月曜日の日付
by = "week")上に書かれている少し複雑なコードを紐解いてみましょう。
-
「from」の数値(日付ベクトルの最初の日付)は以下のようにして設定されます。
-
lubridate パッケージの
floor_date()にdate_onset列の最少の値(na.rm=TRUEで欠損値を除外したmin()で得られる値)を渡します。この時にfloor_date()に「week」を指定すると、各週の開始日が月曜日 (week_start = 1) であるとした場合に、その症例の 「week」 の開始日が返されます。
-
lubridate パッケージの
同様に、「to 」の数値(日付ベクトルの最後の日付)は、逆の関数である
ceiling_date()を用いて、最後の症例の翌月曜日を返すように作成されます。seq.Date()の引数 by には、日、週、月の任意の数を指定することができます。week_start = 7を使用することで日曜から開始される週にすることができます。
これらの日付ベクトルは本章全体で使用するため、全体のデータに対するものも以下で定義しておきます(上記は Central Hospital のみ)。
# 全体のデータにおける日付ベクトルの作成
weekly_breaks_all <- seq.Date(
from = floor_date(min(linelist$date_onset, na.rm=T), "week", week_start = 1), # 最初の症例以前の月曜日の日付
to = ceiling_date(max(linelist$date_onset, na.rm=T), "week", week_start = 1), # 最後の症例以後の月曜日の日付
by = "week")これらの seq.Date() の出力は、ヒストグラムのビンの区切りだけでなく、ビンから独立した日付ラベルの区切りを作成するためにも使用できます。日付ラベルについては、後のセクションで詳しく説明します。
ヒント:bin breaks と date label breaks をあらかじめ名前付きのベクトルとして保存しておき、breaks = にそのベクトルを指定することで、よりシンプルな ggplot() コマンドにすることができます。
週別流行曲線の例
以下は日付ラベル、縦罫線を含んだ、月曜始まりの週別流行曲線を作成するための詳細なサンプルコードです。このセクションは、すぐにコードを必要とするユーザーのためのものです。それぞれの側面(テーマ、日付ラベルなど)を深く理解するためには、以降のセクションを参照して下さい。注目すべき点として以下があります。
- ヒストグラムのビンの区切りは、上で説明したように
seq.Date()で定義され、最も早い症例の前の月曜日から始まり、最後の症例の後の月曜日で終わります。
- 日付ラベルの間隔は
scale_x_date()の中のdate_breaks =で指定します。
- 日付ラベルの間の縦罫線の間隔は
date_minor_breaks =で指定します。
- 日付ラベルが正しいビンにカウントされているか確認するため
geom_histogram()のclosed = "left"オプションを指定します。 - x軸とy軸のスケールで
expand = c(0,0)を使用すると、軸の両側の余分なスペースがなくなり、日付ラベルが最初のバーから始まるようにできます。
# 月曜日ごとの集計
#############################
# 週ごとの日付ベクトルの作成
weekly_breaks_central <- seq.Date(
from = floor_date(min(central_data$date_onset, na.rm=T), "week", week_start = 1), # 最初の症例以前の月曜日の日付
to = ceiling_date(max(central_data$date_onset, na.rm=T), "week", week_start = 1), # 最後の症例以後の月曜日の日付
by = "week") # 7日間隔に指定
ggplot(data = central_data) +
# ヒストグラムの作成:ビンの分割数の指定:最初の症例の前の月曜日から始まり、最後の症例の後の月曜日を終了する
geom_histogram(
# マッピング
mapping = aes(x = date_onset), # 日付列をx軸にマッピング
# ビンの分割指定
breaks = weekly_breaks_central, # 上で定義したビンの分割
closed = "left", # 分割の開始から症例数をカウントする
# bars
color = "darkblue", # 枠線の色指定
fill = "lightblue" # 棒グラフの色の指定
)+
# x軸ラベル
scale_x_date(
expand = c(0,0), # X軸の前後の余分なスペースを削除
date_breaks = "4 weeks", # 日付ラベルと主要な縦罫線を4週ごとに表示。
date_minor_breaks = "week", # 小縦罫線を1週ごとに表示
date_labels = "%a\n%d %b\n%Y")+ # 日付ラベルのフォーマット
# y-axis
scale_y_continuous(
expand = c(0,0))+ # y軸の前後の余分なスペースを削除
# テーマの指定
theme_minimal()+ # 背景を簡潔なものに指定
theme(
plot.caption = element_text(hjust = 0, # 脚注を左寄せに配置
face = "italic"), # キャプションをイタリック体に指定
axis.title = element_text(face = "bold"))+ # 軸タイトルを太字に指定
# 脚注を含んだラベル
labs(
title = "Weekly incidence of cases (Monday weeks)",
subtitle = "Note alignment of bars, vertical gridlines, and axis labels on Monday weeks",
x = "Week of symptom onset",
y = "Weekly incident cases reported",
caption = stringr::str_glue("n = {nrow(central_data)} from Central Hospital; Case onsets range from {format(min(central_data$date_onset, na.rm=T), format = '%a %d %b %Y')} to {format(max(central_data$date_onset, na.rm=T), format = '%a %d %b %Y')}\n{nrow(central_data %>% filter(is.na(date_onset)))} cases missing date of onset and not shown"))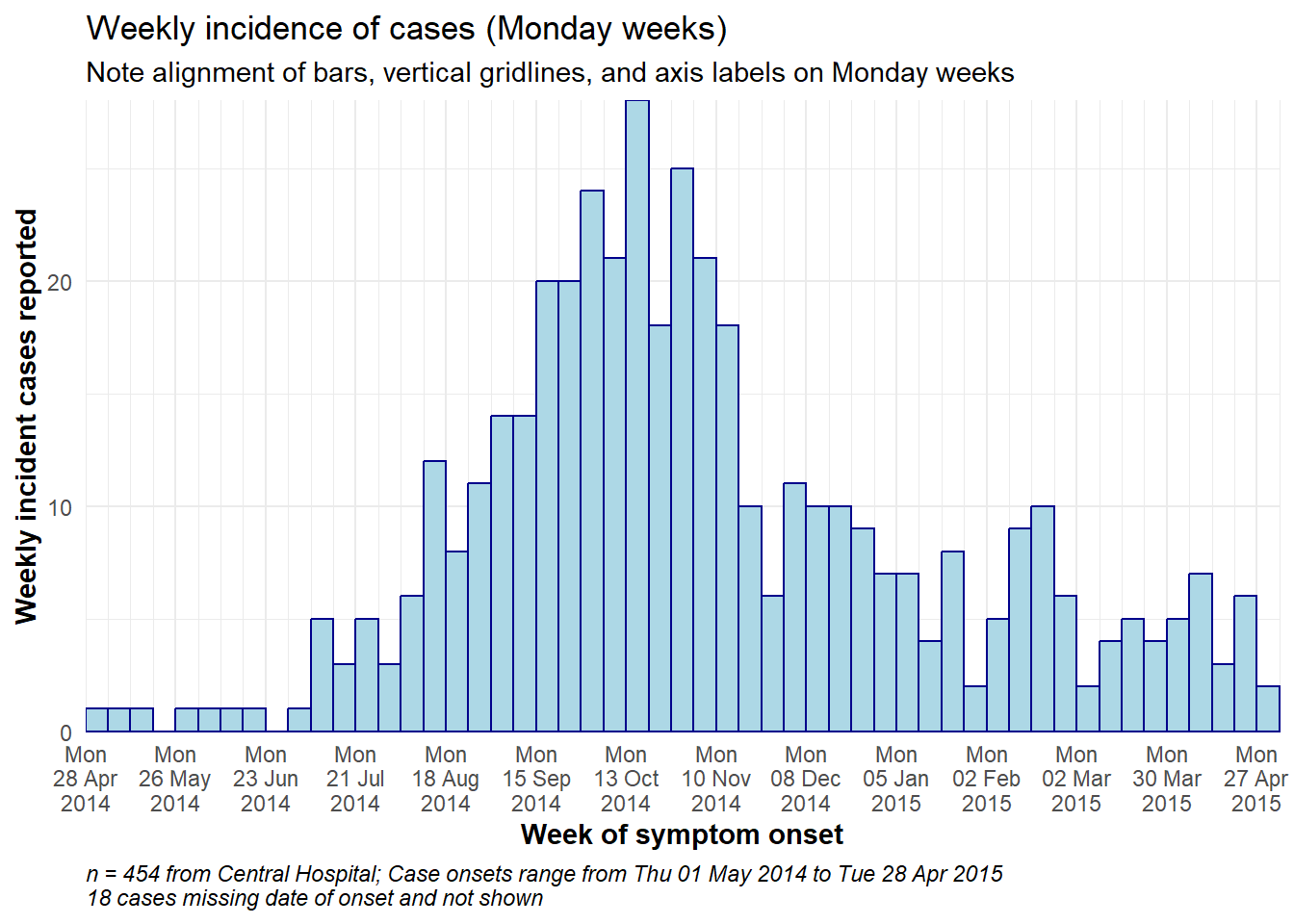
日曜始まりの週
date_breaks = "weeks" は月曜始まりの週に対してのみ機能するため、日曜始まりの週に対して上記の可視化を行うには、いくつかの修正が必要です。
- ヒストグラムビンの分割点を日曜日に設定する必要があります (
week_start = 7)。
-
scale_x_date()内で、日付ラベルと縦罫線が日曜日に揃うように、breaks =とminor_breaks =に同様の日付の分割点を設定する必要があります。
例えば、日曜始まりの週に対する scale_x_date() コマンドは、以下のようになります。
scale_x_date(
expand = c(0,0),
# 日付ラベルと縦罫線の間隔を指定
breaks = seq.Date(
from = floor_date(min(central_data$date_onset, na.rm=T), "week", week_start = 7), # 最初の症例以前の月曜日の日付
to = ceiling_date(max(central_data$date_onset, na.rm=T), "week", week_start = 7), # 最後の症例以後の月曜日の日付
by = "4 weeks"),
# 小縦罫線の間隔を指定
minor_breaks = seq.Date(
from = floor_date(min(central_data$date_onset, na.rm=T), "week", week_start = 7), # 最初の症例以前の月曜日の日付
to = ceiling_date(max(central_data$date_onset, na.rm=T), "week", week_start = 7), # 最後の症例以後の月曜日の日付
by = "week"),
# 日付ラベルのフォーマット
#date_labels = "%a\n%d %b\n%Y")+ # 曜日+日付と省略月名と年
label = scales::label_date_short()) # automatic label formattingグループ化・値による色分け
ヒストグラムのビンは、グループごとに色分けして積み重ねることができます。グループ化する列を指定するには、以下の変更を行います。詳しくは、ggplot の基礎 の章を参照してください。
-
aes()内で、列名をgroup =とfill =の引数に指定します。
-
aes()の外側にあるfill =の引数は、内側の引数を上書きするので削除してください。
-
aes()の内側の引数はグループごとに適用されますが、外側の引数はすべてのビンに適用されます (例えば、外側のcolor =で色を指定して、各ビンの枠線を同じ色で表示することができます)。
以下は、aes() コマンドでヒストグラムのビンを性別でグループ化、色分けする場合のコード例です。
aes(x = date_onset, group = gender, fill = gender)以下で適用してみます。
ggplot(data = linelist) + # データセットの指定(全病院データ)
# ヒストグラムの作成: ビンの分割点の指定、 最初の症例の前の月曜日から始まり、最後の症例の次の月曜日で終わるように設定する
geom_histogram(
mapping = aes(
x = date_onset,
group = hospital, # hospital でグループ化する
fill = hospital), # hospital 毎に棒グラフを色分けする
# ビン分割を月曜始まりの週ごとにする
breaks = weekly_breaks_all, # 上のコードで定義済みの全症例に対する月曜始まりの週毎に分割する
closed = "left", # 分割の開始から症例数をカウントする
# 枠線の色の指定
color = "black")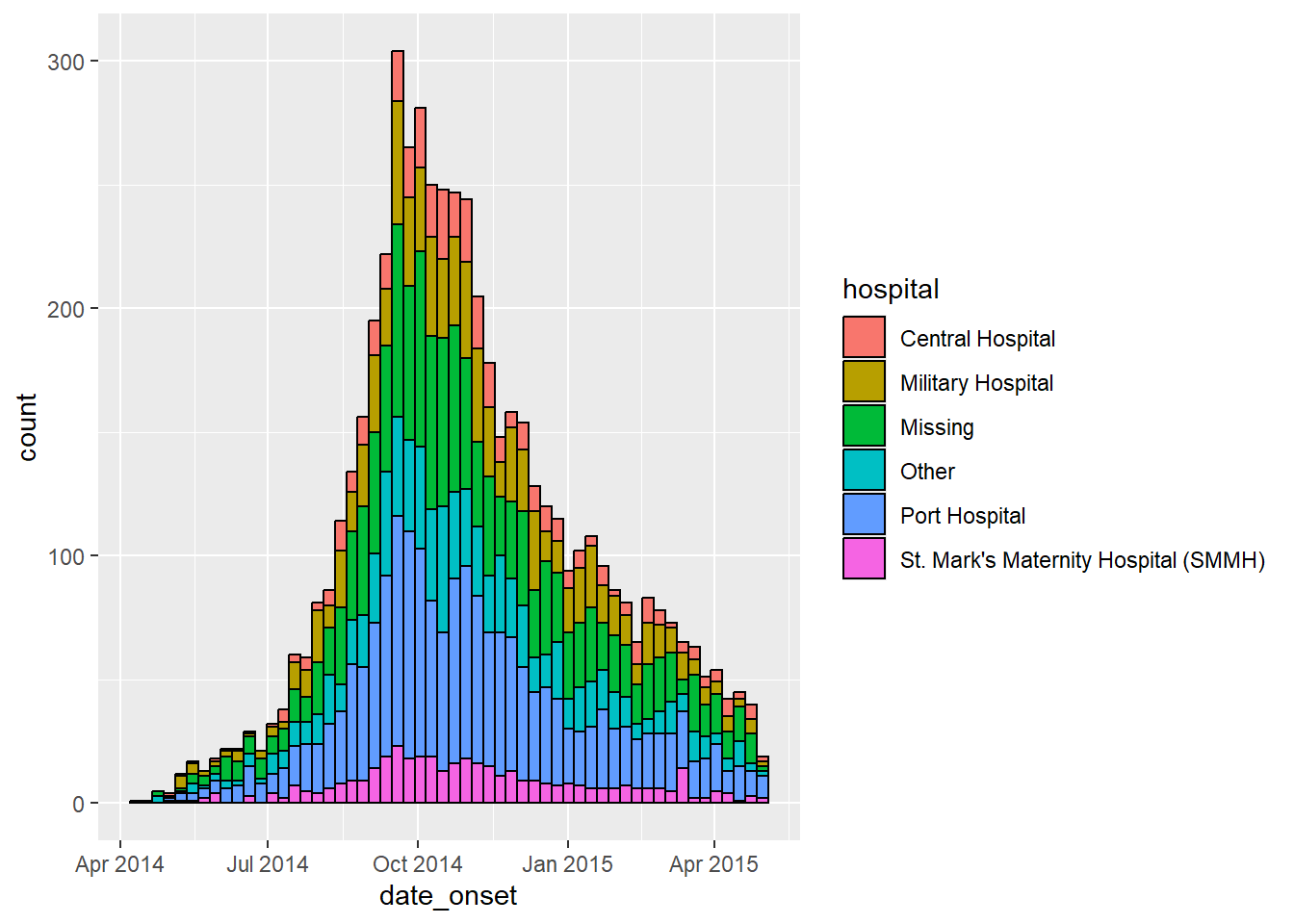
色の調整
-
各グループの色分けをマニュアルで設定するには、
scale_fill_manual()を使用します(scale_color_manual()とは別の関数であることに注意してください!)。色のベクトルを適用するには、
values =引数を使用します。欠損値の色を指定するには、
na.value =を使用します。labels =引数を使用して、凡例の項目名を変更します。念の為に、c("old" = "new", "old" = "new")のような名前付きベクトルとして指定するか、データ自体の値を調節してください。凡例のタイトルを指定するためには、
name =を使用します。
色やパレットに関する詳しい情報は、ggplot の基礎 の章を参照してください。
ggplot(data = linelist)+ # データセットの指定(全病院データ)
# ヒストグラムの作成
geom_histogram(
mapping = aes(x = date_onset,
group = hospital, # hospital でグループ化する
fill = hospital), # hospital 毎に棒グラフを色分けする
# ビン分割
breaks = weekly_breaks_all, # 上のコードで定義済みの全症例に対する月曜始まりの週毎に分割する
closed = "left", # 分割の開始から症例数をカウントする
# 枠線の色の指定
color = "black")+ # 枠線の色の指定
# マニュアルでの色の指定
scale_fill_manual(
values = c("black", "orange", "grey", "beige", "blue", "brown"),
labels = c("St. Mark's Maternity Hospital (SMMH)" = "St. Mark's"),
name = "Hospital") # 色の指定 - 順番に注意!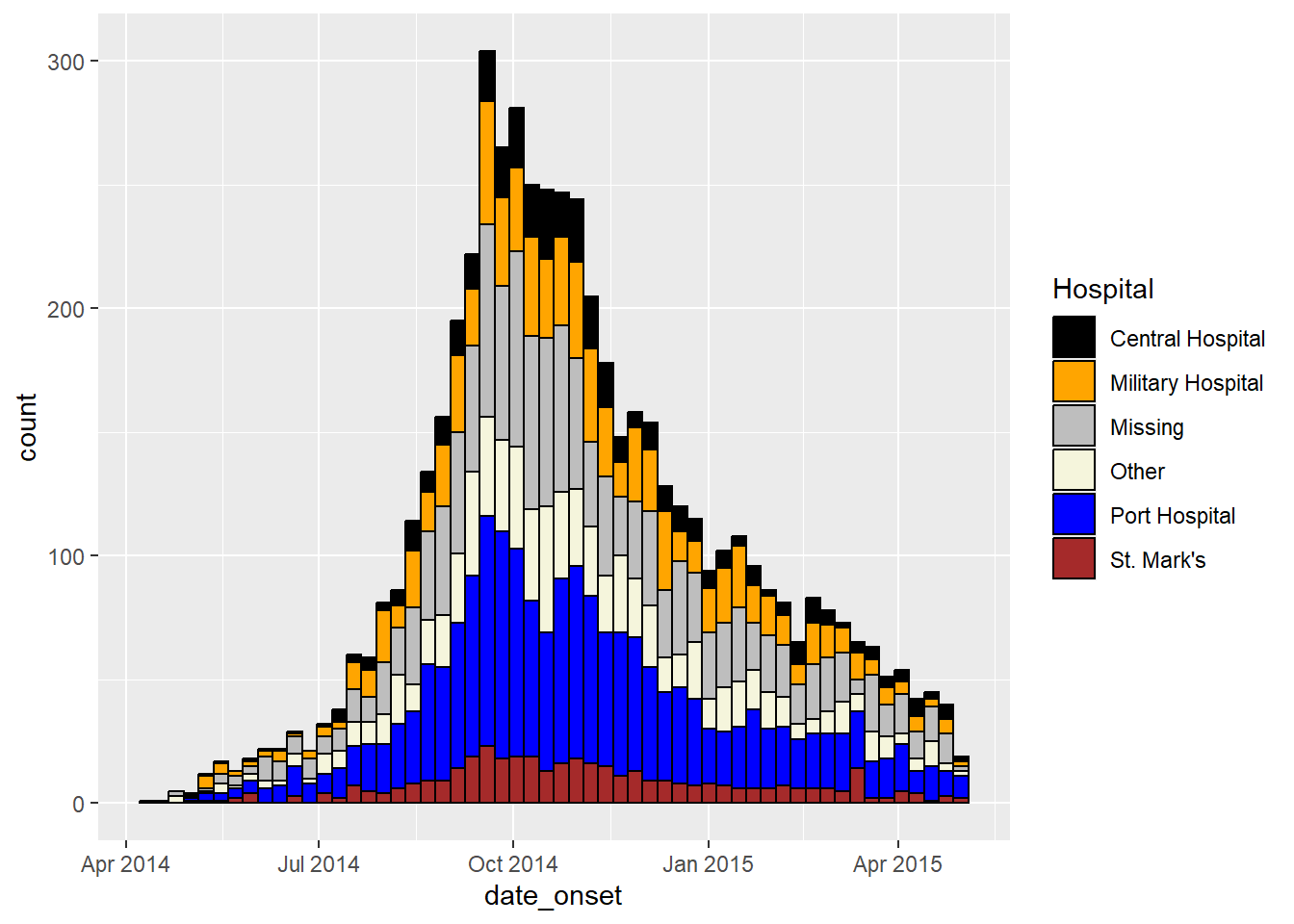
レベル順の調整
グループ化されたヒストグラムの積み重ねの順番は、グループ化された列を因子型にし、各因子のレベルの順番(とその表示ラベル)を指定することで調整します。詳しくは、因子(ファクタ)型データ の章、または、ggplot の基礎 の章をご覧ください。
因子(ファクタ)型データ の章で説明されているように、グラフを作成する前に forcats パッケージの fct_relevel() 関数を使用し、グループ化したい列を因子型に変換してレベル順をマニュアルで調整してください。
# forcats パッケージの読み込み
pacman::p_load(forcats)
# hospital をfactor 型としてデータセットを定義する
plot_data <- linelist %>%
mutate(hospital = fct_relevel(hospital, c("Missing", "Other"))) # factor 型に変換した後に"Missing"と"Other" 列が棒グラフの上に来るようにレベル順を調整する
levels(plot_data$hospital) # レベル順を表示する[1] "Missing"
[2] "Other"
[3] "Central Hospital"
[4] "Military Hospital"
[5] "Port Hospital"
[6] "St. Mark's Maternity Hospital (SMMH)"以下の例では、hospital 列を上記のように統合した上で凡例の順番を guides() 関数を用いて逆にして、“Missing” が凡例の一番下に来るように変更しています。
ggplot(plot_data) + # レベル順を変更した新しい hospital を使用する
# ヒストグラムの作成
geom_histogram(
mapping = aes(x = date_onset,
group = hospital, # hospital でグループ化する
fill = hospital), # hospital 毎に棒グラフを色分けする
breaks = weekly_breaks_all, # 以前のコードで定義済みの全症例に対する月曜始まりの週毎に分割する
closed = "left", # 分割の開始から症例数をカウントする
color = "black")+ # 枠線の色の指定
# x軸のラベル
scale_x_date(
expand = c(0,0), # X軸の前後の余分なスペースを削除
date_breaks = "3 weeks", # データを3週ごとに表示
date_minor_breaks = "week", # 縦縦罫線を1週ごとに表示
label = scales::label_date_short())+ # 日付ラベルのフォーマット
# y軸のラベル
scale_y_continuous(
expand = c(0,0))+ # y軸の前後の余分なスペースを削除
# 手動での色の指定、順番に注意!
scale_fill_manual(
values = c("grey", "beige", "black", "orange", "blue", "brown"),
labels = c("St. Mark's Maternity Hospital (SMMH)" = "St. Mark's"),
name = "Hospital")+
# 外観の変更
theme_minimal()+ # 背景を簡潔なものに指定
theme(
plot.caption = element_text(face = "italic", # 脚注をイタリック体にして左に幅寄せ
hjust = 0),
axis.title = element_text(face = "bold"))+ # 軸タイトルを太字に
# ラベルの指定
labs(
title = "Weekly incidence of cases by hospital",
subtitle = "Hospital as re-ordered factor",
x = "Week of symptom onset",
y = "Weekly cases")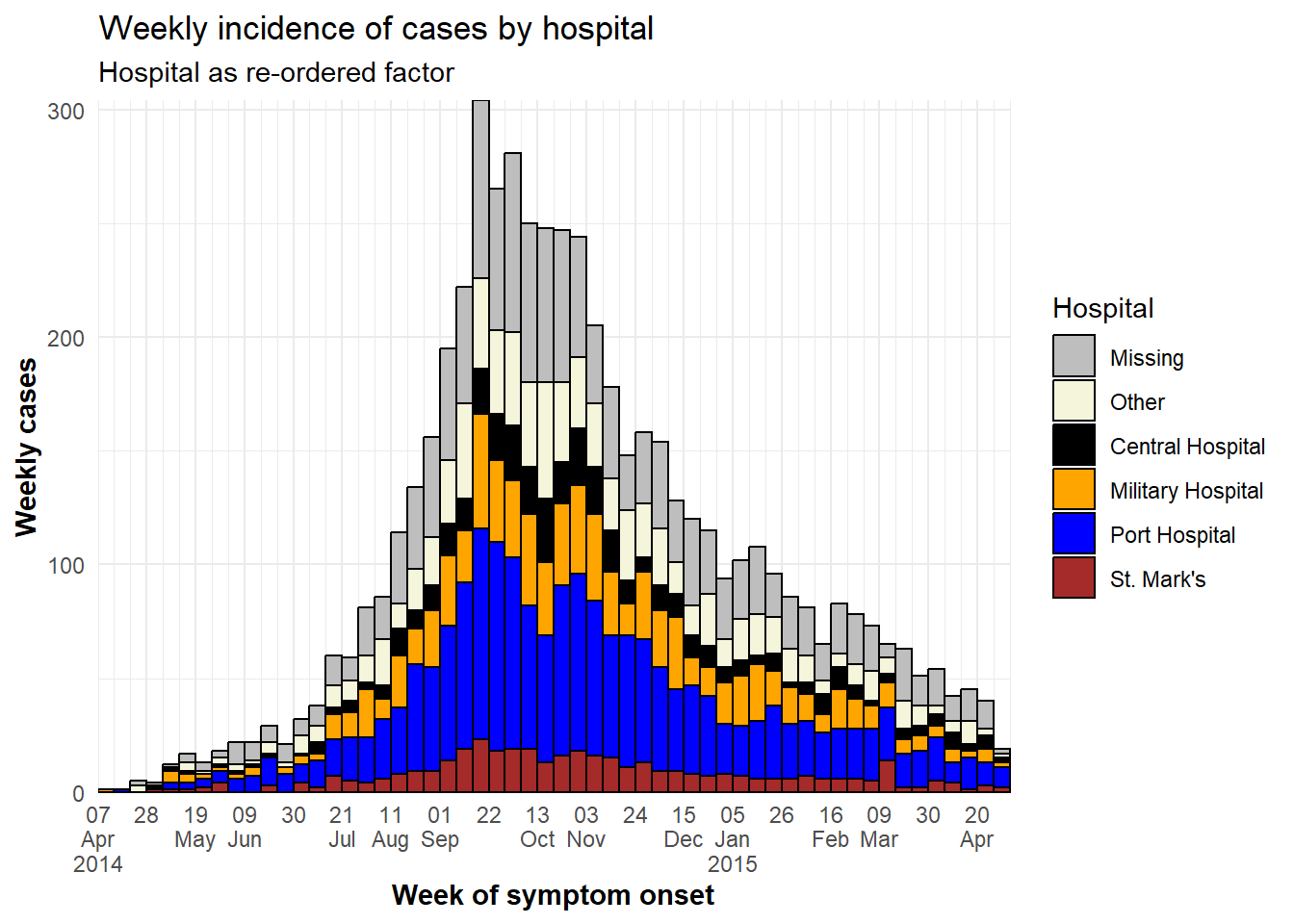
ヒント:凡例の順番を逆にするには、次の ggplot2 コマンドを使用します: guides(fill = guide_legend(reverse = TRUE)).
凡例の調整
凡例やスケールについては、ggplot のヒント の章で詳しく説明していますが、以下にその要約を記載します。
- 凡例のタイトルを編集するには、scale 関数か、
labs(fill = "Legend title")を使用する(color =aesthetic を使用している場合はlabs(color = "")を使用する) -
theme(legend.title = element_blank())で凡例のタイトルを削除 -
theme(legend.position = "top")(“bottom”, “left”, “right” で凡例をそれぞれ下、左、右に配置。または”none” で凡例が削除される) -
theme(legend.direction = "horizontal")で凡例を水平に配置 -
guides(fill = guide_legend(reverse = TRUE))で凡例の順序を逆にする
棒グラフの横並び表示
グループ化されたヒストグラムのビンを積み重ねではなく横並びに表示するには、geom_histogram() 内で position = "dodge" と指定します(aes() の外で指定する)。
2 つ以上のグループがある場合、読みにくくなることがあるため、代わりにファセット化された可視化(グループごとにヒストグラムを表示する)を行った方が良いかも知れません。以下の例では、見やすくするために性別の欠測値を削除しています。
ggplot(central_data %>% drop_na(gender))+ # 性別の欠損値を除外する
geom_histogram(
mapping = aes(
x = date_onset,
group = gender, # gender でグループ化する
fill = gender), # gender 毎に棒グラフを色分けする
# ヒストグラムのビン分割の指定
breaks = weekly_breaks_central, # 上で定義したビンの分割
closed = "left", # 分割の開始から症例数をカウントする
color = "black", # 枠線の色の指定
position = "dodge")+ # 棒グラフを横並びに指定
# x軸のラベル
scale_x_date(expand = c(0,0), # X軸の前後の余分なスペースを削除
date_breaks = "3 weeks", # データを3週ごとに表示
date_minor_breaks = "week", # 縦縦罫線を1週ごとに表示
label = scales::label_date_short())+ # 日付ラベルのフォーマット
# y軸のラベル
scale_y_continuous(expand = c(0,0))+ # y軸の前後の余分なスペースを削除
#手動での色の指定
scale_fill_manual(values = c("brown", "orange"), # 手動での色の指定、順番に注意!
na.value = "grey" )+
# 外観の変更
theme_minimal()+ # 背景を簡潔なものに指定
theme(plot.caption = element_text(face = "italic", hjust = 0), # 脚注をイタリック体にして左に幅寄せ
axis.title = element_text(face = "bold"))+ # 軸タイトルを太字に
# ラベルの指定
labs(title = "Weekly incidence of cases, by gender",
subtitle = "Subtitle",
fill = "Gender", # 凡例のタイトルを指定
x = "Week of symptom onset",
y = "Weekly incident cases reported")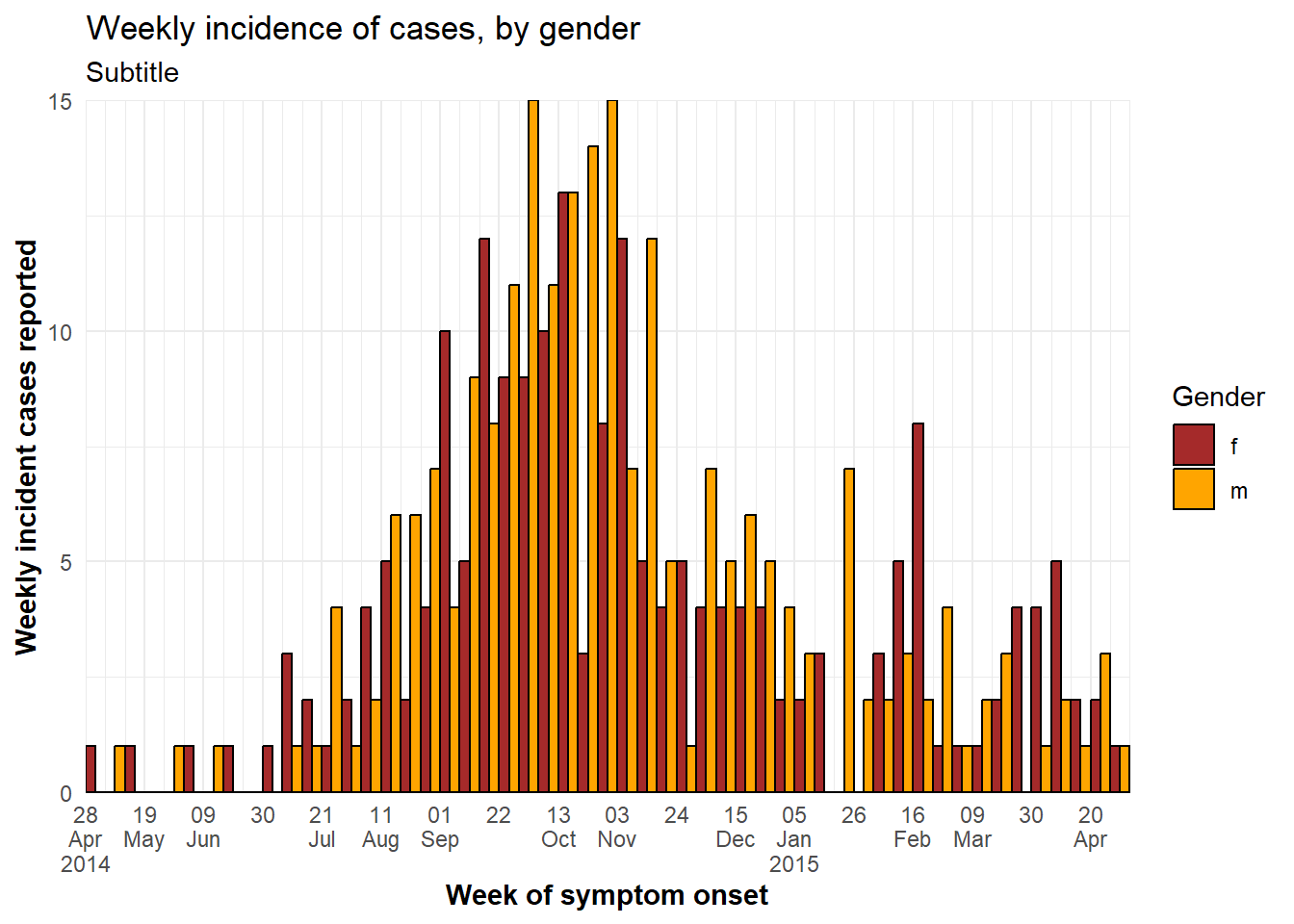
軸の範囲
軸の値の範囲を決める方法は 2 つあります。
一般的な方法は、xlim = c(min, max) と ylim = c(min, max) を包含する coord_cartesian() コマンドを使用することです(それぞれで min と max の値を指定します)。これは、実際にデータを削除するのではなく「ズーム」として機能し、統計量や要約尺度において重要です。
もう一つの方法として、scale_x_date() 内で limits = c() を使用して、最初の日付と最後の日付を設定することもできます。
以下はその一例です。
scale_x_date(limits = c(as.Date("2014-04-01"), NA)) # 最初の日付を指定し、最後の日付は指定しない同様に、新しい症例が報告されていない場合でも、x 軸を特定の日付(例えば現在の日付)まで伸ばしたい場合は、次のように指定します。
scale_x_date(limits = c(NA, Sys.Date()) # 最後の日付を現在の日付に指定警告:y軸の区切りや範囲の設定には注意が必要です(例:0 から 30 までを 5 ごとに分割: seq(0, 30, 5))。このようなやり方では、データが設定範囲外の値だった場合にグラフが極端に短くなる場合があります!
日付軸のラベルと罫線
ヒント:日付軸のラベルはデータの集約とは関係ありませんが、ビン分割、日付ラベル、垂直罫線を視覚的に美しいように揃えるために重要です
日付ラベルと罫線を変更するには、以下のいずれかの方法で scale_x_date() を使用します。
-
ヒストグラムのビン分割が日、月、月曜始まりの週、月、年である場合:
date_breaks =を使用して、ラベルと大きい罫線の間隔を指定します(例:“day”、 “week”、 “3 weeks”、“month”、“year”)date_minor_breaks =を使用して(日付ラベルの間の)小さい縦罫線の間隔を指定します最初の棒グラフからラベルを開始するために
expand = c(0,0)を追加します日付のラベルの書式を指定するには
date_labels =を使用します。日付型データ の章では、役立つヒントを紹介しています(改行には\nを使用など)
-
ヒストグラムのビン分割が日曜始まりの週:
-
breaks =とminor_breaks =を使用してそれぞれ一連の日付の区切りを指定します - 上記のように
date_labels =とexpand =を使用して調節することも可能です
-
注意点:
seq.Date()を使用して日付のベクトルを作成する方法については、ggplot の基礎 の章を参照して下さい。日付ラベルを作成するためのヒントについては、こちら のウェブサイト、または、本ハンドブックの 日付型データ の章を参照してください。
2つの例の比較
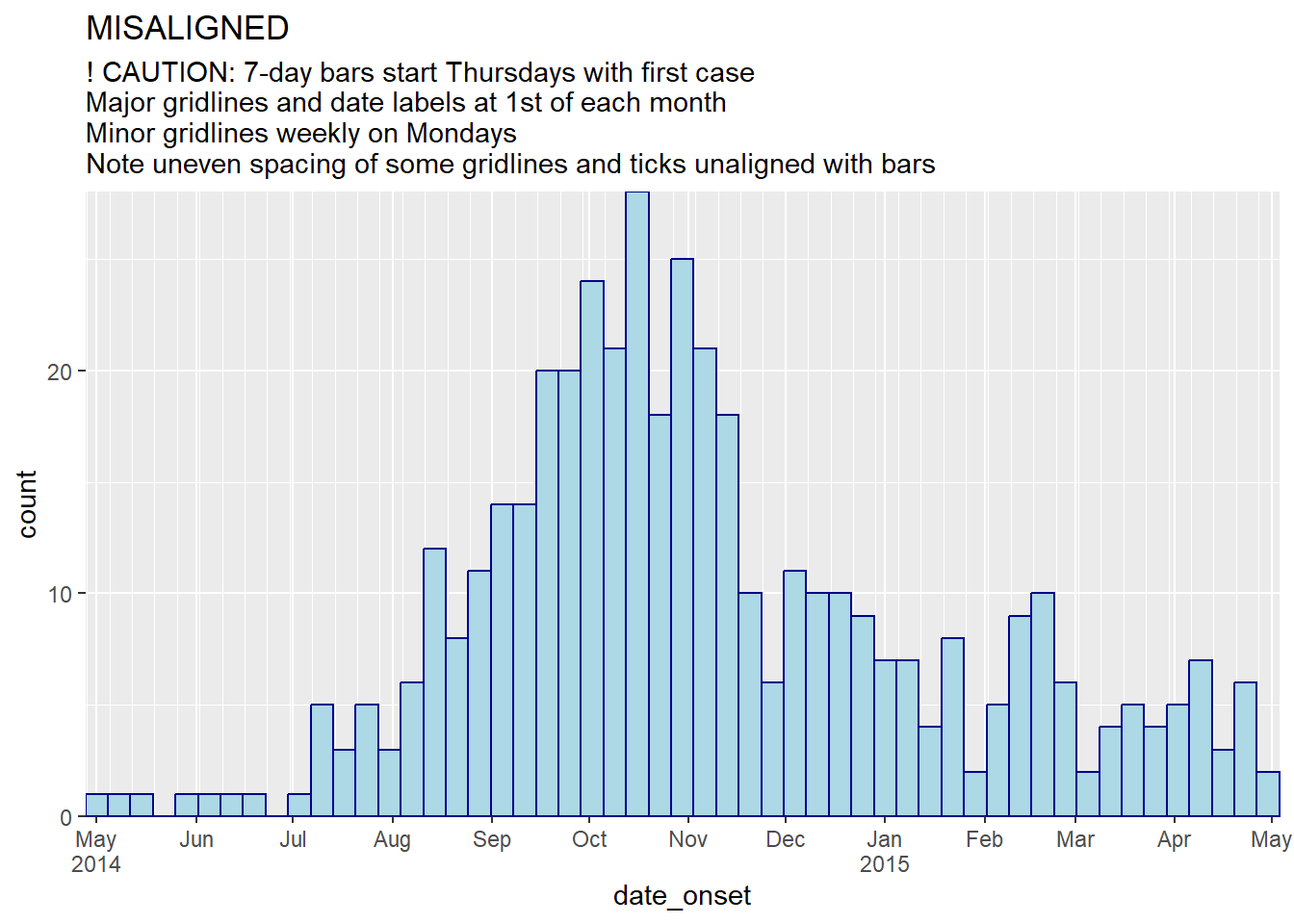
以下は、ビン分割とラベル、罫線が整列しているグラフと整列していないグラフの比較です。
# 7日ごとのビン分割+月曜ラベル
#############################
ggplot(central_data) +
geom_histogram(
mapping = aes(x = date_onset),
binwidth = 7, # 最初の症例から7日ごとのビン分割
color = "darkblue",
fill = "lightblue") +
scale_x_date(
expand = c(0,0), # X軸の前後の余分なスペースを削除
date_breaks = "3 weeks", # データを3週ごとに表示
date_minor_breaks = "week", # 縦罫線を1週ごとに表示
label = scales::label_date_short())+ # 日付ラベルのフォーマット
scale_y_continuous(
expand = c(0,0))+ # y軸の前後の余分なスペースを削除
labs(
title = "MISALIGNED",
subtitle = "! CAUTION: 7-day bars start Thursdays at first case\nDate labels and gridlines on Mondays\nNote how ticks don't align with bars")
# 7日ごとのビン分割+月
#####################
ggplot(central_data) +
geom_histogram(
mapping = aes(x = date_onset),
binwidth = 7,
color = "darkblue",
fill = "lightblue") +
scale_x_date(
expand = c(0,0), # X軸の前後の余分なスペースを削除
date_breaks = "months", # 月の一番はじめの日
date_minor_breaks = "week", # 縦罫線を1週ごとに表示
label = scales::label_date_short())+ # 日付ラベルのフォーマット
scale_y_continuous(
expand = c(0,0))+ # y軸の前後の余分なスペースを削除
labs(
title = "MISALIGNED",
subtitle = "! CAUTION: 7-day bars start Thursdays with first case\nMajor gridlines and date labels at 1st of each month\nMinor gridlines weekly on Mondays\nNote uneven spacing of some gridlines and ticks unaligned with bars")
# マニュアルでビン分割を月曜日に指定
#################################################################
ggplot(central_data) +
geom_histogram(
mapping = aes(x = date_onset),
# 最初の症例の前の月曜日から始まる7日ごとのビン分割を指定
breaks = weekly_breaks_central, # 本章で定義済み
closed = "left", # 分割の開始から症例数をカウントする
color = "darkblue",
fill = "lightblue") +
scale_x_date(
expand = c(0,0), # X軸の前後の余分なスペースを削除
date_breaks = "4 weeks", # 4週ごとの月曜日
date_minor_breaks = "week", # 月曜始まりの週
label = scales::label_date_short())+ # 日付ラベルのフォーマット
scale_y_continuous(
expand = c(0,0))+ # y軸の前後の余分なスペースを削除
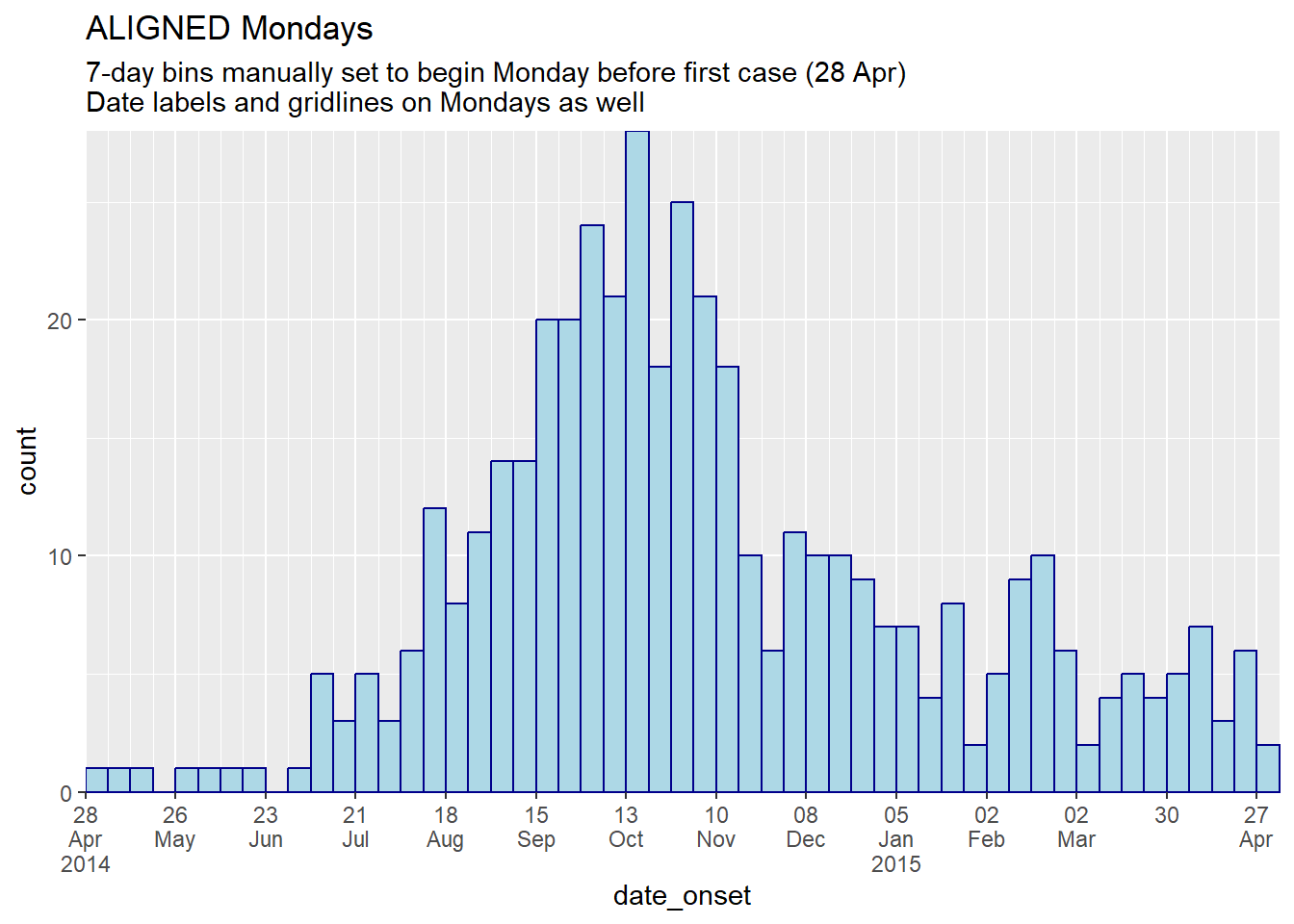
labs(
title = "ALIGNED Mondays",
subtitle = "7-day bins manually set to begin Monday before first case (28 Apr)\nDate labels and gridlines on Mondays as well")
# ラベルを月にして整列
############################################
ggplot(central_data) +
geom_histogram(
mapping = aes(x = date_onset),
# 最初の症例の前の月曜日から始まる7日ごとのビン分割を指定
breaks = weekly_breaks_central, # 本章で定義済み
closed = "left", # 分割の開始から症例数をカウントする
color = "darkblue",
fill = "lightblue") +
scale_x_date(
expand = c(0,0), # X軸の前後の余分なスペースを削除
date_breaks = "months", # 4週ごとの月曜日
date_minor_breaks = "week", # 月曜始まりの週
label = scales::label_date_short())+ # 日付ラベルのフォーマット
scale_y_continuous(
expand = c(0,0))+ # y軸の前後の余分なスペースを削除
theme(panel.grid.major = element_blank())+ # 大きい縦罫線の削除
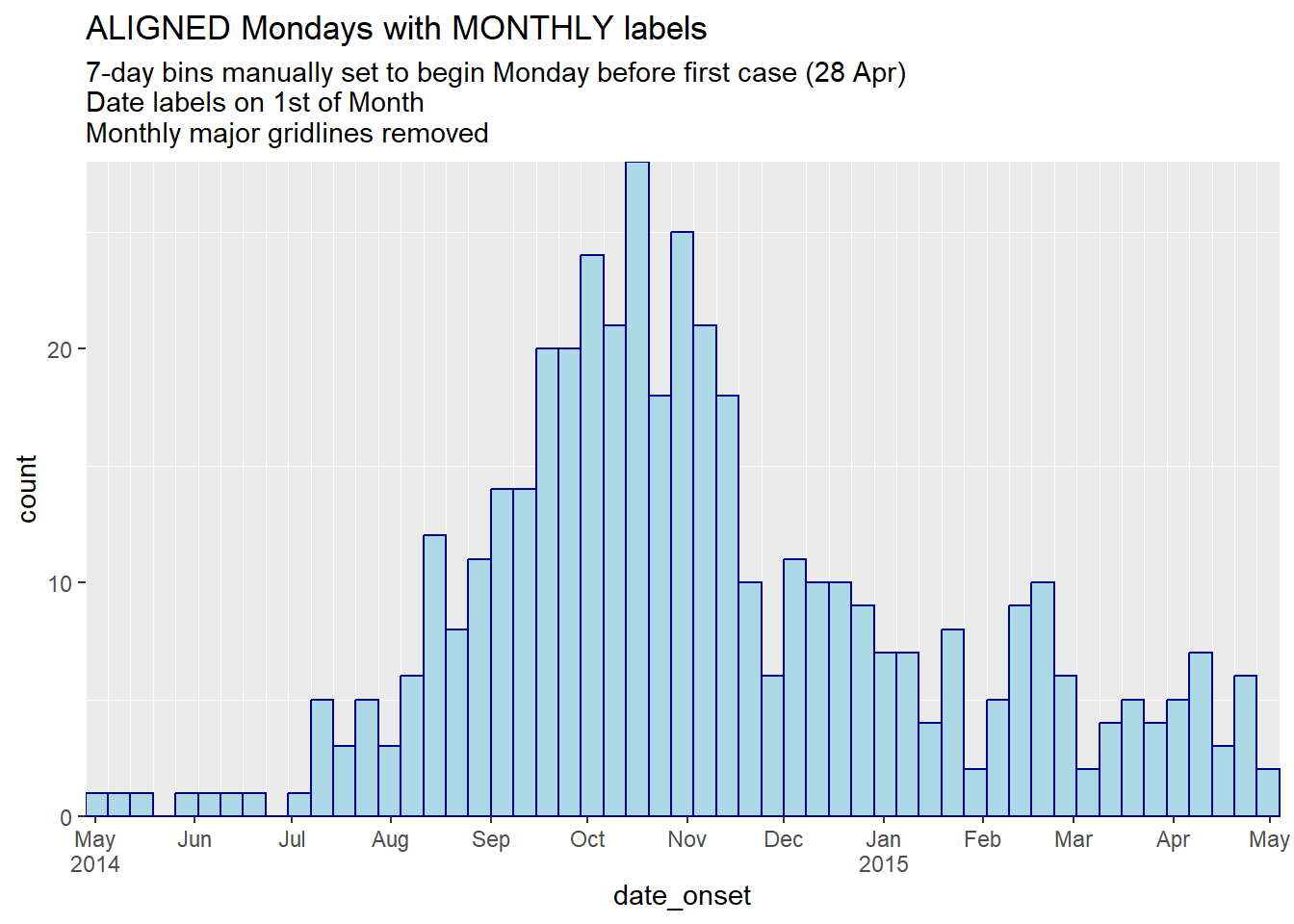
labs(
title = "ALIGNED Mondays with MONTHLY labels",
subtitle = "7-day bins manually set to begin Monday before first case (28 Apr)\nDate labels on 1st of Month\nMonthly major gridlines removed")
# マニュアルでビン分割とラベルを日曜日に指定
############################################################################
ggplot(central_data) +
geom_histogram(
mapping = aes(x = date_onset),
# 最初の症例の前の日曜日から始まる7日ごとのビン分割を指定
breaks = seq.Date(from = floor_date(min(central_data$date_onset, na.rm=T), "week", week_start = 7),
to = ceiling_date(max(central_data$date_onset, na.rm=T), "week", week_start = 7),
by = "7 days"),
closed = "left", # 分割の開始から症例数をカウントする
color = "darkblue",
fill = "lightblue") +
scale_x_date(
expand = c(0,0),
# 最初の症例の前の日曜日から始まる3週間ごとのラベルと大きい罫線を指定
breaks = seq.Date(from = floor_date(min(central_data$date_onset, na.rm=T), "week", week_start = 7),
to = ceiling_date(max(central_data$date_onset, na.rm=T), "week", week_start = 7),
by = "3 weeks"),
# 最初の症例の前の日曜日から始まる7日ごとの小さい罫線を指定
minor_breaks = seq.Date(from = floor_date(min(central_data$date_onset, na.rm=T), "week", week_start = 7),
to = ceiling_date(max(central_data$date_onset, na.rm=T), "week", week_start = 7),
by = "7 days"),
label = scales::label_date_short())+ # 日付ラベルのフォーマット
scale_y_continuous(
expand = c(0,0))+ # y軸の前後の余分なスペースを削除
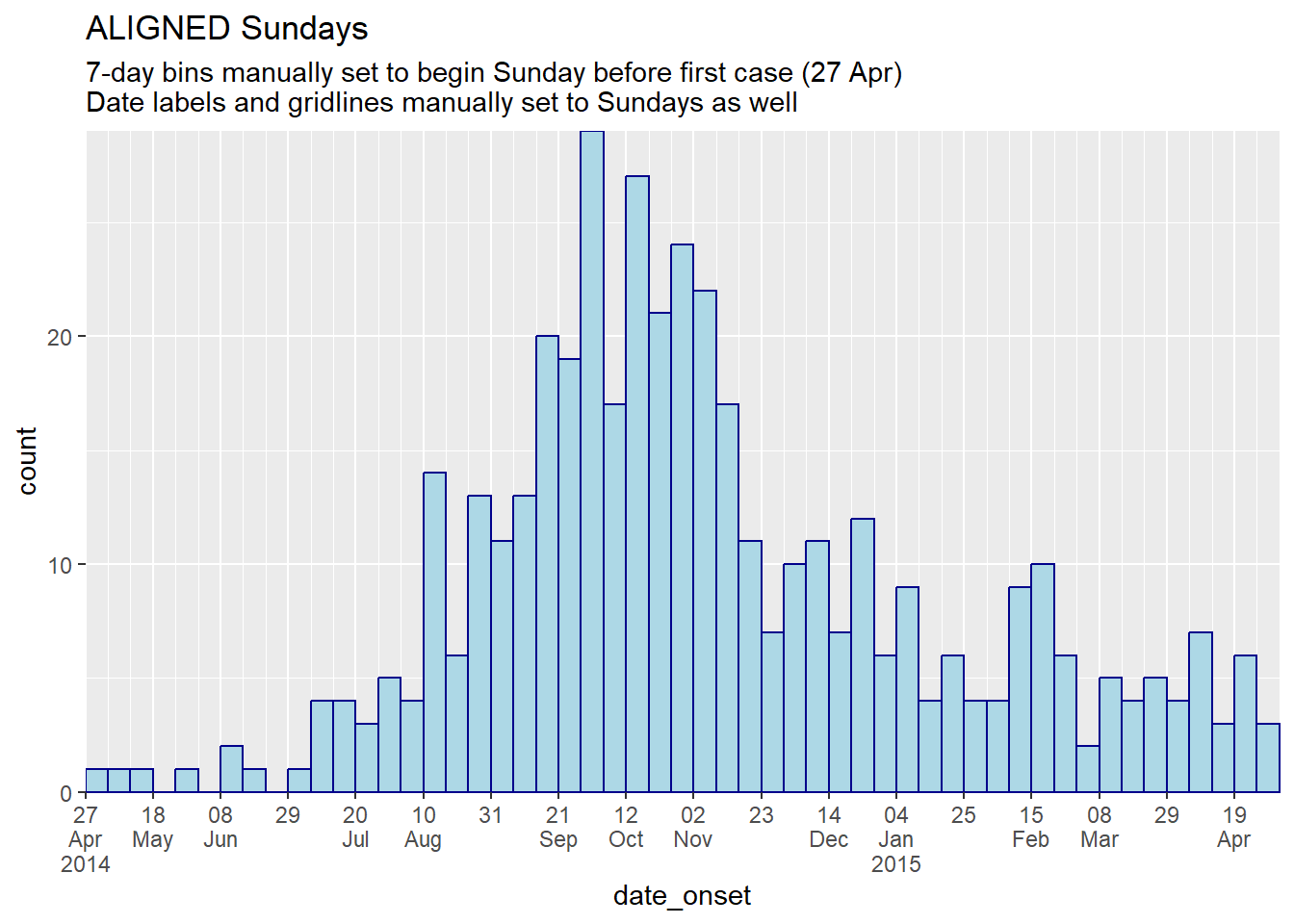
labs(title = "ALIGNED Sundays",
subtitle = "7-day bins manually set to begin Sunday before first case (27 Apr)\nDate labels and gridlines manually set to Sundays as well")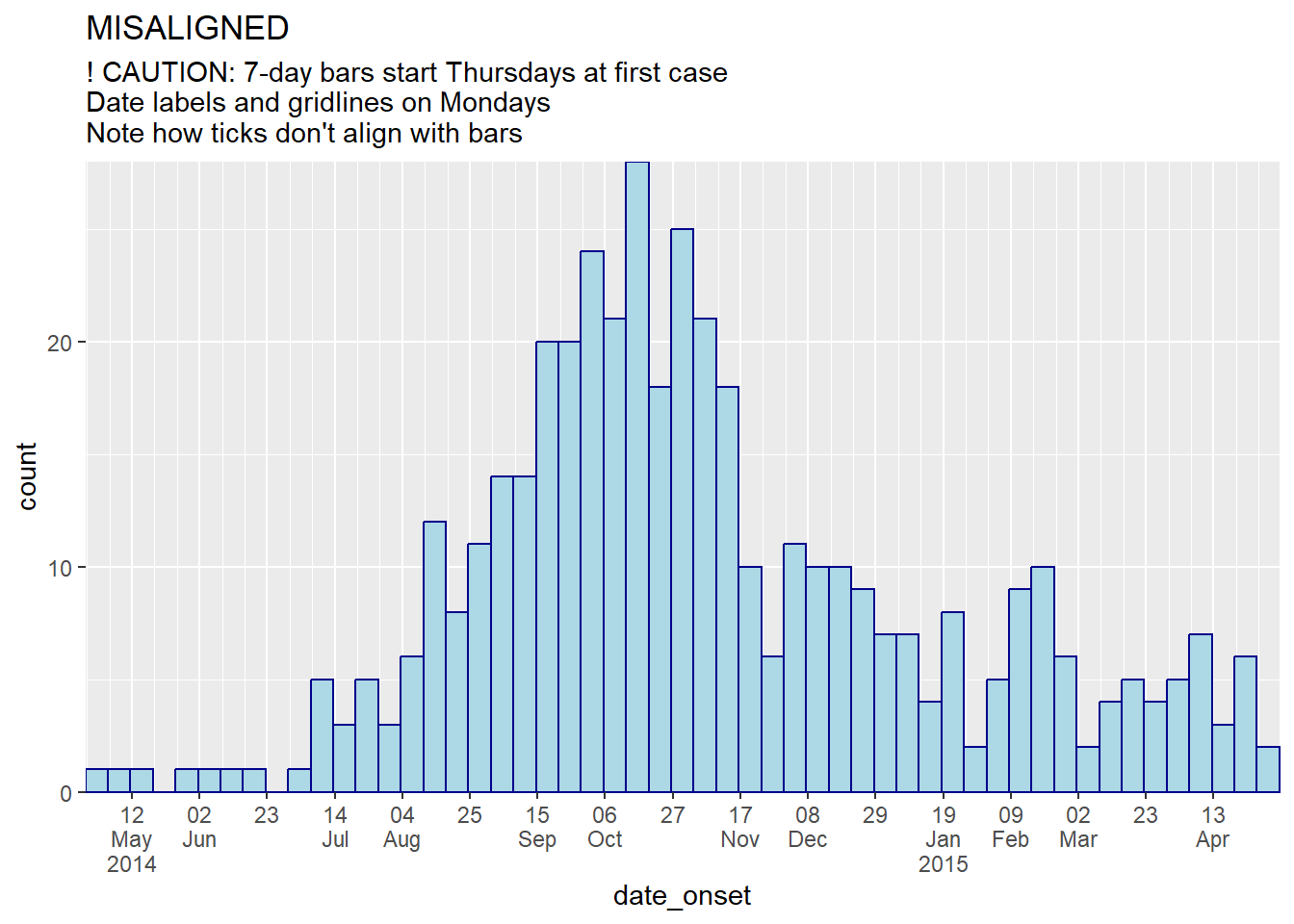
集計データ
ラインリストではなく、施設や地域などの集計データのみがあることが多くあります。集計データのみでも ggplot() で流行曲線を作成することができますが、コードが少し異なります。このセクションでは、先述のデータ準備のセクションでインポートした count_data データセットを使用します。このデータセットは、linelist に含まれている症例数を日別にカウントしたデータです。最初の 50 行を以下に表示します。
日別カウントデータの可視化
日別カウントデータから流行曲線を作成することができます。以下は以前のコードとの相違点です。
aes()内で、日別カウントデータをy =に指定します(この場合、列名はn_casesです)。geom_histogram()に引数stat = "identity"を追加し、ヒストグラムのビンの高さをデフォルトの行数ではなく、y =として指定します。棒グラフの間に縦の白線が入らないように、
width =の引数を追加します。日別データの場合、1 に設定します。週別カウントデータの場合は 7 に設定します。月別のカウントデータでは、(各月で日数が異なるため)白線が問題となりますので、x 軸を因子型(月)に変換してgeom_col()を使用することを検討して下さい。
ggplot(data = count_data)+
geom_histogram(
mapping = aes(x = date_hospitalisation, y = n_cases),
stat = "identity",
width = 1)+ # 日別カウントデータ の場合は set width = 1 で棒グラフの間のスペースを適切にする
labs(
x = "Date of report",
y = "Number of cases",
title = "Daily case incidence, from daily count data")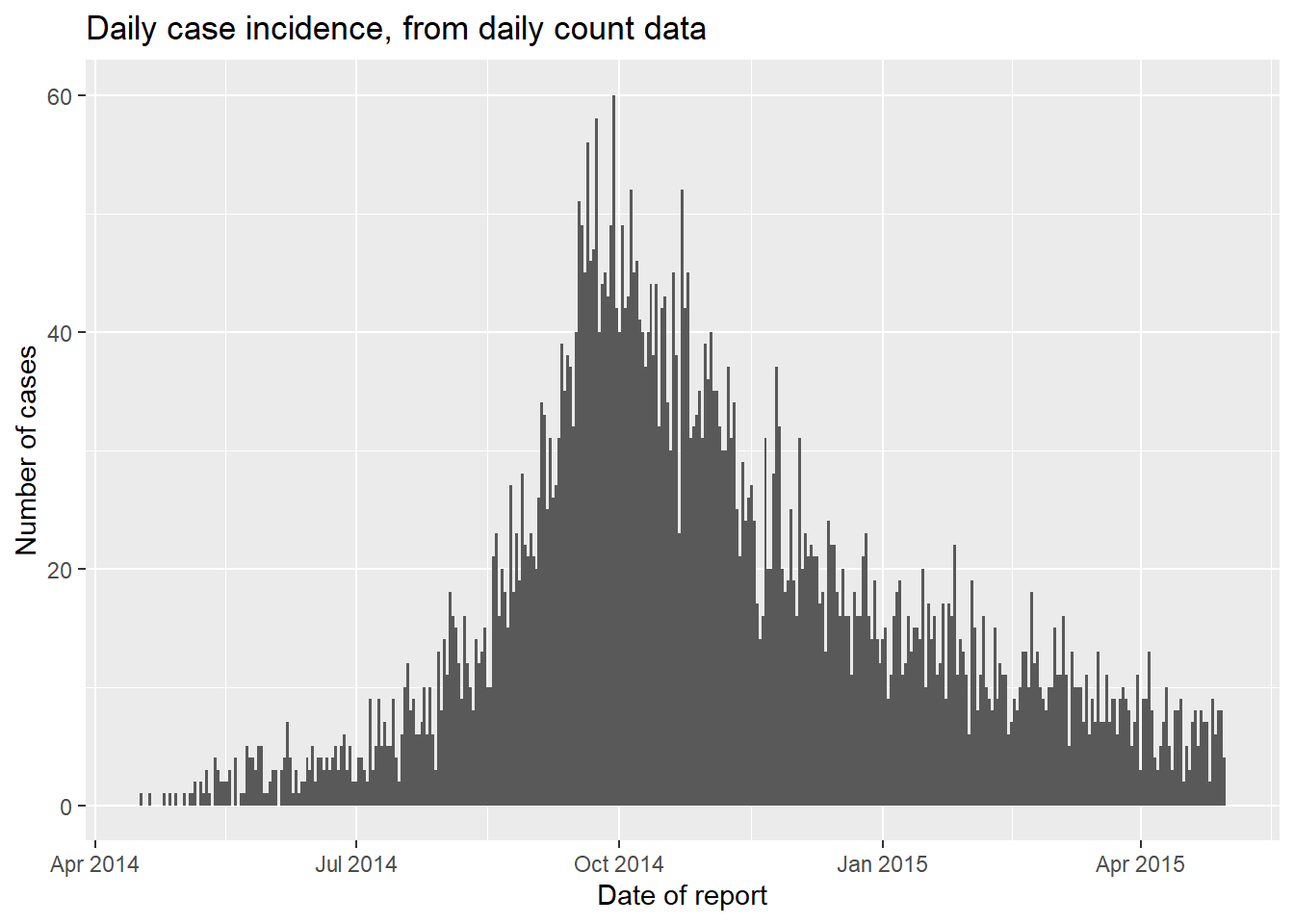
週別カウントデータの可視化
もしデータが週ごとの症例数であれば、以下と同じようになっているはずです(count_data_weekly というデータセット名にしています)。
以下に表示した count_data_weekly の最初の 50 行を見ると、週単位で症例が集計されていることがわかります。各週は、週の最初の日(デフォルトでは月曜日)で表示されています。
x = 引数に epiweek 列を指定して流行曲線をプロットします。y = 引数にカウント列(この例では、n_cases_weekly 列)を指定し、上で説明したように stat = "identity" を追加することを忘れないで下さい。
ggplot(data = count_data_weekly)+
geom_histogram(
mapping = aes(
x = epiweek, # x軸に疫学週を指定(日付型として)
y = n_cases_weekly, # y軸に週別カウントデータを指定
group = hospital, # hospital でグループ化して色分け
fill = hospital),
stat = "identity")+ # カウントデータをプロットする場合に必要
# x軸のラベル
scale_x_date(
date_breaks = "2 months", # データを2か月ごとに表示
date_minor_breaks = "1 month", # 縦罫線を1か月ごとに表示
label = scales::label_date_short())+ # 日付ラベルのフォーマット(月の下に年を記載)
# 色パレットを指定 (RColorBrewer パッケージを使用)
scale_fill_brewer(palette = "Pastel2")+
theme_minimal()+
labs(
x = "Week of onset",
y = "Weekly case incidence",
fill = "Hospital",
title = "Weekly case incidence, from aggregated count data by hospital")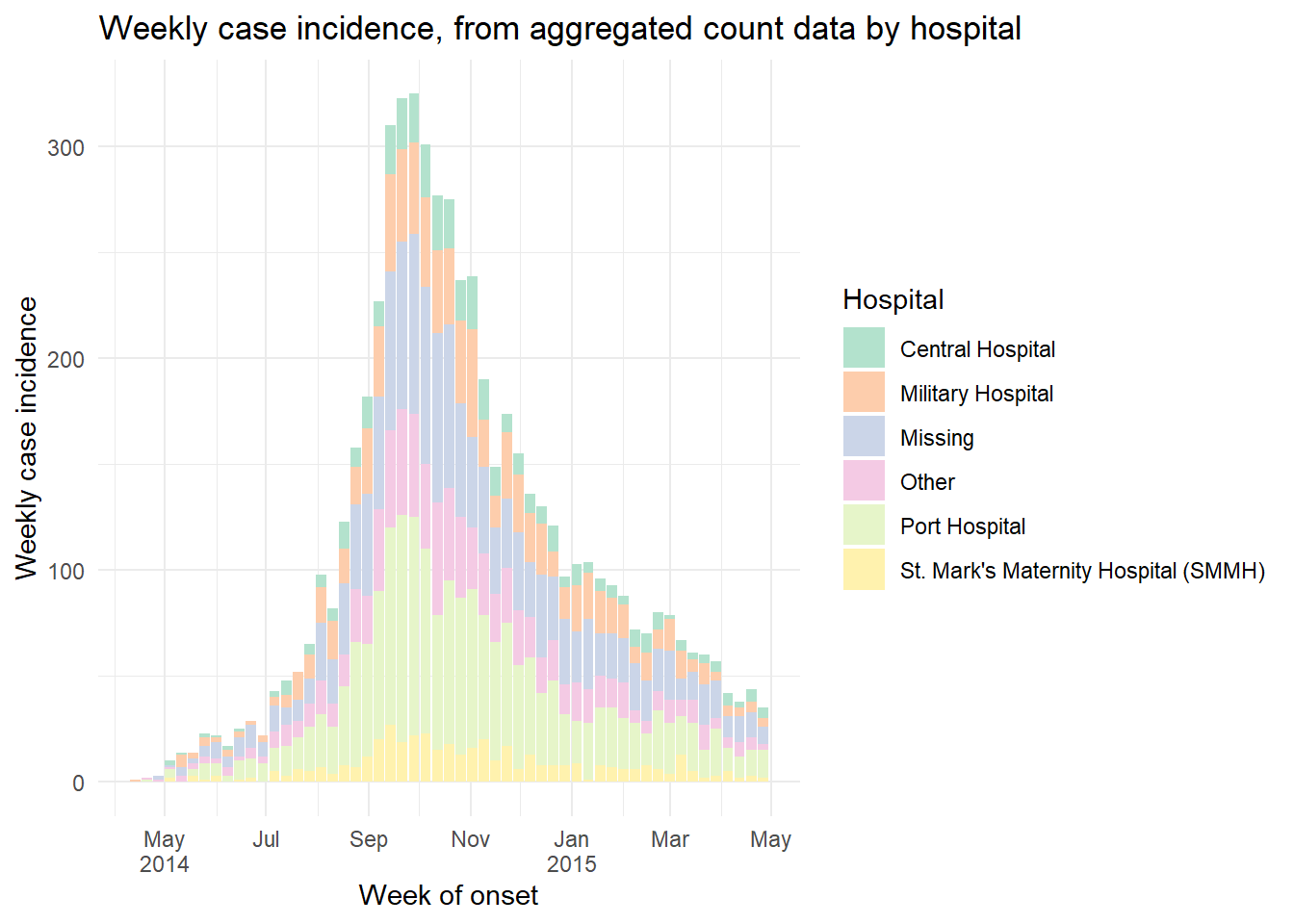
移動平均
詳細な説明については、移動平均 の章を参照して下さい。以下は、slider パッケージで移動平均を計算する方法の 1 つです。この方法では、移動平均はプロットする前にデータセット上で計算されます。
- データを日別、週別など必要に応じて集計します(データのグループ化 の章を参照)。
-
slider パッケージの
slide_index()で移動平均の列を新しく作成します。
- 移動平均を
geom_line()で 流行曲線の上(後)にプロットします。
詳細は slider パッケージの説明を参照して下さい。
# パッケージの読み込み
pacman::p_load(slider) # 移動平均の計算に slider を使用
# 週別カウントと7日間移動平均のデータセットを作成
#######################################################
ll_counts_7day <- linelist %>% # ラインリスト
## 日別にカウント
count(date_onset, name = "new_cases") %>% # "new cases"という名前の列を作成
drop_na(date_onset) %>% # 発症日欠損症例を除外
## 7日間移動平均数を計算
mutate(
avg_7day = slider::slide_index( # 新しい列を作成
new_cases, # new_cases 列の値を用いる
.i = date_onset, # date_onset 列の含まれていない日付も移動平均に含める
.f = ~mean(.x, na.rm = TRUE), # 欠損値を除外した上で平均をとる
.before = 6, # 日別に6日前までのデータを移動平均に含める
.complete = FALSE), # 次のステップのために FALSE に設定する
avg_7day = unlist(avg_7day)) # list型から数字型に変換
# プロット
######
ggplot(data = ll_counts_7day) + # 以前のコードで定義済みのデータセット
geom_histogram( # ヒストグラムの作成
mapping = aes(
x = date_onset, # x軸の日付列を指定
y = new_cases), # y軸に日別のカウント数を指定
stat = "identity", # カウントデータように指定
fill="#92a8d1", # かっこいい色を指定
colour = "#92a8d1", # 枠線も同じ色に指定
)+
geom_line( # 移動平均の線グラフを作成
mapping = aes(
x = date_onset, # x軸の日付列を指定
y = avg_7day, # y軸に日別の移動平均を指定
lty = "7-day \nrolling avg"), # 線グラフの凡例を記載
color="red", # 線グラフの色の指定
size = 1) + # 線グラフの太さの指定
scale_x_date( # 日付軸のスケール
date_breaks = "1 month",
label = scales::label_date_short(),
expand = c(0,0)) +
scale_y_continuous( # y軸のスケール
expand = c(0,0),
limits = c(0, NA)) +
labs(
x="",
y ="Number of confirmed cases",
fill = "Legend")+
theme_minimal()+
theme(legend.title = element_blank()) # 凡例のタイトルを削除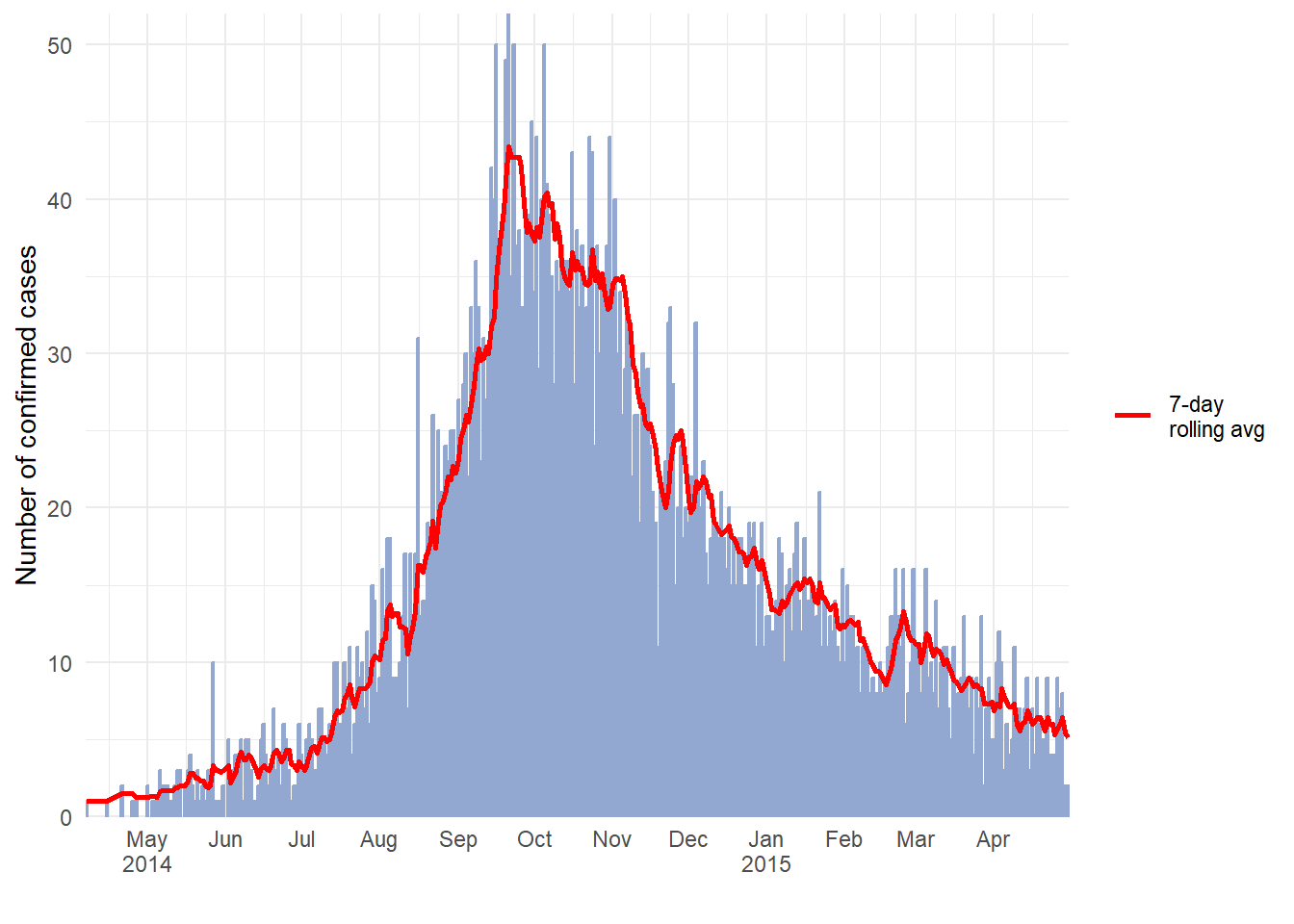
ファセット化・プロットの小分割
他の ggplot と同様に、ファセット化されたグラフ(「複数の小さなグラフを並べたグラフ」)を作成することができます。ggplot の基礎 の章で説明されているように、 facet_wrap() と facet_grid() のどちらかを使用することができますが、ここでは facet_wrap() を使って説明します。流行曲線の作成においては、1 つの列に対してのみファセットするだけでよいので、一般的に facet_wrap() の方が簡単です。
一般的な構文は facet_wrap(rows ~ cols) で、チルダ (~) の左側はファセット化プロットの「行」に対する列の名前、チルダの右側はファセット化プロットの「列」に対する列の名前です。最も簡単な例では、チルダの右側に 1 つの列を指定します: facet_wrap(~age_cat)
フリースケール
各ファセットの軸のスケールを同じ値に「固定」(デフォルト)するか、「自由」(ファセット内のデータに基づいて変更する)にするかを指定します。これは、facet_wrap() 内の scales = 引数で、“free_x” か “free_y” か “free” を指定することでできます。
ファセットの列数と行数facet_wrap() 内で ncol = または nrow = で指定することができます。
パネルの順番
順序を変更するには、ファセットを作成するために使用される因子型列のレベルの順序を変更します。
外観
フォントサイズ、ヘッダ、色などは、以下のような引数を持つ theme() で変更することができます。
-
strip.text = element_text()(サイズ、ヘッダ、色、角度など) -
strip.background = element_rect()(例:element_rect(fill=“grey”)) -
strip.position =(ファセットのタイトルが記載されるボックスの場所を指定:“bottom”, “top”, “left”, or “right”)
ファセットラベル
ファセットプロットのラベルは、列の「ラベル」を用いるか「ラベラー(labeller)」の使用によって変更することができます。
ggplot2 の関数 as_labeller() を用いて、ラベラーを作成した後に、以下のように facet_wrap() の labeller = 引数に作成したラベラーを指定します。
my_labels <- as_labeller(c(
"0-4" = "Ages 0-4",
"5-9" = "Ages 5-9",
"10-14" = "Ages 10-14",
"15-19" = "Ages 15-19",
"20-29" = "Ages 20-29",
"30-49" = "Ages 30-49",
"50-69" = "Ages 50-69",
"70+" = "Over age 70"))以下は、age_cat 列でファセットしたグラフの作成例です。
# プロットの作成
###########
ggplot(central_data) +
geom_histogram(
mapping = aes(
x = date_onset,
group = age_cat,
fill = age_cat), # aes() 内の引数はグループされる
color = "black", # aes() 外の引数は全データに適用される
# ビン分割
breaks = weekly_breaks_central, # 以前のコードで定義済み (ggplot セクション参照)
closed = "left" # count cases from start of breakpoint
)+
# x軸のラベル
scale_x_date(
expand = c(0,0), # X軸の前後の余分なスペースを削除
date_breaks = "2 months", # データを2月ごとに表示
date_minor_breaks = "1 month", # 縦罫線を1月ごとに表示
label = scales::label_date_short())+ # 日付ラベルのフォーマット
# y軸のラベル
scale_y_continuous(expand = c(0,0))+ # y軸の前後の余分なスペースを削除
# テーマの指定
theme_minimal()+ # 背景を簡潔なものに指定
theme(
plot.caption = element_text(face = "italic", hjust = 0), # 脚注をイタリック体にして左に幅寄せ
axis.title = element_text(face = "bold"),
legend.position = "bottom",
strip.text = element_text(face = "bold", size = 10),
strip.background = element_rect(fill = "grey"))+ # 軸タイトルを太字に
# ファセットの作成
facet_wrap(
~age_cat,
ncol = 4,
strip.position = "top",
labeller = my_labels)+
# ラベル
labs(
title = "Weekly incidence of cases, by age category",
subtitle = "Subtitle",
fill = "Age category", # 凡例のタイトル
x = "Week of symptom onset",
y = "Weekly incident cases reported",
caption = stringr::str_glue("n = {nrow(central_data)} from Central Hospital; Case onsets range from {format(min(central_data$date_onset, na.rm=T), format = '%a %d %b %Y')} to {format(max(central_data$date_onset, na.rm=T), format = '%a %d %b %Y')}\n{nrow(central_data %>% filter(is.na(date_onset)))} cases missing date of onset and not shown"))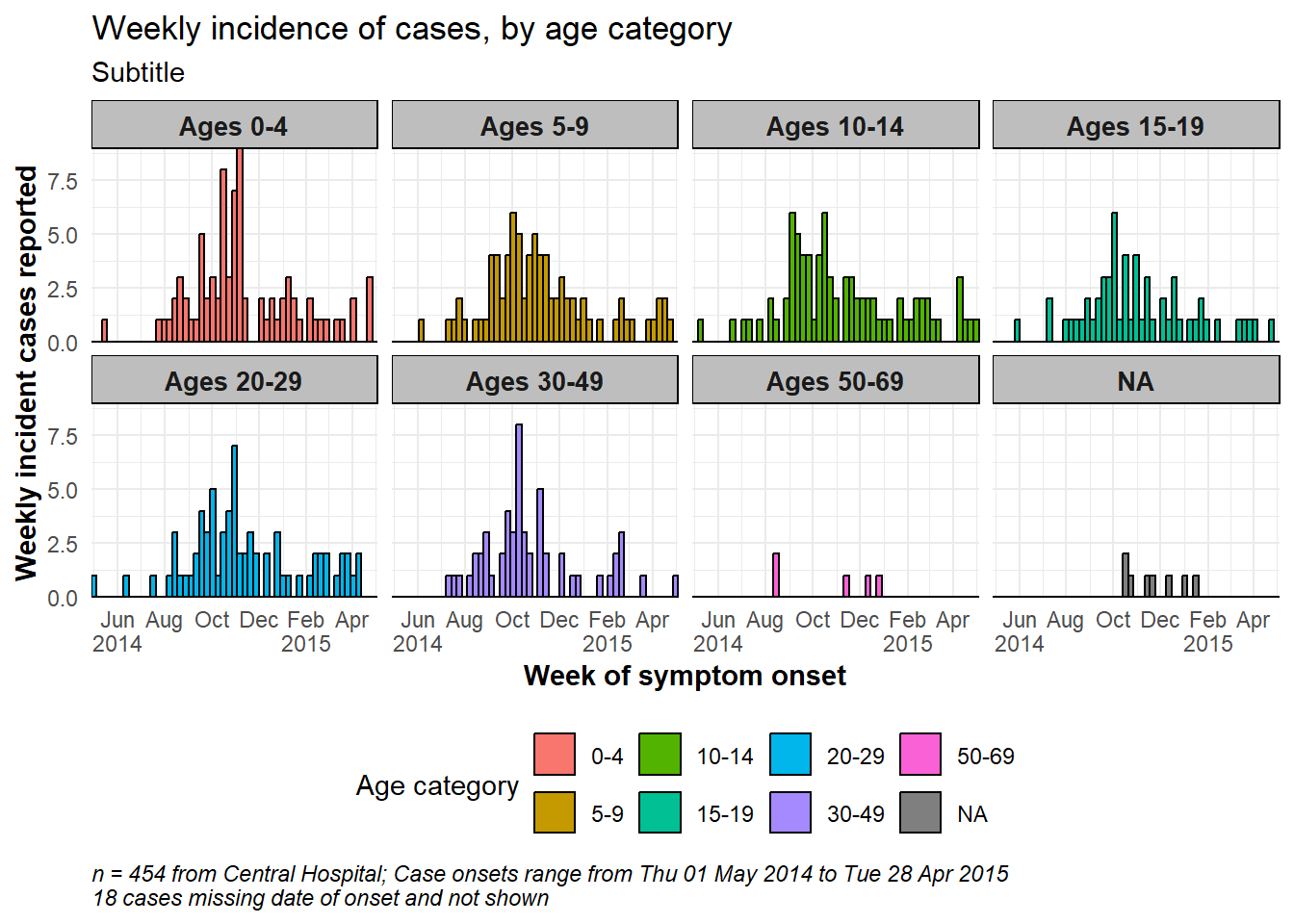
ラベラーの詳細については、こちら のウェブサイトを参照してください。
ファセットの背景に全体の流行曲線を表示
各ファセットの背景に全体の流行曲線を表示するには、ggplot で作成した図に gghighlight パッケージの gghighlight() を追加します。すべてのファセットにおける y 軸の最大値が、全体の流行曲線の頂点になっていることに注意して下さい。gghighlight パッケージの例は、ggplot の基礎 の章で多く紹介されています。
ggplot(central_data) +
# グループ化された流行曲線
geom_histogram(
mapping = aes(
x = date_onset,
group = age_cat,
fill = age_cat), # aes() 内の引数はグループされる
color = "black", # aes() 外の引数は全データに適用される
# ビン分割
breaks = weekly_breaks_central, # 以前のコードで定義済み (ggplot セクション参照)
closed = "left" # 分割の開始から症例数をカウントする
)+ # 以前のコードで定義済み (ggplot セクション参照)
# ファセットの背景に全体の流行曲線を灰色で示す
gghighlight::gghighlight()+
# x軸のラベル
scale_x_date(
expand = c(0,0), # X軸の前後の余分なスペースを削除
date_breaks = "2 months", # データを2月ごとに表示
date_minor_breaks = "1 month", # 縦罫線を1月ごとに表示
label = scales::label_date_short())+ # 日付ラベルのフォーマット
# y軸のラベル
scale_y_continuous(expand = c(0,0))+ # y軸の前後の余分なスペースを削除
# テーマの指定
theme_minimal()+ # 背景を簡潔なものに指定
theme(
plot.caption = element_text(face = "italic", hjust = 0), # 脚注をイタリック体にして左に幅寄せ
axis.title = element_text(face = "bold"),
legend.position = "bottom",
strip.text = element_text(face = "bold", size = 10),
strip.background = element_rect(fill = "white"))+ # 軸タイトルを太字に
# ファセットの作成
facet_wrap(
~age_cat, # それぞれのプロットに age_cat のグループを表示
ncol = 4, # 列数を指定
strip.position = "top", # ファセットタイトルの位置を指定
labeller = my_labels)+ # 上で定義した labeller の指定
# ラベル
labs(
title = "Weekly incidence of cases, by age category",
subtitle = "Subtitle",
fill = "Age category", # 凡例のタイトル
x = "Week of symptom onset",
y = "Weekly incident cases reported",
caption = stringr::str_glue("n = {nrow(central_data)} from Central Hospital; Case onsets range from {format(min(central_data$date_onset, na.rm=T), format = '%a %d %b %Y')} to {format(max(central_data$date_onset, na.rm=T), format = '%a %d %b %Y')}\n{nrow(central_data %>% filter(is.na(date_onset)))} cases missing date of onset and not shown"))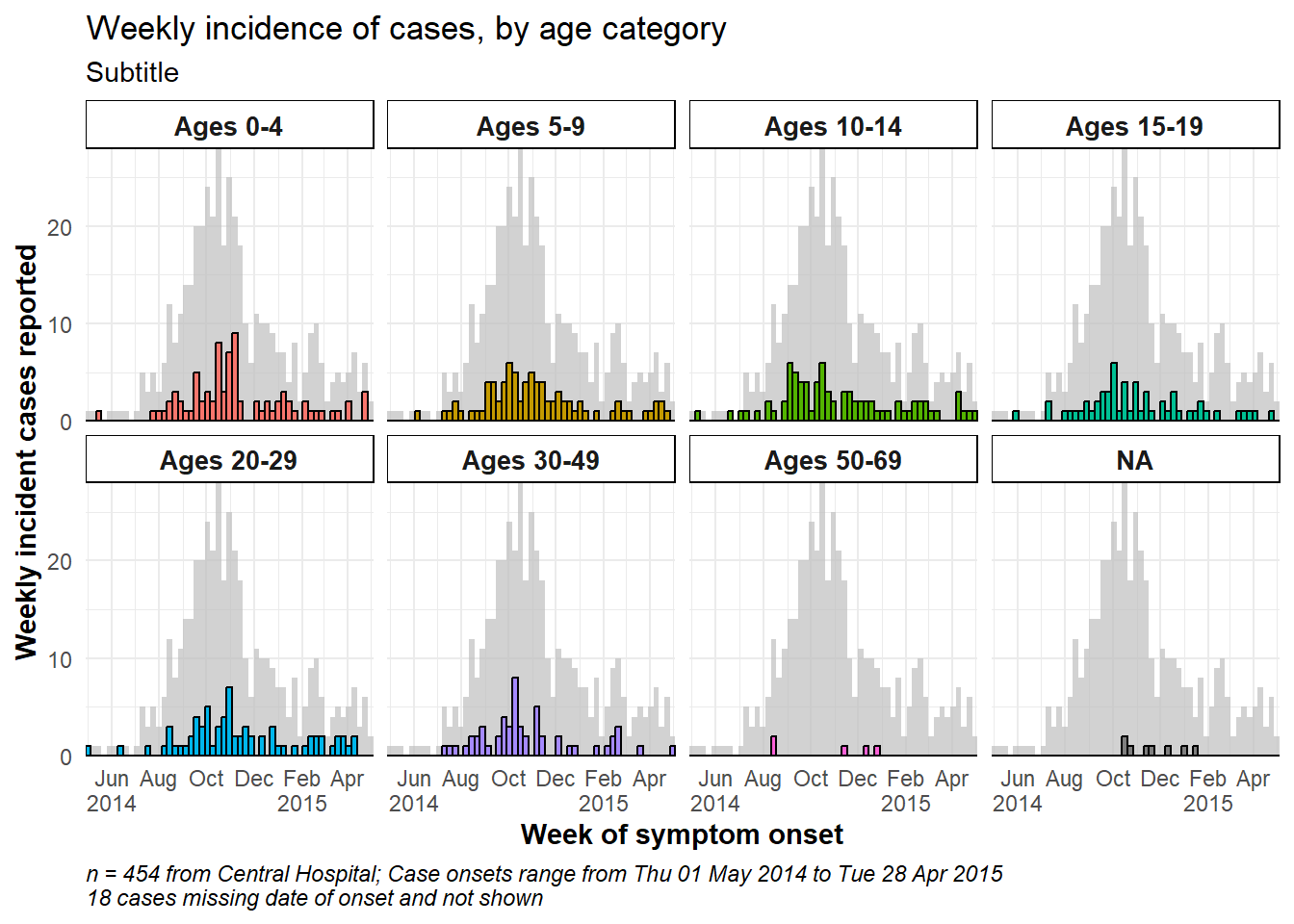
全データを含んだファセットの作成
全データを含むファセットボックスを表示したい場合は、データセット全体を複製し、複製したものを 1 つのファセットとして扱います。以下で自作する関数(ヘルパー関数)である CreateAllFacet() を使用すると可能です(このヘルパー関数は、こちら のページで紹介されているものです)。この関数を実行すると、行の数が 2 倍になり、facet という新しい列が作られます。その中で新たに複製された行は「all」という値を、元の行は facet 列の元の値を持つようになります。その後にこの facet 列に対してファセットを行います。
まず、ヘルパー関数を作成して実行し、利用できるようにします。
# helper 関数を定義する
CreateAllFacet <- function(df, col){
df$facet <- df[[col]]
temp <- df
temp$facet <- "all"
merged <-rbind(temp, df)
# ファセット値を因子型に指定
merged[[col]] <- as.factor(merged[[col]])
return(merged)
}次にこのヘルパー関数をデータセットの age_cat 列に適用します。
# 複製されたデータセットに新たに「facet」列を追加し、別のファセットレベルとして「all」年齢区分を表示する。
central_data2 <- CreateAllFacet(central_data, col = "age_cat") %>%
# 因子のレベルを指定
mutate(facet = fct_relevel(facet, "all", "0-4", "5-9",
"10-14", "15-19", "20-29",
"30-49", "50-69", "70+"))Warning: There was 1 warning in `mutate()`.
ℹ In argument: `facet = fct_relevel(...)`.
Caused by warning:
! 1 unknown level in `f`: 70+# レベルのチェック
table(central_data2$facet, useNA = "always")
all 0-4 5-9 10-14 15-19 20-29 30-49 50-69 <NA>
454 84 84 82 58 73 57 7 9 ggplot() コマンドにおける注意点は、以下の通りです。
使用するデータセットは central_data2(行数が 2 倍になり、新しい列 “facet” が追加)
ラベラーを使用する場合は、更新する必要があります。
必要であれば:縦に積み重ねたファセットを実現するために、ファセット列を式の行側に移動し、右側を “.” (
facet_wrap(facet~.)) に置き換え、ncol = 1とします。保存される png ファイルの幅と高さの調整が必要になります(ggplot の基礎 の章で紹介しているggsave()を参照してください)。
ggplot(central_data2) +
# グループ化された流行曲線
geom_histogram(
mapping = aes(
x = date_onset,
group = age_cat,
fill = age_cat), # aes() 内の引数はグループされる
color = "black", # aes() 外の引数は全データに適用される
# ビン分割
breaks = weekly_breaks_central, # 以前のコードで定義済み (ggplot セクション参照)
closed = "left", # 分割の開始から症例数をカウントする
)+ # 以前のコードで定義済み (ggplot セクション参照)
# x軸のラベル
scale_x_date(
expand = c(0,0), # X軸の前後の余分なスペースを削除
date_breaks = "2 months", # データを2月ごとに表示
date_minor_breaks = "1 month", # 縦罫線を1月ごとに表示
label = scales::label_date_short())+ # 日付ラベルのフォーマット
# y軸のラベル
scale_y_continuous(expand = c(0,0))+ # y軸の前後の余分なスペースを削除
# テーマの指定
theme_minimal()+ # 背景を簡潔なものに指定
theme(
plot.caption = element_text(face = "italic", hjust = 0), # 脚注をイタリック体にして左に幅寄せ
axis.title = element_text(face = "bold"),
legend.position = "bottom")+
# ファセットの作成
facet_wrap(facet~. , # それぞれのプロットに一つのファセットを指定
ncol = 1)+
# labels
labs(title = "Weekly incidence of cases, by age category",
subtitle = "Subtitle",
fill = "Age category", # 凡例のタイトル
x = "Week of symptom onset",
y = "Weekly incident cases reported",
caption = stringr::str_glue("n = {nrow(central_data)} from Central Hospital; Case onsets range from {format(min(central_data$date_onset, na.rm=T), format = '%a %d %b %Y')} to {format(max(central_data$date_onset, na.rm=T), format = '%a %d %b %Y')}\n{nrow(central_data %>% filter(is.na(date_onset)))} cases missing date of onset and not shown"))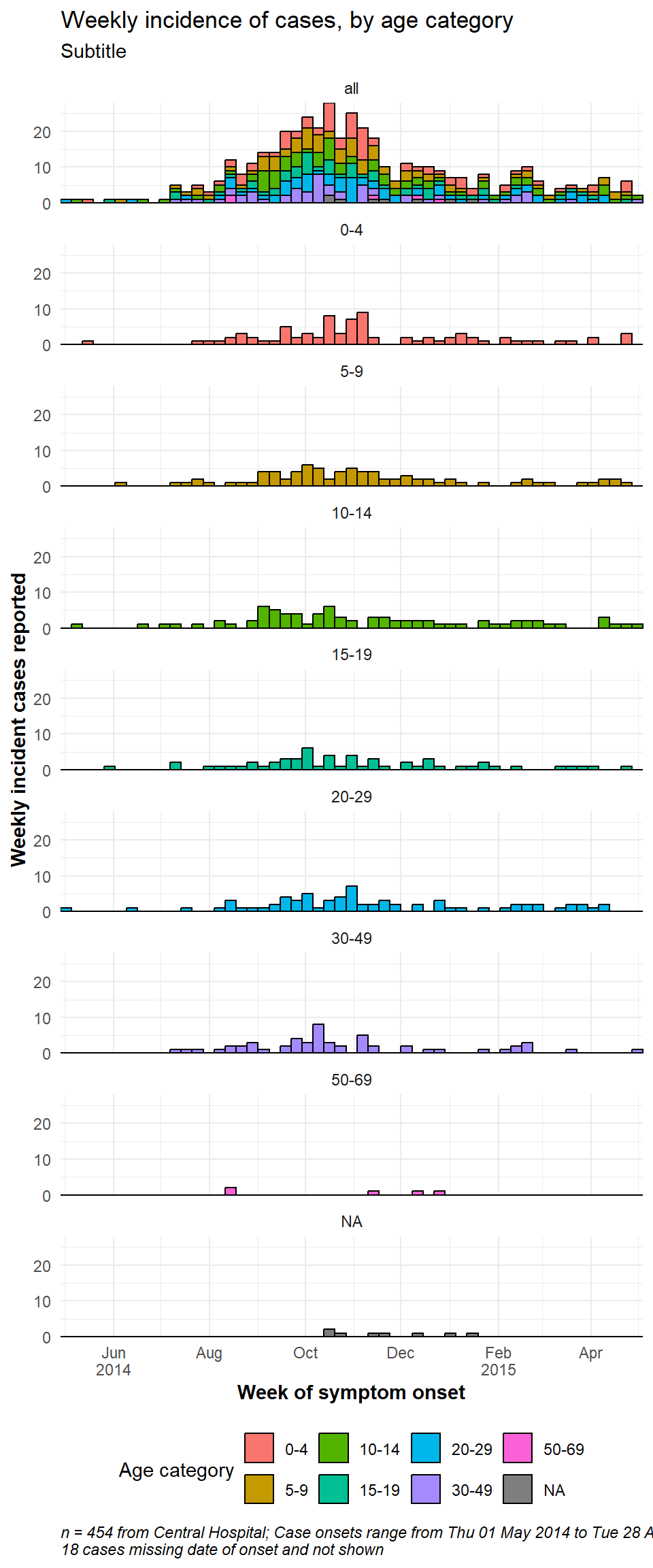
32.3 暫定データ
流行曲線で示される最新のデータは、多くの場合、暫定的な値であり、報告遅れのために後から症例数が追加される可能性があることを明示した方が良いでしょう。これは、直近の日数分を垂直線や長方形で囲むことで行うことができます。ここでは、2 つの方法を紹介します。
-
annotate()の使用:- 線の場合は
annotate(geom = "segment")を使用します。x、xend、y、yendを指定し、サイズ、線の種類(lty)、色を調整します。
- 長方形の場合は
annotate(geom = "rect")を使用します。 xmin/xmax/ymin/ymax を指定し、色とアルファ値を調整します。
- 線の場合は
データを暫定的なステータスでグループ化し、それらのビンを異なる色で表示します。
注意:長方形を作成するために geom_rect() を試すかも知れませんが、ラインリストの場合は上手くいきません。この関数は、各観測点・行に対して 1 つの長方形を重ねる関数です!非常に低いアルファ値(例えば 0.01)を使用するか、他の方法を用いてください。
annotate() の使用
annotate(geom = "rect")内で、xminとxmaxに日付型の引数を指定する必要があります。これらのデータは週単位のビンに集約されており、最後のビンは最後のデータポイントの次の月曜日まで伸びているので、影がかったエリアは4週間をカバーしているように見えるかもしれないことに注意してください。
annotate()の例は こちら を参考にしてください。
ggplot(central_data) +
# ヒストグラム
geom_histogram(
mapping = aes(x = date_onset),
breaks = weekly_breaks_central, # 以前のコードで定義済み
closed = "left", # 分割の開始から症例数をカウントする
color = "darkblue",
fill = "lightblue") +
# scales
scale_y_continuous(expand = c(0,0))+
scale_x_date(
expand = c(0,0), # X軸の前後の余分なスペースを削除
date_breaks = "1 month", # 月の最初の日
date_minor_breaks = "1 month", # 月の最初の日
label = scales::label_date_short())+ # 日付ラベルのフォーマット
# ラベルとテーマの指定
labs(
title = "Using annotate()\nRectangle and line showing that data from last 21-days are tentative",
x = "Week of symptom onset",
y = "Weekly case indicence")+
theme_minimal()+
# 暫定データに対して半透明の影をかける
annotate(
"rect",
xmin = as.Date(max(central_data$date_onset, na.rm = T) - 21), # 日付型である必要があることに注意
xmax = as.Date(Inf), # 日付型である必要があることに注意
ymin = 0,
ymax = Inf,
alpha = 0.2, # annotate()では alpha 値で直感的に簡単に透明度を変えられる
fill = "red")+
# 黑の縦線を追加する
annotate(
"segment",
x = max(central_data$date_onset, na.rm = T) - 21, # 最終日の21日前
xend = max(central_data$date_onset, na.rm = T) - 21,
y = 0, # 線がy = 0 の場所から始まるように指定
yend = Inf, # 線が一番上まで続くように指定
size = 2, # 線の太さを指定
color = "black",
lty = "solid")+ # 線の種類 (例; "solid", "dashed")
# 長方形の中に文字を追加
annotate(
"text",
x = max(central_data$date_onset, na.rm = T) - 15,
y = 15,
label = "Subject to reporting delays",
angle = 90)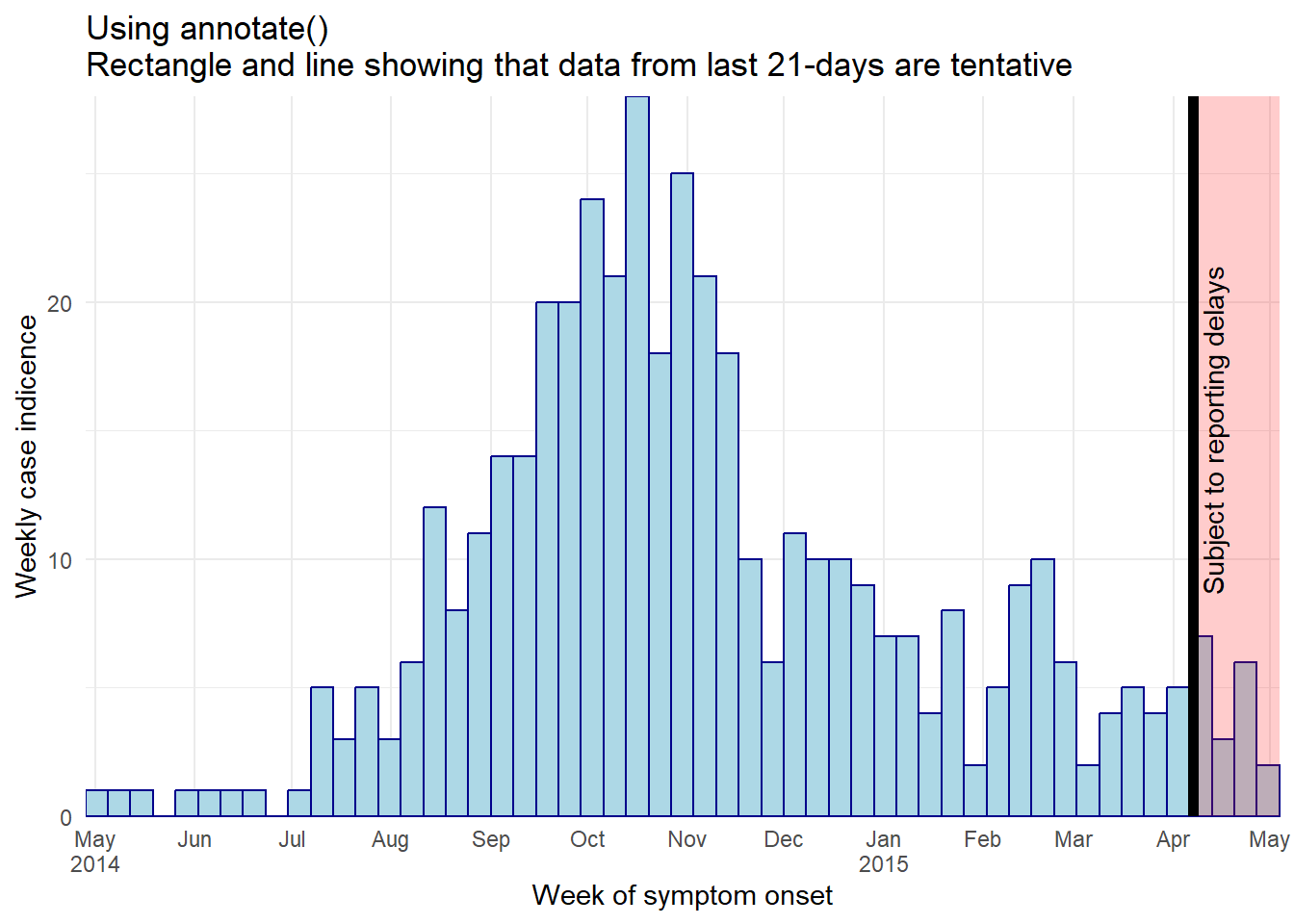
黒い縦線の追加は以下のコードでも可能ですが、以下のように geom_vline() を使うと、高さは調整できなくなります。
geom_vline(xintercept = max(central_data$date_onset, na.rm = T) - 21,
size = 2,
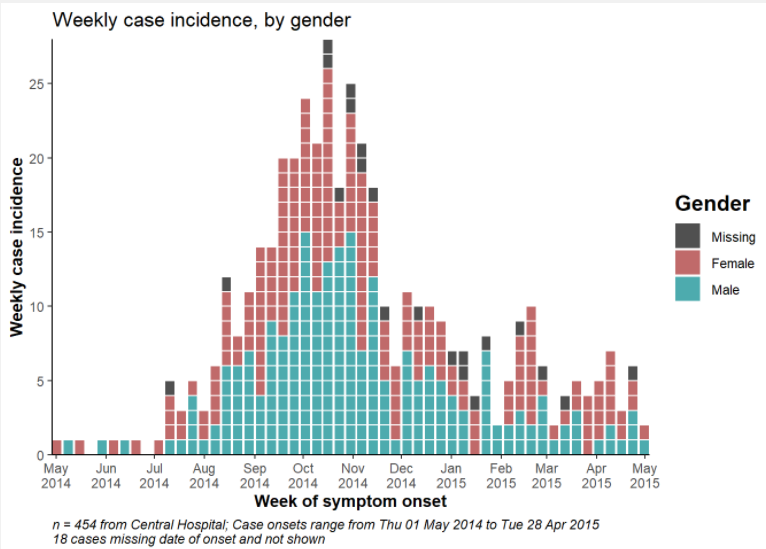
color = "black")ビンの色を変える
別の方法として、暫定データが反映されたビン自体の色や表示を調整することもできます。データ前処理の段階で新しい列を作り、作成した新しい列を使ってデータをグループ化し、暫定データの aes(fill = ) を他の棒グラフと異なる色やアルファ値にすることができます。
# 列の追加
############
plot_data <- central_data %>%
mutate(tentative = case_when(
date_onset >= max(date_onset, na.rm=T) - 7 ~ "Tentative", # 直近7日分の データは暫定である
TRUE ~ "Reliable")) # それ以外は 暫定ではない
# プロット
######
ggplot(plot_data, aes(x = date_onset, fill = tentative)) +
# ヒストグラム
geom_histogram(
breaks = weekly_breaks_central, # 以前のコードで定義済み
closed = "left", # 分割の開始から症例数をカウントする
color = "black") +
# scales
scale_y_continuous(expand = c(0,0))+
scale_fill_manual(values = c("lightblue", "grey"))+
scale_x_date(
expand = c(0,0), # X軸の前後の余分なスペースを削除
date_breaks = "3 weeks", # データを3週ごとに表示
date_minor_breaks = "week", # 縦罫線を1週ごとに表示
label = scales::label_date_short())+ # 日付ラベルのフォーマット
# ラベルとテーマの指定
labs(title = "Show days that are tentative reporting",
subtitle = "")+
theme_minimal()+
theme(legend.title = element_blank()) # 凡例のタイトルを削除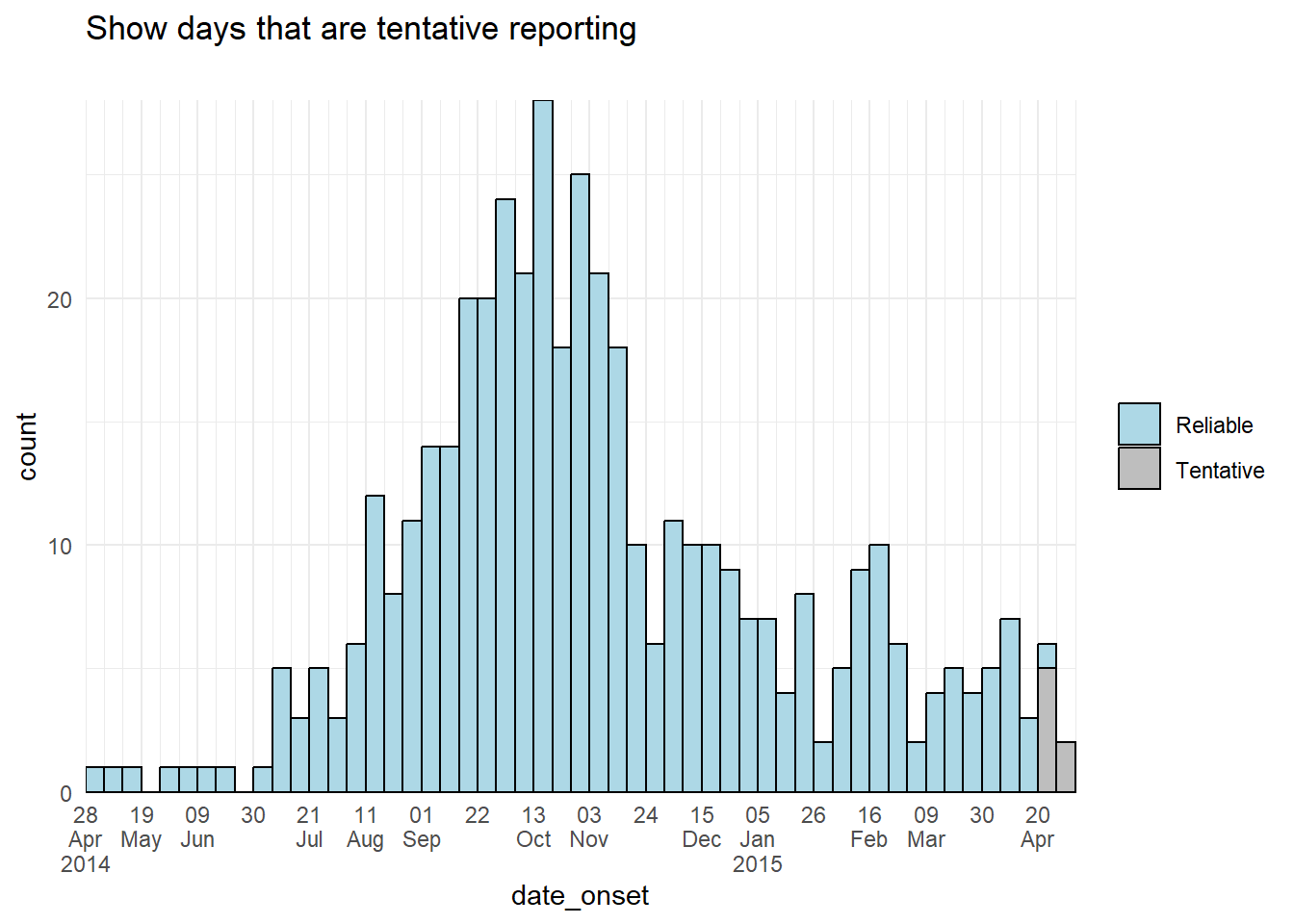
32.4 複数の日付ラベル
月や年など複数レベルの日付ラベルを、下位のラベルと重複することなく表示したい場合は、以下の方法のいずれかを試してみて下さい。
date_labels や labels の引数で、各ラベルの一部を下の行に配置するために \n 使うことができることも可能です。しかし、以下のコードを使うと、年や月を下の行に、かつ一度のみ表示することが可能です。
まず、最も簡単な方法は、scales パッケージの関数 label_date_short() を、scale_x_date() 内の labels = 引数に使用することです(注意:以下の例ように空の括弧 () を含めることを忘れないようにしてください)。 label_date_short() は、効率的な日付ラベルを自動的に作成します(詳しくは こちら のウェブサイトをご覧ください)。この関数のもう一つの特長は、データが日、週、月、年と時間と共に拡大していくのに応じて、ラベルが自動的に調整されることです。
ggplot(central_data) +
# histogram
geom_histogram(
mapping = aes(x = date_onset),
breaks = weekly_breaks_central, # 以前のコードで定義済み (ggplot セクション参照)
closed = "left", # 分割の開始から症例数をカウントする
color = "darkblue",
fill = "lightblue") +
# y-axis scale as before
scale_y_continuous(expand = c(0,0))+
# x-axis scale sets efficient date labels
scale_x_date(
expand = c(0,0), # X軸の前後の余分なスペースを削除
labels = scales::label_date_short())+ # 自動的に日付ラベルを生成
# labels and theme
labs(
title = "Using label_date_short()\nTo make automatic and efficient date labels",
x = "Week of symptom onset",
y = "Weekly case indicence")+
theme_minimal()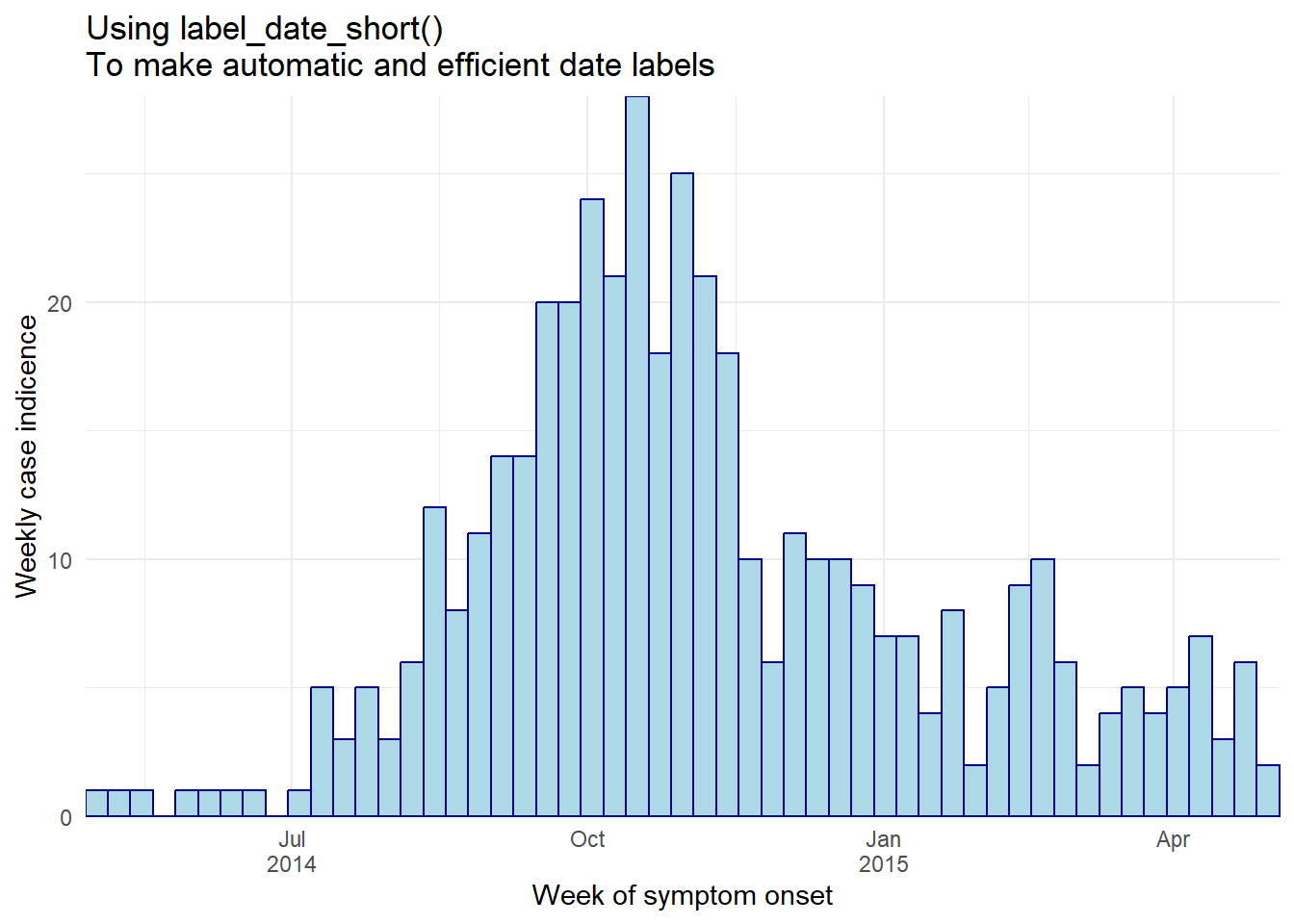
もう一つの方法は、以下のようにファセット化を行うことです。
症例数は、外観上の理由から週単位で集計されています。詳細は、本章の「集計データ」のセクションを参照して下さい。
ヒストグラムの代わりに
geom_area()が使われていますが、これは、以下のファセット化のアプローチがヒストグラムではうまく機能しないためです。
週別にデータをカウント
# 週別にデータをカウントしたデータセットを作成
#######################################
central_weekly <- linelist %>%
filter(hospital == "Central Hospital") %>% # フィルター
mutate(week = lubridate::floor_date(date_onset, unit = "weeks")) %>%
count(week) %>% # 週別にカウント
drop_na(week) %>% # 発症日不明症例を除外
complete( # 症例が一例もなかった週を0で埋める
week = seq.Date(
from = min(week),
to = max(week),
by = "week"),
fill = list(n = 0)) # NAを0に変換グラフの作成
# 軸タイトルの年に対して枠線なしのグラフの作成
#################################
ggplot(central_weekly,
aes(x = week, y = n)) + # xとyを全プロットに対して指定
geom_line(stat = "identity", # カウントデータを用いて線グラフを作成
color = "#69b3a2") + # 線グラフの色
geom_point(size=1, color="#69b3a2") + # 週ごとに点を作成
geom_area(fill = "#69b3a2", # 線グラフの下のエリアを塗りつぶす
alpha = 0.4)+ # 塗りつぶしの透明度の指定
scale_x_date(date_labels="%b", # 日付ラベルのフォーマット(月名を示す)
date_breaks="month", # 日付ラベルを月ごとで分割
expand=c(0,0)) + # X軸の前後の余分なスペースを削除
scale_y_continuous(
expand = c(0,0))+ # y軸の前後の余分なスペースを削除
facet_grid(~lubridate::year(week), # (日付列の)年でファセット
space="free_x",
scales="free_x", # x軸をデータの範囲で調整(ファセット間で固定しない)
switch="x") + # ファセットのラベルを下に持ってくる
theme_bw() +
theme(strip.placement = "outside", # ファセットのラベルの場所
strip.background = element_blank(), # ファセットの背景の塗りつぶしをなくす
panel.grid.minor.x = element_blank(),
panel.border = element_blank(), # ファセットの境界線をなくす
panel.spacing=unit(0,"cm"))+ # ファセット間のスペースをなくす
labs(title = "Nested year labels - points, shaded, no label border")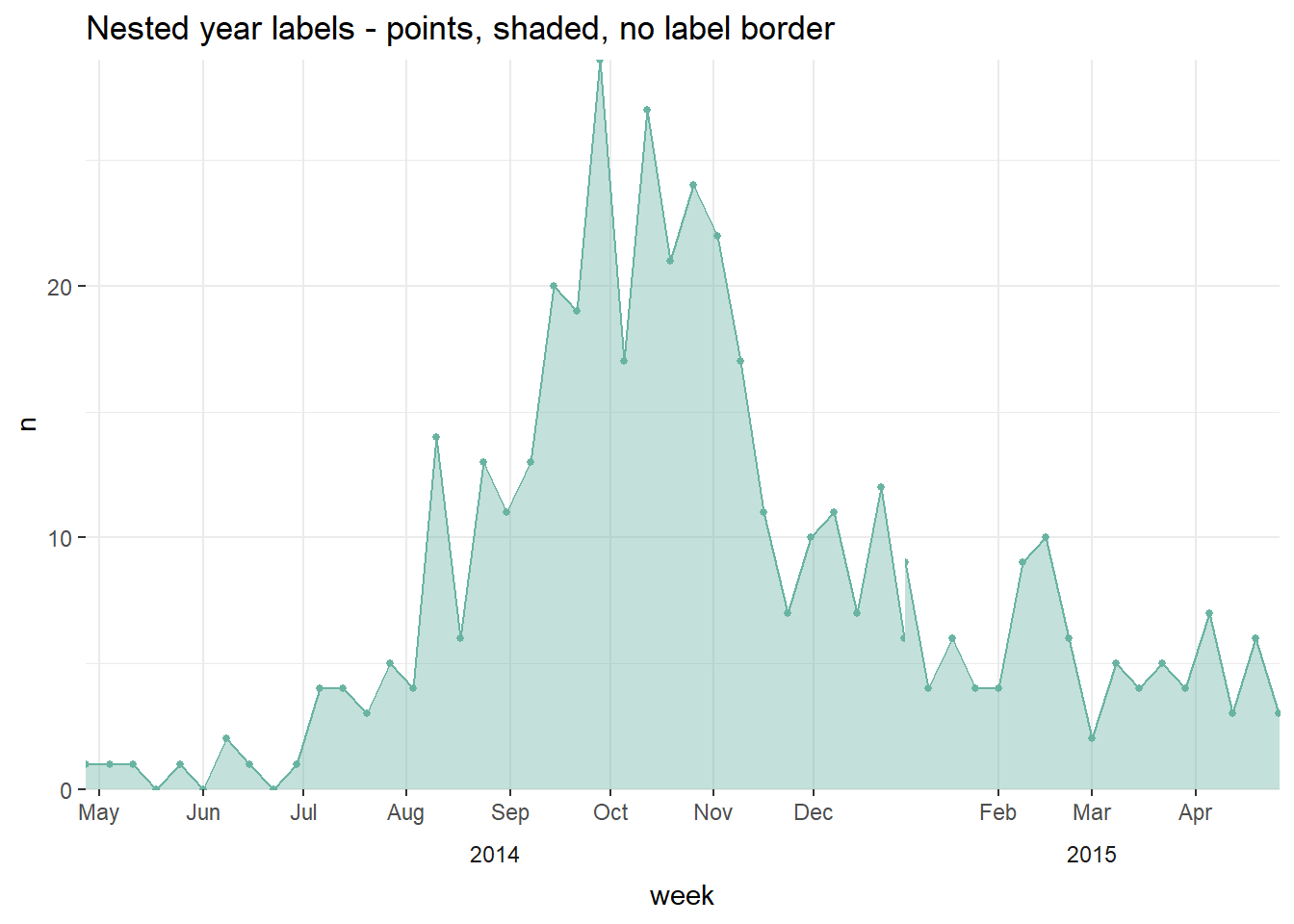
32.5 2軸グラフ
データ可視化のコミュニティー内では、2 軸グラフの有効性について激しい議論が交わされていますが、流行曲線やそれに類するグラフで、2 軸目に割合を重ねたものを見たいと思う疫学専門家は依然として多くいます。これについては ggplot のヒント の章で詳しく説明していますが、cowplot メソッドを使った一例を以下に示します。
- 2 つの異なるプロットを作成し、cowplot パッケージで結合します。
- 2 つのプロットはまったく同じ x 軸(範囲を設定する)を持つ必要があり、そうでないとデータとラベルがずれてしまいます。
- それぞれ
theme_cowplot()を使用し、一方は y 軸をプロットの右側に移動します。
# パッケージの読み込み
pacman::p_load(cowplot)
# 最初の流行曲線を作成
#######################################
plot_cases <- linelist %>%
# 週別の症例をプロット
ggplot()+
# ヒストグラムの作成
geom_histogram(
mapping = aes(x = date_onset),
# 最初の症例の前の月曜から、最後の症例の次の月曜までが含まれる週ごとのビン分割を指定
breaks = weekly_breaks_all)+ # 以前に定義した週ごとの日付のベクトル
# もう一つのグラフとの整合性を保つための最初と最後の日付の指定
scale_x_date(
limits = c(min(weekly_breaks_all), max(weekly_breaks_all)))+ # 最初と最後の日付の指定
# ラベル
labs(
y = "Daily cases",
x = "Date of symptom onset"
)+
theme_cowplot()
# 2つ目のグラフ(週ごとの死亡割合)の作成
###########################################
plot_deaths <- linelist %>% # ラインリスト
group_by(week = floor_date(date_onset, "week")) %>% # week 列を作成
# 週ごとの死亡割合を集計
summarise(n_cases = n(),
died = sum(outcome == "Death", na.rm=T),
pct_died = 100*died/n_cases) %>%
# プロット
ggplot()+
# 週ごとの死亡割合の線グラフ
geom_line( # 週ごとの死亡割合の線グラフの作成
mapping = aes(x = week, y = pct_died), # y軸に pct_died 列を指定
stat = "identity", # 行番号(デフォルト)ではなく、pct_death 列をy軸に指定
size = 2,
color = "black")+
# 最初のグラフと同じx軸の範囲にする
scale_x_date(
limits = c(min(weekly_breaks_all), max(weekly_breaks_all)))+ # 最初と最後の日付の指定
# y軸の調整
scale_y_continuous( # y軸の調整
breaks = seq(0,100, 10), # 軸の分割をパーセント用に設定する
limits = c(0, 100), # 軸の範囲をパーセント用に設定する
position = "right")+ # 軸を右に持ってくる
# x軸のラベルを削除し、y軸のラベルを指定する
labs(x = "",
y = "Percent deceased")+ # %軸のラベル
theme_cowplot() # 2つのプロットを良い感じに重ねる次に cowplot を使って 2 つのプロットを重ね合わせます。x 軸を合わせること、y 軸のサイド、theme_cowplot() の使い方に注目してください。
aligned_plots <- cowplot::align_plots(plot_cases, plot_deaths, align="hv", axis="tblr")
ggdraw(aligned_plots[[1]]) + draw_plot(aligned_plots[[2]])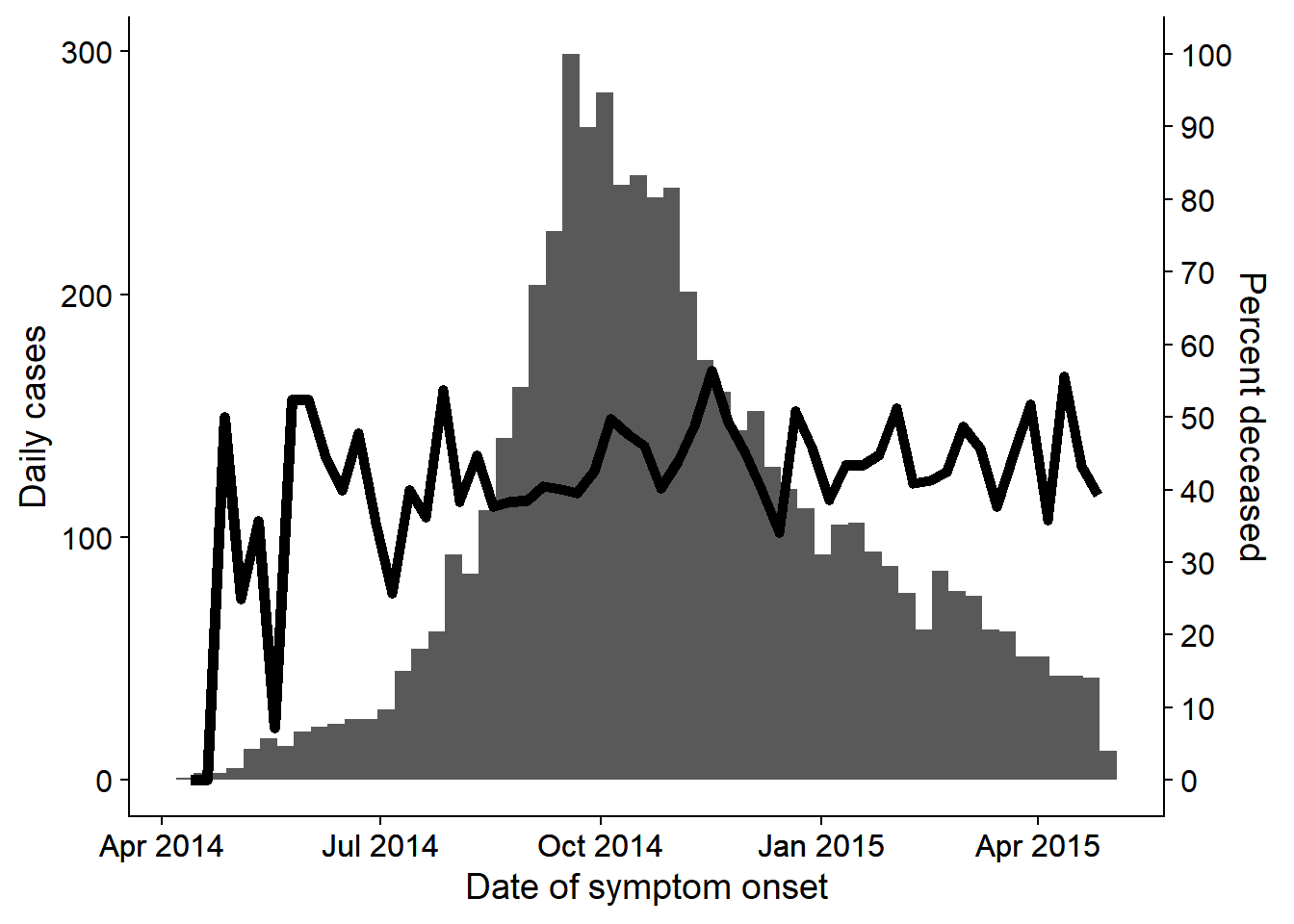
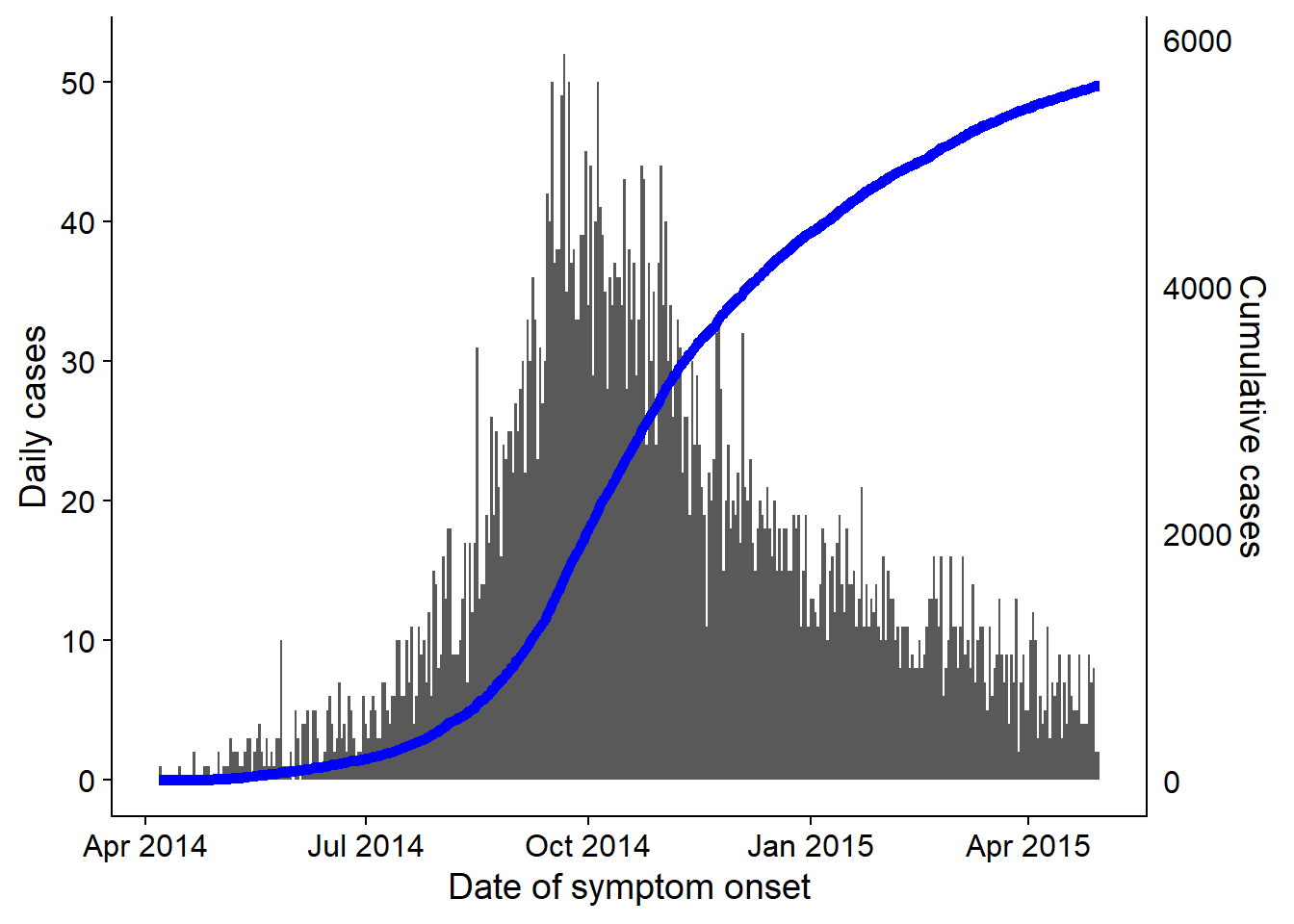
32.6 累積症例数
症例のラインリストから始める場合、R base の cumsum() を使用して\、アウトブレイクにおける日ごとの累積症例数の列を新たに作成します。
cumulative_case_counts <- linelist %>%
count(date_onset) %>% # 日ごとの症例数("n"列)
mutate(
cumulative_cases = cumsum(n) # 日ごとの累積症例数列
)最初の 10 行は以下のようになります。
この累積症例数の列は、geom_line() を使用して、date_onset 列に対してプロットすることができます。
plot_cumulative <- ggplot()+
geom_line(
data = cumulative_case_counts,
aes(x = date_onset, y = cumulative_cases),
size = 2,
color = "blue")
plot_cumulative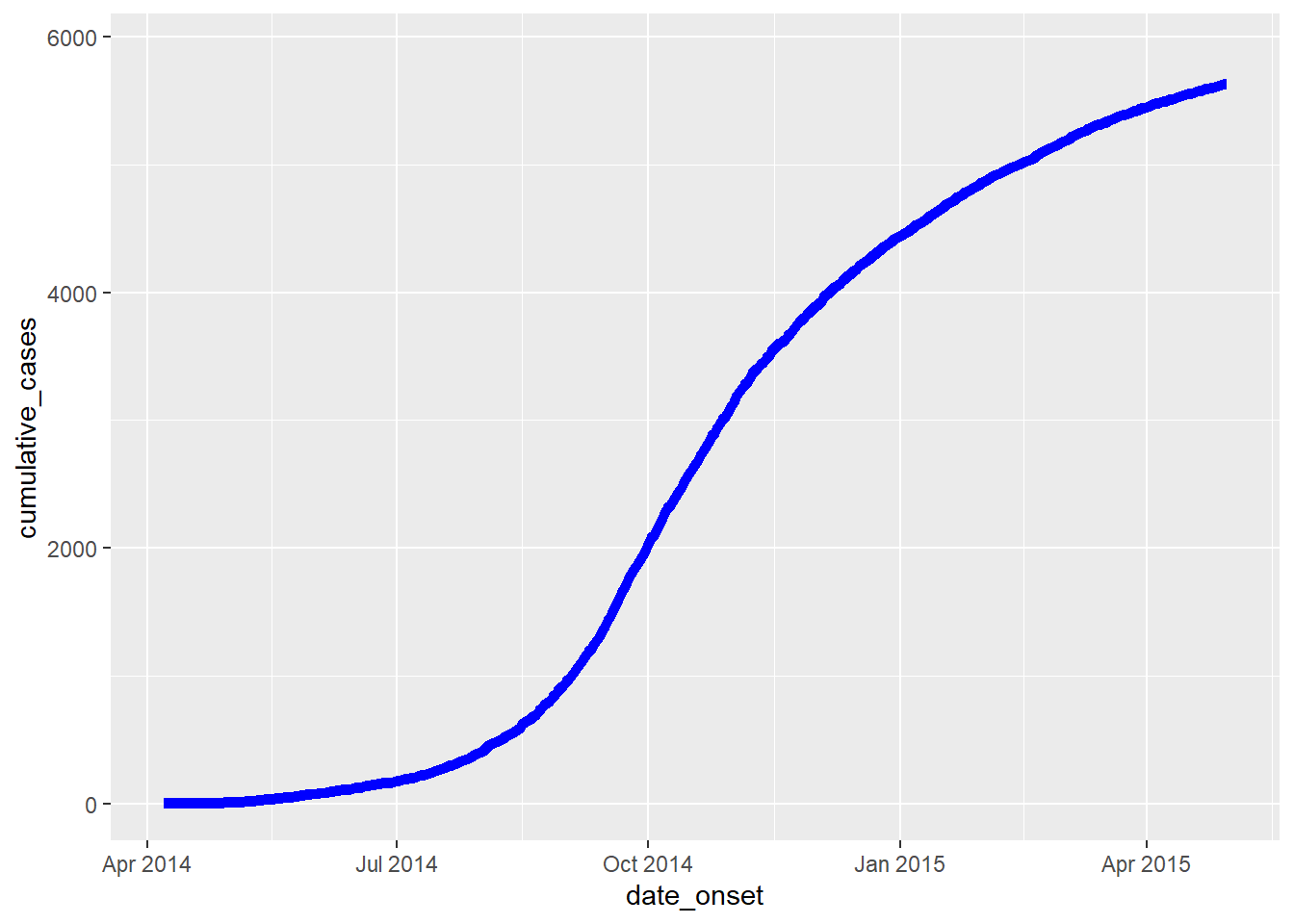
また、上記や ggplot の基礎 の章で説明されている cowplot を使って、2 軸で流行曲線に重ねることもできます。
#パッケージの読み込み
pacman::p_load(cowplot)
# 最初のグラフである流行曲線を作成
plot_cases <- ggplot()+
geom_histogram(
data = linelist,
aes(x = date_onset),
binwidth = 1)+
labs(
y = "Daily cases",
x = "Date of symptom onset"
)+
theme_cowplot()
# 2つ目のグラフである累積症例数の線グラフを作成
plot_cumulative <- ggplot()+
geom_line(
data = cumulative_case_counts,
aes(x = date_onset, y = cumulative_cases),
size = 2,
color = "blue")+
scale_y_continuous(
position = "right")+
labs(x = "",
y = "Cumulative cases")+
theme_cowplot()+
theme(
axis.line.x = element_blank(),
axis.text.x = element_blank(),
axis.title.x = element_blank(),
axis.ticks = element_blank())次に cowplot を使って 2 つのプロットを重ね合わせます。x 軸を合わせること、y 軸のサイド、theme_cowplot() の使い方に注意してください。
aligned_plots <- cowplot::align_plots(plot_cases, plot_cumulative, align="hv", axis="tblr")
ggdraw(aligned_plots[[1]]) + draw_plot(aligned_plots[[2]])