pacman::p_load(
rio, # importar dados
here, # caminhos relativos de arquivos
janitor, # limpeza dos dados e tabelas
lubridate, # trabalhar com datas
epikit, # função age_categories()
apyramid, # piramides etárias
tidyverse, # manipulação e visualização de dados
RColorBrewer, # paletas de cores
formattable, # formatação de tabelas
kableExtra # formatação de tabelas
)25 Rastreamento de contatos
Esta página demonstra uma análise descritiva dos dados de rastreio de contatos, acrescentando algumas considerações-chave e abordagens únicas a este tipo de dados.
Esta página faz referência a muitas das competências centrais de gestão e visualização de dados em R, cobertas em outras páginas (por exemplo, limpeza de dados, pivoteamento, tabelas, análises de séries temporais). Contudo, destacaremos exemplos específicos de rastreio de contatos que têm sido úteis para a tomada de decisões operacionais. Por exemplo, está inclusa a visualização de dados de seguimento de rastreio de contatos ao longo do tempo ou através de áreas geográficas, ou a produção de tabelas de Indicadores de Desempenho Chave (KPI, do inglês Key Performance Indicator) limpas para supervisores de rastreio de contatos.
Para fins de demonstração, utilizaremos amostras de dados de rastreio de contatos da plataforma Go.Data. Os princípios aqui abordados serão aplicados aos dados de rastreio de contatos de outras plataformas - você poderá apenas precisar passar por diferentes etapas de pré-processamento de dados, dependendo da estrutura da base.
Leia mais sobre o projeto Go.Data no site Github Documentation site ou Community of Practice.
25.1 Preparação
Carregar pacotes
Esta chunck mostra o carregamento dos pacotes necessários para as análises. Neste manual damos ênfase a função p_load() do pacman, que instala o pacote se necessário e carrega-o para utilização. Também se pode carregar pacotes instalados com library() a partir do R base. Veja a página Introdução ao R para mais informações sobre pacotes R.
Importação de dados
Importaremos amostras de conjuntos de dados de contatos e de seus “acompanhamentos”. Estes dados foram recuperados e separados da API Go.Data e armazenados como arquivos “.rds”.
Você pode fazer o download de todos os dados de exemplo para este manual a partir da página Download do manual e dados.
Se desejar fazer o download do exemplo de dados de rastreio de contatos específicos para esta página, utilize os três links de download abaixo:
Clique para fazer o download dos dados da investigação do caso (arquivo .rds)
Clique para fazer o download dos dados de registo de contato (arquivo .rds)
Clique para fazer o download dos dados de acompanhamento dos contatos (arquivo .rds)
Na sua forma original nos arquivos passíveis de download, os dados são exibidos como fornecidos pela API do Go.Data (saiba mais sobre APIs aqui). Para fins de exemplo, aqui vamos limpar os dados para facilitar a leitura nesta página. Se estiver usando uma extensão Go.Data, pode ver instruções completas sobre como recuperar os seus dados aqui.
Abaixo, os conjuntos de dados são importados utilizando a função import() do pacote rio. Veja a página Importar e exportar para várias formas de importação de dados. Utilizamos here() para especificar o caminho do arquivo - forneça o caminho específico do arquivo para o seu computador. Em seguida, utilizamos select() para selecionar apenas certas colunas dos dados, simplificando para efeitos de demonstração.
Dados do caso
Estes dados são uma tabela com informações sobre os casos.
cases <- import(here("data", "godata", "cases_clean.rds")) %>%
select(case_id, firstName, lastName, gender, age, age_class,
occupation, classification, was_contact, hospitalization_typeid)Aqui estão os casos nrow(cases):
Dados de contatos
Estes dados são uma tabela de todos os contatos e suas informações. Mais uma vez, forneça o seu próprio caminho para o arquivo. Após a importação, realizamos alguns passos preliminares de limpeza de dados, incluindo:
- Definir a age_class (faixa-etária) como fator e inverter a ordem desses níveis, de modo que as idades menores sejam as primeiras a aparecer;
- Selecionar apenas algumas colunas específicas, ao mesmo tempo que se renomeia uma delas;
- Atribuir artificialmente às linhas cuja coluna
admin_2_nameestiver o nome “Djembe”, melhorando a clareza da visualização de alguns exemplos;
contacts <- import(here("data", "godata", "contacts_clean.rds")) %>%
mutate(age_class = forcats::fct_rev(age_class)) %>%
select(contact_id, contact_status, firstName, lastName, gender, age,
age_class, occupation, date_of_reporting, date_of_data_entry,
date_of_last_exposure = date_of_last_contact,
date_of_followup_start, date_of_followup_end, risk_level, was_case, admin_2_name) %>%
mutate(admin_2_name = replace_na(admin_2_name, "Djembe"))Aqui estão as linhas nrow(contacts) da base de dados contacts:
Dados de acompanhamento
Esses dados são registros das interações de “acompanhamento” (follow-up) com os contatos. Espera-se que cada contato tenha um encontro de onitoramento a cada dia durante 14 dias após sua exposição.
Importamos a base e executamos algumas etapas de limpeza. Selecionamos certas colunas e também convertemos uma coluna de caracteres em todos os valores em minúsculas.
followups <- rio::import(here::here("data", "godata", "followups_clean.rds")) %>%
select(contact_id, followup_status, followup_number,
date_of_followup, admin_2_name, admin_1_name) %>%
mutate(followup_status = str_to_lower(followup_status))Aqui estão as primeiras 50 linhas do conjunto de dados da fila de acompanhamento (nrow(followups)). Cada linha é uma interação de acompanhamento, com o status do resultado na coluna followup_status:
Dados de relação
Aqui importamos os dados mostrando a relação entre os casos e contatos. Selecionamos certas colunas para demonstrar.
relationships <- rio::import(here::here("data", "godata", "relationships_clean.rds")) %>%
select(source_visualid, source_gender, source_age, date_of_last_contact,
date_of_data_entry, target_visualid, target_gender,
target_age, exposure_type)Abaixo estão as primeiras 50 linhas da base de dados relationships, que contém todas as relações entre casos e contatos.
25.2 Análises descritivas
Você pode utilizar as técnicas abordadas em outras páginas deste manual para realizar análises descritivas dos seus casos, contatos e respectivas relações. Abaixo estão alguns exemplos.
Demográficos
Como demonstrado neste manual Pirâmides demográficas, é possível visualizar a idade e a distribuição por sexo (aqui utilizamos o pacote apyramid).
Idade e Gênero dos contatos
A pirâmide abaixo compara a distribuição etária dos contatos, por sexo. Note que contatos com idades faltosas (missing) estão inclusos em uma barra no topo. Você pode alterar este comportamento padrão, mas depois considere listar os valores ausentes (“missing”) em uma legenda.
apyramid::age_pyramid(
data = contacts, # usar base de dados de contatos
age_group = "age_class", # coluna de faixa-etária
split_by = "gender") + # lados da pirâmide divididos por gênero
labs(
fill = "Gender", # título da legenda
title = "Age/Sex Pyramid of COVID-19 contacts")+ # título da figura
theme_minimal() # plano de fundo simples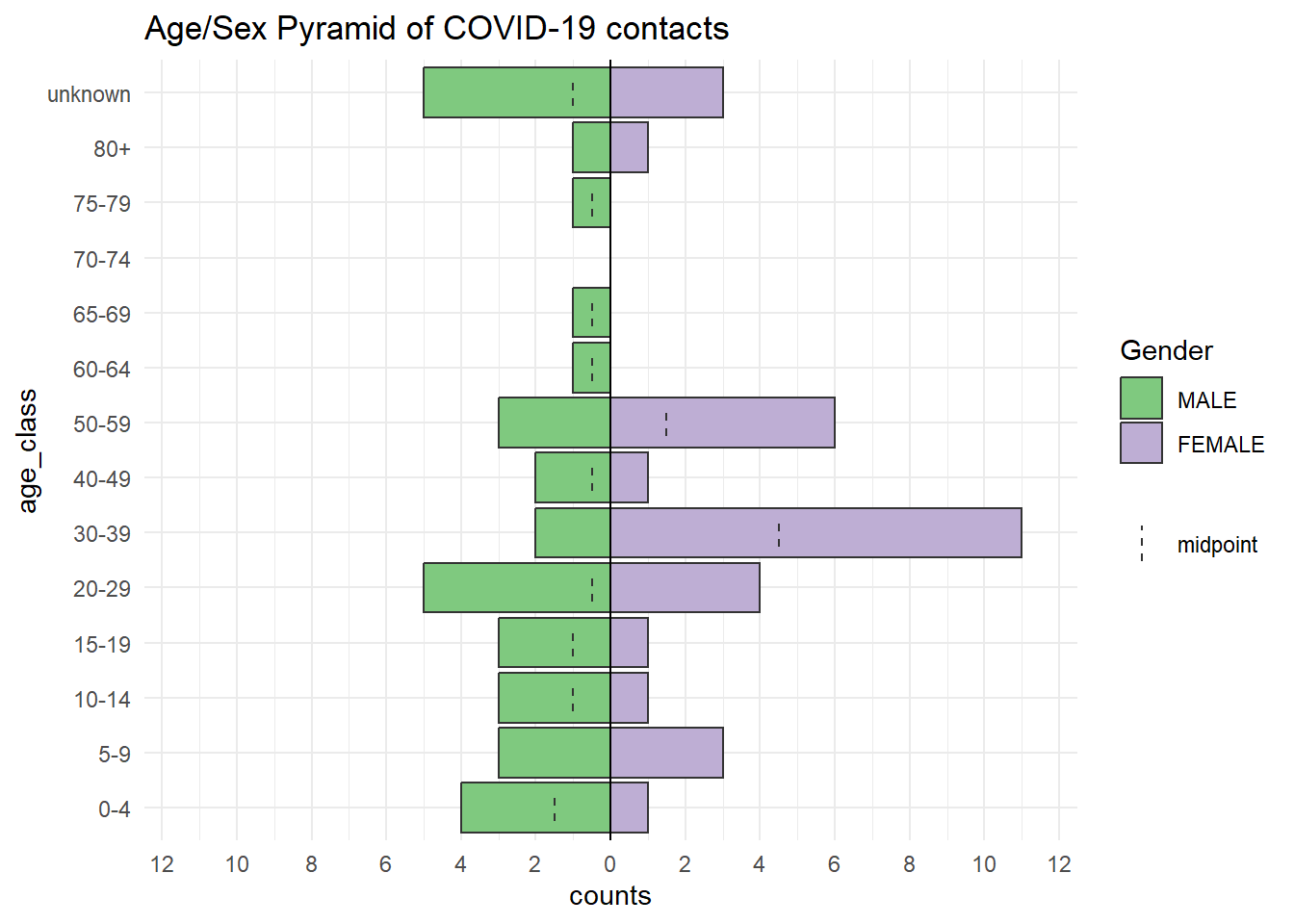
Com a estrutura de dados Go.Data, o conjunto de dados relationships contém as idades de ambos os casos e contatos, para que você pudesse utilizar esse conjunto de dados e criar uma pirâmide de idades mostrando as diferenças entre esses dois grupos de pessoas. A base relationships será alterada para transformar as colunas numéricas de idade em categorias, ou seja, faixas-etárias (veja a página Dados de limpeza e principais funções). Também pivotamos a base de dados de forma mais longa, para facilitar a criaçãodo gráfico com ggplot2 (ver Pivotando dados).
relation_age <- relationships %>%
select(source_age, target_age) %>%
transmute( # transmute é como a função mutate(), mas remove todas as outras colunas não mencionadas
source_age_class = epikit::age_categories(source_age, breakers = seq(0, 80, 5)),
target_age_class = epikit::age_categories(target_age, breakers = seq(0, 80, 5)),
) %>%
pivot_longer(cols = contains("class"), names_to = "category", values_to = "age_class")# pivotação longa
relation_age# A tibble: 200 × 2
category age_class
<chr> <fct>
1 source_age_class 80+
2 target_age_class 15-19
3 source_age_class <NA>
4 target_age_class 50-54
5 source_age_class <NA>
6 target_age_class 20-24
7 source_age_class 30-34
8 target_age_class 45-49
9 source_age_class 40-44
10 target_age_class 30-34
# ℹ 190 more rowsAgora podemos traçar este conjunto de dados transformados com a função age_pyramid() como antes, mas substituindo gênder por category (Caso, ou Contato).
apyramid::age_pyramid(
data = relation_age, # usar a base de dados modificada `reltionship`
age_group = "age_class", # coluna categórica de idade
split_by = "category") + # dividir por casos e contatos
scale_fill_manual(
values = c("orange", "purple"), # para especificar cores E nomes
labels = c("Caso", "Contato"))+
labs(
fill = "Legend", # título da legenda
title = "Pirâmide Idade/Sexo de casos e contatos de COVID-19")+ # título da figura
theme_minimal() # plano de fundo simples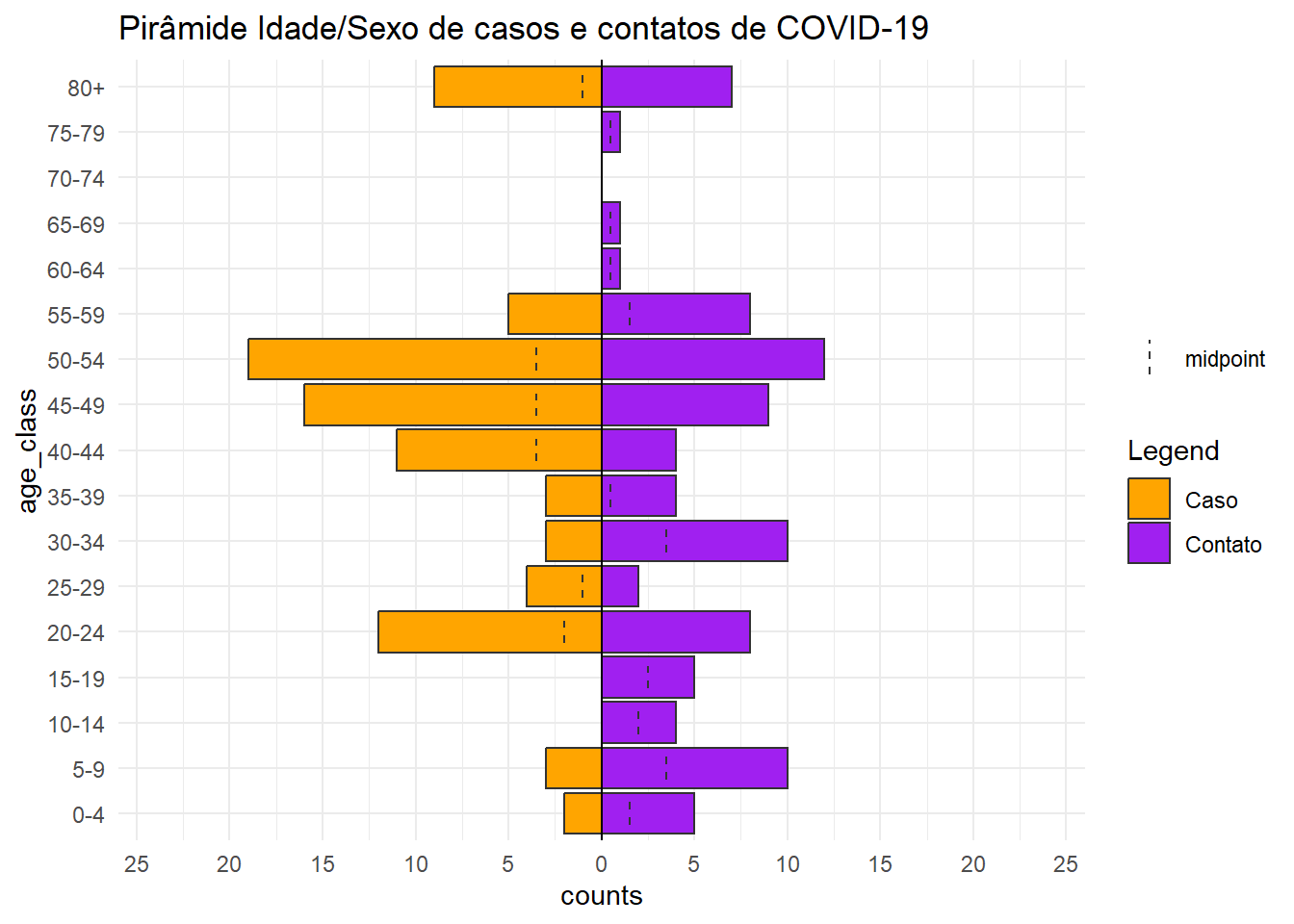
Também podemos ver outras características, como a discriminação por ocupação (ex. em forma de gráfico de setores).
# Limpar a base de dados e contar as ocupações
occ_plot_data <- cases %>%
mutate(occupation = forcats::fct_explicit_na(occupation), # fazer valores NA e vazios uma categoria
occupation = forcats::fct_infreq(occupation)) %>% # ordenar em níveis, em ordem de frequência
count(occupation) # contagens por ocupação
# fazer gráfico de setores
ggplot(data = occ_plot_data, mapping = aes(x = "", y = n, fill = occupation))+
geom_bar(width = 1, stat = "identity") +
coord_polar("y", start = 0) +
labs(
fill = "Ocupação",
title = "Ocupações conhecidadas de casos de COVID-19")+
theme_minimal() +
theme(axis.line = element_blank(),
axis.title = element_blank(),
axis.text = element_blank())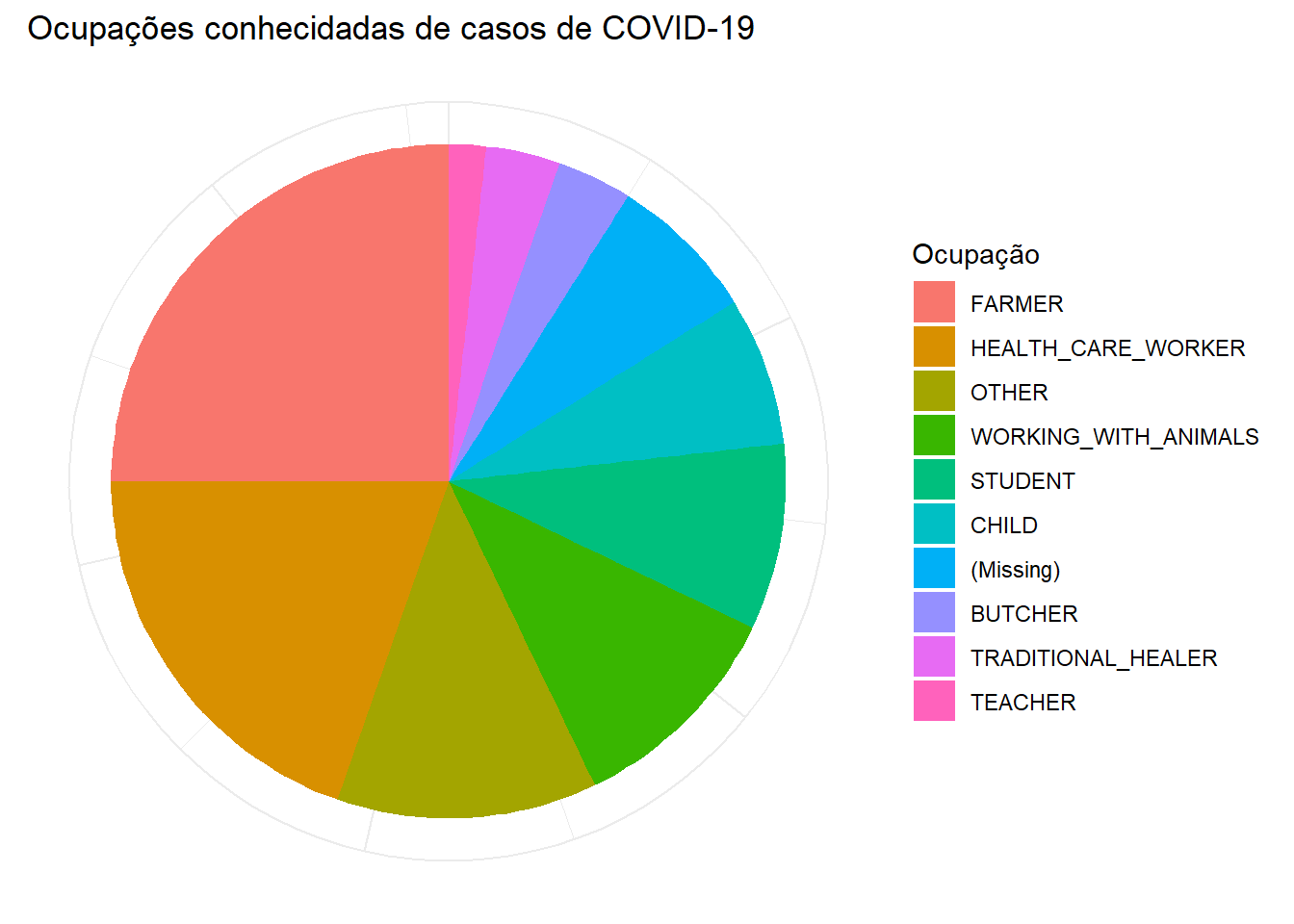
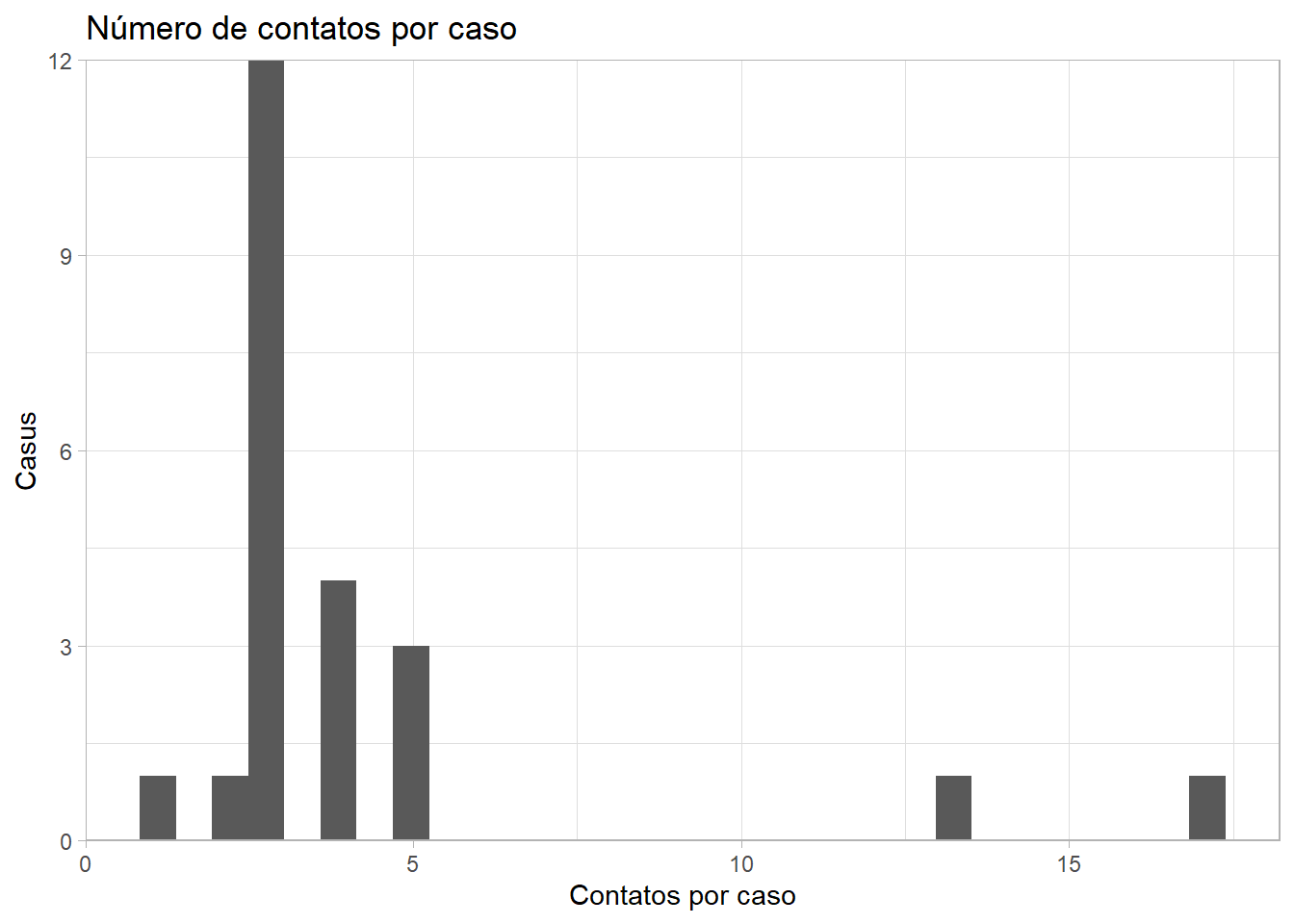
Contatos por caso
O número de contatos por caso pode ser uma métrica importante para avaliar qualidade da contagem de contatos e a conformidade da população para uma resposta de saúde pública.
Dependendo de sua estrutura de dados, isto pode ser avaliado com um conjunto de dados que contém todos os casos e contatos. Nos conjuntos de dados Go.Data, os links entre os casos (“fontes”) e os contatos (“alvos”) é armazenado no conjunto de dados relationships.
Neste conjunto de dados, cada linha é um contato, e o caso da fonte é listado em uma linha. Não há contatos que tenham relações com múltiplos casos, mas se isso existir, você pode precisar computá-los antes de criar o gráfico.
Começamos contando o número de linhas (contatos) por caso de origem. Isto é salvo como um data frame.
contacts_per_case <- relationships %>%
count(source_visualid)
contacts_per_case source_visualid n
1 CASE-2020-0001 13
2 CASE-2020-0002 5
3 CASE-2020-0003 2
4 CASE-2020-0004 4
5 CASE-2020-0005 5
6 CASE-2020-0006 3
7 CASE-2020-0008 3
8 CASE-2020-0009 3
9 CASE-2020-0010 3
10 CASE-2020-0012 3
11 CASE-2020-0013 5
12 CASE-2020-0014 3
13 CASE-2020-0016 3
14 CASE-2020-0018 4
15 CASE-2020-0022 3
16 CASE-2020-0023 4
17 CASE-2020-0030 3
18 CASE-2020-0031 3
19 CASE-2020-0034 4
20 CASE-2020-0036 1
21 CASE-2020-0037 3
22 CASE-2020-0045 3
23 <NA> 17Podemos usar geom_histogram() para fazer um histograma a partir desses dados.
ggplot(data = contacts_per_case)+ # começar com a contagem da base de dados criada anteriormente
geom_histogram(mapping = aes(x = n))+ # criar o histograma do número de contatos por caso
scale_y_continuous(expand = c(0,0))+ # remover o espaço em excesso abaixo de 0 no eixo y
theme_light()+ # simplificar o plano de fundo
labs(
title = "Número de contatos por caso",
y = "Casus",
x = "Contatos por caso"
)
25.3 Acompanhamento de contato
Os dados de rastreamento de contatos geralmente contêm dados de “acompanhamento”, que registram resultados das verificações diárias dos sintomas das pessoas em quarentena. Análises destes dados podem informar a estratégia de resposta, identificar contatos em risco de perda no acompanhamento ou risco de desenvolver doenças.
Limpeza do dados
Estes dados podem existir em uma variedade de formatos, como um formato Excel “largo/amplo”, com uma linha por contato e uma coluna por dia de acompanhamento. Veja Pivoteando dados para descrições de dados “longos” e “largos”, e como pivotar dados mais amplos/largos ou mais longos.
Em nosso exemplo com Go.Data, estes dados são armazenados nos dados de acompanhamento (followups), em um formato “longo”, com uma linha por acompanhamento interação. As primeiras 50 filas são dessa forma:
CUIDADO: Cuidado com as duplicatas ao lidar com dados de acompanhamento; podem haver vários seguimentos errôneos no mesmo dia para um determinado contato. Talvez pareça um erro, mas reflete a realidade - por exemplo, um investigador poderia submeter um formulário de acompanhamento no início do dia, quando não foi possível contactar o indivíduo e, mais tarde, submeter um segundo formulário quando conseguir contato. Dependerá do contexto operacional a forma como você quer lida com duplicatas - apenas certifique-se de documentar sua abordagem claramente.
Vamos ver quantas linhas “duplicadas” nós temos:
followups %>%
count(contact_id, date_of_followup) %>% # obter valores únicos para dias de contato (contact_days)
filter(n > 1) # ver registros onde a contagem é maior que 1 contact_id date_of_followup n
1 <NA> 2020-09-03 2
2 <NA> 2020-09-04 2
3 <NA> 2020-09-05 2Em nossos dados de exemplo, os únicos registros aos quais isto se aplica são os que faltam um ID! Podemos removê-los. Mas, para fins de demonstração vamos mostrar os passos para remoção de duplicidades, de forma que haja apenas um acompanhamento por pessoa por dia. Para mais detalhes, veja a página Eliminando duplicidades. Vamos supor que o registro mais recente é o correto. Também aproveitamos a oportunidade para limpar a coluna followup_number (o “dia” de acompanhamento que deve variar de 1 - 14).
followups_clean <- followups %>%
# Remover duplicidades
group_by(contact_id, date_of_followup) %>% # agrupar linhas por dia de contato (contact-day)
arrange(contact_id, desc(date_of_followup)) %>% # organizar linhas por dia de contato, data de acompanhamento (date of follow-up), trazendo o mais recente para o topo
slice_head() %>% # manter apenas a primeira linha por valor único de ID do contato (contact id)
ungroup() %>%
# Outras limpezas
mutate(followup_number = replace(followup_number, followup_number > 14, NA)) %>% # limpar dados errados
drop_na(contact_id) # remover linhas com valor em branco para contact_idPara cada encontro de acompanhamento, temos um status de acompanhamento (por exemplo se o encontro ocorreu e se o contato teve sintomas ou não). Para ver todos os valores, podemos executar um rápido tabyl() (do janitor) ou table() (do R Base) (ver Tabelas descritivas) por ‘followup_status’ para ver a frequência de cada um dos resultados.
Neste conjunto de dados, “seen_not_ok” significa “visto com sintomas” e “seen_ok” significa “visto sem sintomas”
followups_clean %>%
tabyl(followup_status) followup_status n percent
missed 10 0.02325581
not_attempted 5 0.01162791
not_performed 319 0.74186047
seen_not_ok 6 0.01395349
seen_ok 90 0.20930233Gráfico ao longo do tempo
Como os dados das datas são contínuos, usaremos um histograma para representá-los com a data de acompanhamento (date_of_followup) atribuída ao eixo x. Podemos produzir um histograma “empilhado”, especificando um argumento fill = dentro de aes(), que atribuímos à coluna de status do acompanhamento (followup_status). Consequentemente, você pode definir o título da legenda utilizando o argumento fill = do labs().
Podemos ver que os contatos foram identificados em ondas (presumivelmente correspondente às ondas epidêmicas de casos), e que a conclusão do acompanhamento não parece ter melhorado ao longo do curso da epidemia.
ggplot(data = followups_clean)+
geom_histogram(mapping = aes(x = date_of_followup, fill = followup_status)) +
scale_fill_discrete(drop = FALSE)+ # exibir todos os níveis de fatores (followup_status) na legenda, mesmo os não utilizados
theme_classic() +
labs(
x = "",
y = "Número de contatos",
title = "Status de acompanhamento de contato diário",
fill = "Status de acompanhamento",
subtitle = str_glue("Dados de {max(followups$date_of_followup, na.rm=T)}")) # subtítulo dinâmico subtitle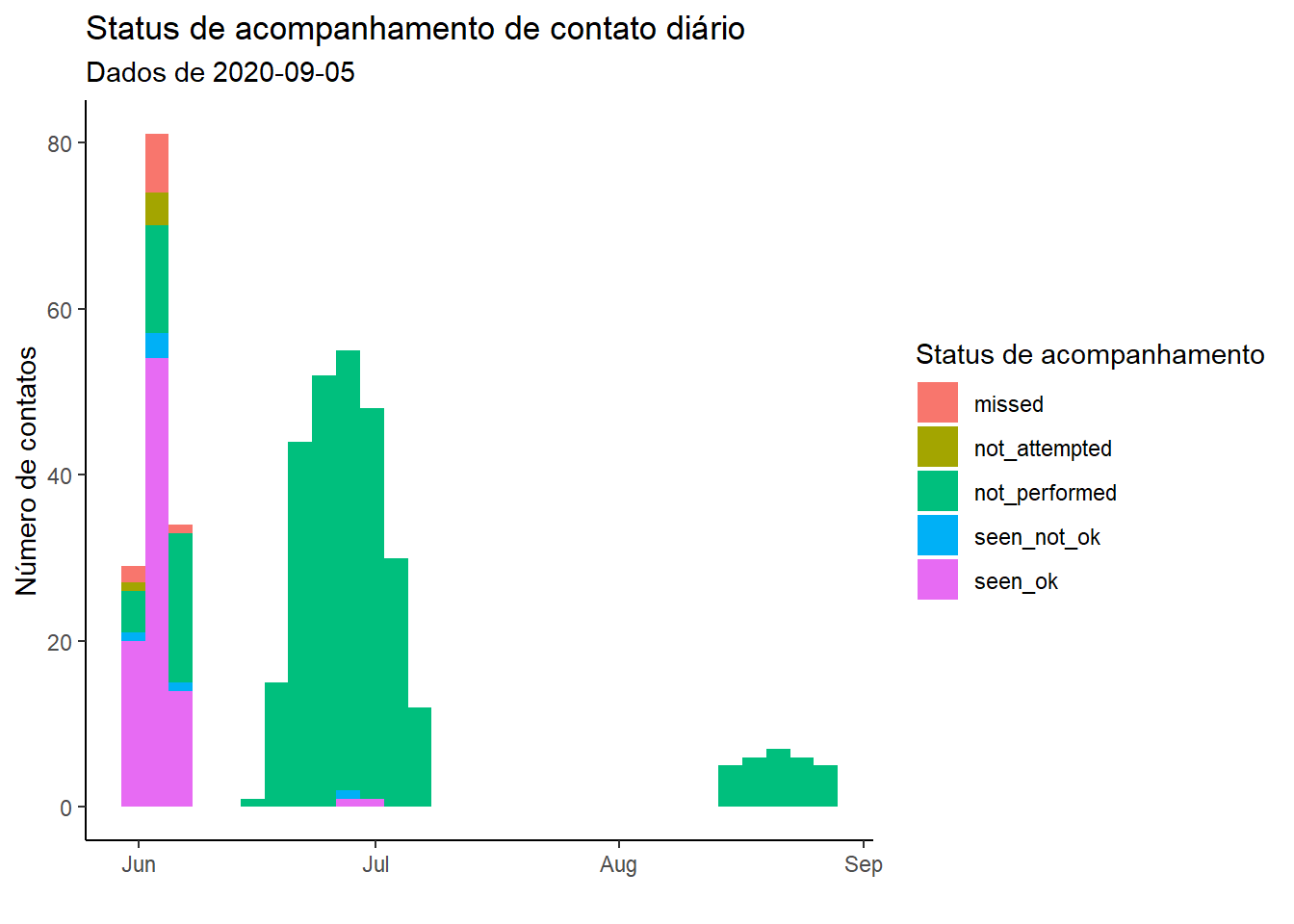
CUIDADO: Se você estiver preparando muitos gráficos (por exemplo, para múltiplas jurisdições) é preferível que as legendas apareçam de forma idêntica, mesmo com diferentes níveis de preenchimento ou composição de dados. Podem haver gráficos para os quais nem todos os status de acompanhamento estão presentes nos dados, mas você ainda quer que essas categorias apareçam nas legendas. Em ggplots (como acima), você pode especificar o argumento drop = FALSE do scale_fill_discrete(). Nas tabelas, utilize tabyl() que mostra contagens para todos os níveis de fatores, ou se utilizandocount() do dplyr adicione o argumento .drop = FALSE para incluir contagens para todos os níveis de fatores.
Rastreamento individual diário
Se seu surto for pequeno o suficiente, pode ser interessante olhar para cada contato individualmente e ver seu status ao longo de seu acompanhamento. Felizmente, este conjunto de dados followups já contém uma coluna com o “número” do dia de acompanhamento (de 1 a 14). Se isto não existir em seus dados, você poderia criá-lo calculando a diferença entre a data do contato e a data que o acompanhamento foi planejado para começar.
Um mecanismo de visualização conveniente (se o número de casos não for muito grande) pode ser um gráfico de calor, feito com geom_tile(). Veja mais detalhes na página Gráfico de calor.
ggplot(data = followups_clean)+
geom_tile(mapping = aes(x = followup_number, y = contact_id, fill = followup_status),
color = "grey")+ # linhas de grade na cor cinza
scale_fill_manual( values = c("yellow", "grey", "orange", "darkred", "darkgreen"))+
theme_minimal()+
scale_x_continuous(breaks = seq(from = 1, to = 14, by = 1))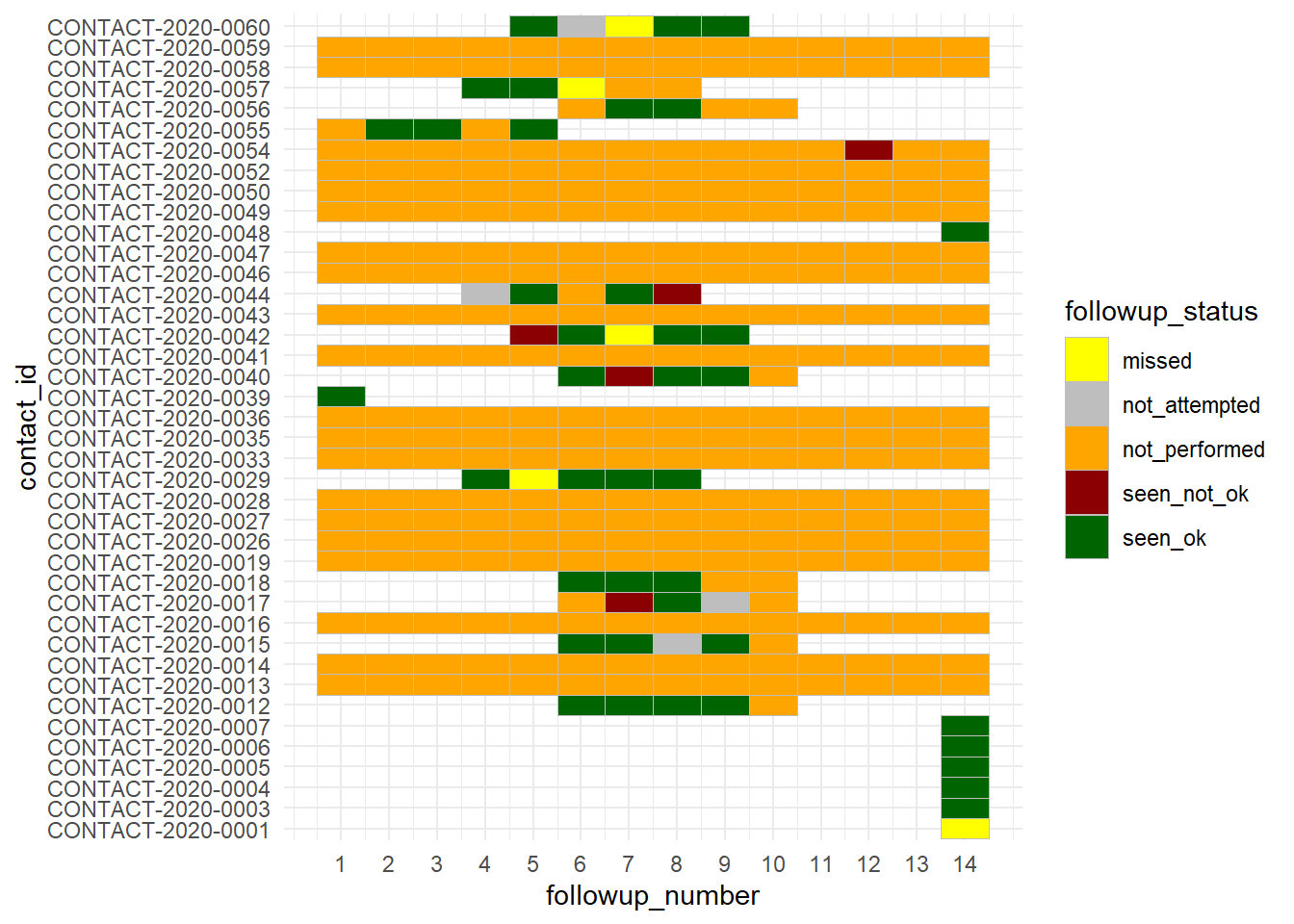
Análises por grupo
Talvez esses dados de acompanhamento estejam sendo vistos diariamente ou semanalmente para a tomada de decisões operacionais. Você pode considerar mais significativo a desagregação por área geográfica ou por equipe de rastreamento de contatos. Podemos fazer isso ajustando as colunas fornecidas no group_by().
plot_by_region <- followups_clean %>% # começar com a base de dados de acompanhamento
count(admin_1_name, admin_2_name, followup_status) %>% # contagem por valores únicos no "region-status" (cria coluna 'n' com a contagem )
# iniciar o ggplot()
ggplot( # iniciar o ggplot
mapping = aes(x = reorder(admin_2_name, n), # reordenar os níveis dos fatores de administração pelos valores numéricos na coluna 'n'
y = n, # altura das barras segundo coluna 'n'
fill = followup_status, # cor da barra empilhada segundo seu status
label = n))+ # transição para o geom_label()
geom_col()+ # barras empilhadas, vindo do mapeamento anterior
geom_text( # adicionar texto, vindo do mapeamento anterior
size = 3,
position = position_stack(vjust = 0.5),
color = "white",
check_overlap = TRUE,
fontface = "bold")+
coord_flip()+
labs(
x = "",
y = "Número de contatos",
title = "Status do acompanhamento do contato, por Região",
fill = "Status do acompanhamento",
subtitle = str_glue("Dados de {max(followups_clean$date_of_followup, na.rm=T)}")) +
theme_classic()+ # Plano de fundo simplificado
facet_wrap(~admin_1_name, strip.position = "right", scales = "free_y", ncol = 1) # introduzir facetas
plot_by_region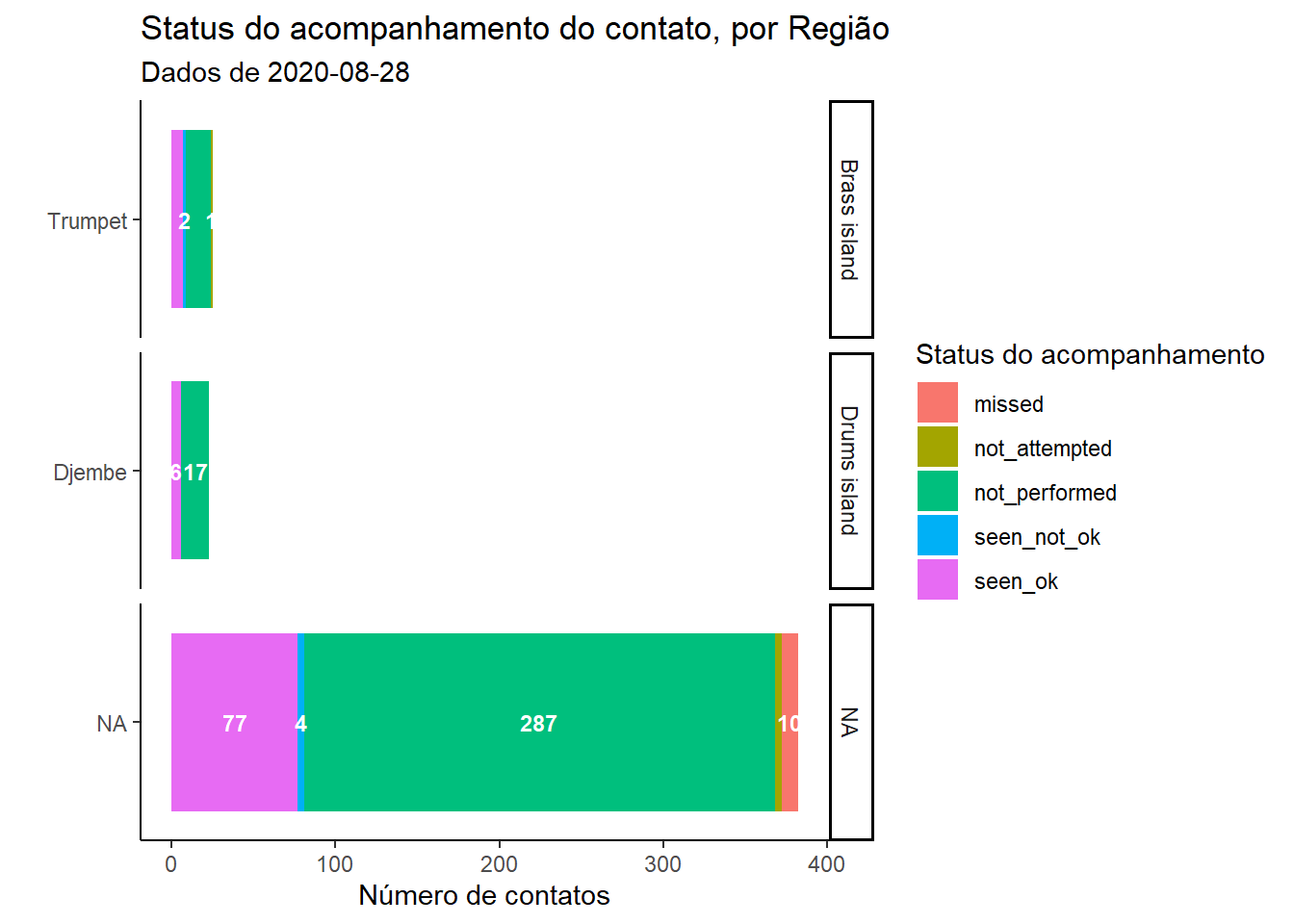
25.4 Tabelas KPI
Há uma série de diferentes indicadores-Chave de Desempenho (KPIs, de Key Performance Indicators em inglês) que podem ser calculados e rastreados em diferentes níveis de desagregação e ao longo de diferentes períodos de tempo para monitorar o desempenho do rastreamento de contatos. Uma vez que você tenha os cálculos e o formato básico da tabela; é bastante fácil trocar por diferentes KPIs.
Existem várias fontes de rastreamento de contatos KPIs, tais como este (de ResolveToSaveLives.org).A maior parte do trabalho será caminhar através de sua estrutura de dados e pensar em todos os critérios de inclusão/exclusão. Mostramos alguns exemplos abaixo; usando a estrutura de metadados Go.Data:
| Categoria | Indicador | Numerador Go.Data | Denominador Go.Data |
|---|---|---|---|
| Indicador de processo (Velocidade de rastreio do contato) | % casos entrevistados e isolados em até 24h da informação | COUNT OF case_id WHERE (date_of_reporting - da te_of_data_entry) < 1 dia E (is olation_startdate - da te_of_data_entry) < 1 day |
COUNT OF case_id
|
| Indicador de processo - velocidade de rastreio do contato | % de contatos notificados e em quarentena em até 24h da exposição | COUNT OF contact_id WHERE followup_status == “SEEN_NOT_OK” OR “SEEN_OK” AND date_of_followup - date_of_reporting < 1 day |
COUNT OF contact_id
|
| Indicador de processo - Completude da testagem | % de novos casos sintomaticos testados e entrevistados em até 3 dias do início de sintomas | COUNT OF case_id WHERE (date_of_reporting - date_of_onset) < =3 days |
COUNT OF case_id
|
| Indicador de resultados - Geral | % novos casos entre lista de contatos existente | COUNT OF case_id WHERE was_contact == “TRUE” |
COUNT OF case_id
|
Abaixo, iremos passar por um exercício de exemplo de criação de uma tabela que mostra o acompanhamento dos contatos ao longo de áreas administrativas. No final, tornaremos essa tabela apresentável com o pacote formattable (mas você poderia usar outros pacotes, como flextable - veja Tabelas para apresentação).
A criação de tabelas como esta, dependerá da sua estrutura de dados de rastreamento de contatos. Visite a página Tabelas descritivas para aprender como resumir os dados usando as funções do dplyr.
Criaremos uma tabela que será dinâmica e mudará de acordo com a mudança dos dados. Para tornar os resultados interessantes, estabeleceremos uma data de relato (report_date), que nos permite simular o funcionamento da tabela em um determinado dia (escolhemos 10 de Junho de 2020). Os dados são filtrados até essa data.
# Criar a "Report date" para simular simular a execução do relatório com dados "a partir" desta data
report_date <- as.Date("2020-06-10")
# Criar dados de acompanhamento para refletir a data do relatório
table_data <- followups_clean %>%
filter(date_of_followup <= report_date)Agora, com base em nossa estrutura de dados, faremos o seguinte:
- Comece com os
followupse use o summarise para que contenha, em cada contato único:
- A data do último registro (não importa o status do encontro)
- A data do último encontro em que o contato foi “visto”
- O status do encontro naquela última vez em que o contato foi “visto” (por exemplo, com sintomas ou sem sintomas)
- Junte estes dados aos dados de contato, que contêm outras informações como o status geral de contato, data do último exposição a um caso, etc. Também calcularemos as métricas de interesse para cada contato, tais como dias desde a última exposição
- Agrupamos os dados de contato melhorados por região geográfica (
admin_2_name) e calculamos estatísticas resumidas por região - Finalmente, formatamos a tabela para apresentação
Primeiro resumimos os dados de acompanhamento para obter as informações de interesse:
followup_info <- table_data %>%
group_by(contact_id) %>%
summarise(
date_last_record = max(date_of_followup, na.rm=T),
date_last_seen = max(date_of_followup[followup_status %in% c("seen_ok", "seen_not_ok")], na.rm=T),
status_last_record = followup_status[which(date_of_followup == date_last_record)]) %>%
ungroup()Aqui vemos os dados:
Agora vamos adicionar essas informações à base de dados contacts e calcular algumas colunas adicionais
contacts_info <- followup_info %>%
right_join(contacts, by = "contact_id") %>%
mutate(
database_date = max(date_last_record, na.rm=T),
days_since_seen = database_date - date_last_seen,
days_since_exposure = database_date - date_of_last_exposure
)Aqui vemos a aparência dos dados. Observe a coluna contacts à direita e a nova coluna calculada na extrema direita.
A seguir, resumimos os dados de contato por região, para obter uma base concisa de colunas estatísticas resumidas.
contacts_table <- contacts_info %>%
group_by(`Admin 2` = admin_2_name) %>%
summarise(
`Registered contacts` = n(),
`Active contacts` = sum(contact_status == "UNDER_FOLLOW_UP", na.rm=T),
`In first week` = sum(days_since_exposure < 8, na.rm=T),
`In second week` = sum(days_since_exposure >= 8 & days_since_exposure < 15, na.rm=T),
`Became case` = sum(contact_status == "BECAME_CASE", na.rm=T),
`Lost to follow up` = sum(days_since_seen >= 3, na.rm=T),
`Never seen` = sum(is.na(date_last_seen)),
`Followed up - signs` = sum(status_last_record == "Seen_not_ok" & date_last_record == database_date, na.rm=T),
`Followed up - no signs` = sum(status_last_record == "Seen_ok" & date_last_record == database_date, na.rm=T),
`Not Followed up` = sum(
(status_last_record == "NOT_ATTEMPTED" | status_last_record == "NOT_PERFORMED") &
date_last_record == database_date, na.rm=T)) %>%
arrange(desc(`Registered contacts`))E agora aplicamos estilos dos pacotes formattable e knitr, incluindo uma nota de rodapé que mostra a data “a partir de”.
contacts_table %>%
mutate(
`Admin 2` = formatter("span", style = ~ formattable::style(
color = ifelse(`Admin 2` == NA, "red", "grey"),
font.weight = "bold",font.style = "italic"))(`Admin 2`),
`Followed up - signs`= color_tile("white", "orange")(`Followed up - signs`),
`Followed up - no signs`= color_tile("white", "#A0E2BD")(`Followed up - no signs`),
`Became case`= color_tile("white", "grey")(`Became case`),
`Lost to follow up`= color_tile("white", "grey")(`Lost to follow up`),
`Never seen`= color_tile("white", "red")(`Never seen`),
`Active contacts` = color_tile("white", "#81A4CE")(`Active contacts`)
) %>%
kable("html", escape = F, align =c("l","c","c","c","c","c","c","c","c","c","c")) %>%
kable_styling("hover", full_width = FALSE) %>%
add_header_above(c(" " = 3,
"Contatos atualmente em acompanhamento" = 5,
"Status na última visita" = 3)) %>%
kableExtra::footnote(general = str_glue("Data are current to {format(report_date, '%b %d %Y')}"))| Admin 2 | Registered contacts | Active contacts | In first week | In second week | Became case | Lost to follow up | Never seen | Followed up - signs | Followed up - no signs | Not Followed up |
|---|---|---|---|---|---|---|---|---|---|---|
| Djembe | 59 | 30 | 44 | 0 | 2 | 15 | 22 | 0 | 0 | 0 |
| Trumpet | 3 | 1 | 3 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| Venu | 2 | 0 | 0 | 0 | 2 | 0 | 2 | 0 | 0 | 0 |
| Congas | 1 | 0 | 0 | 0 | 1 | 0 | 1 | 0 | 0 | 0 |
| Cornet | 1 | 0 | 1 | 0 | 1 | 0 | 1 | 0 | 0 | 0 |
| Note: | ||||||||||
| Data are current to Jun 10 2020 |
25.5 Matrizes de transmissão
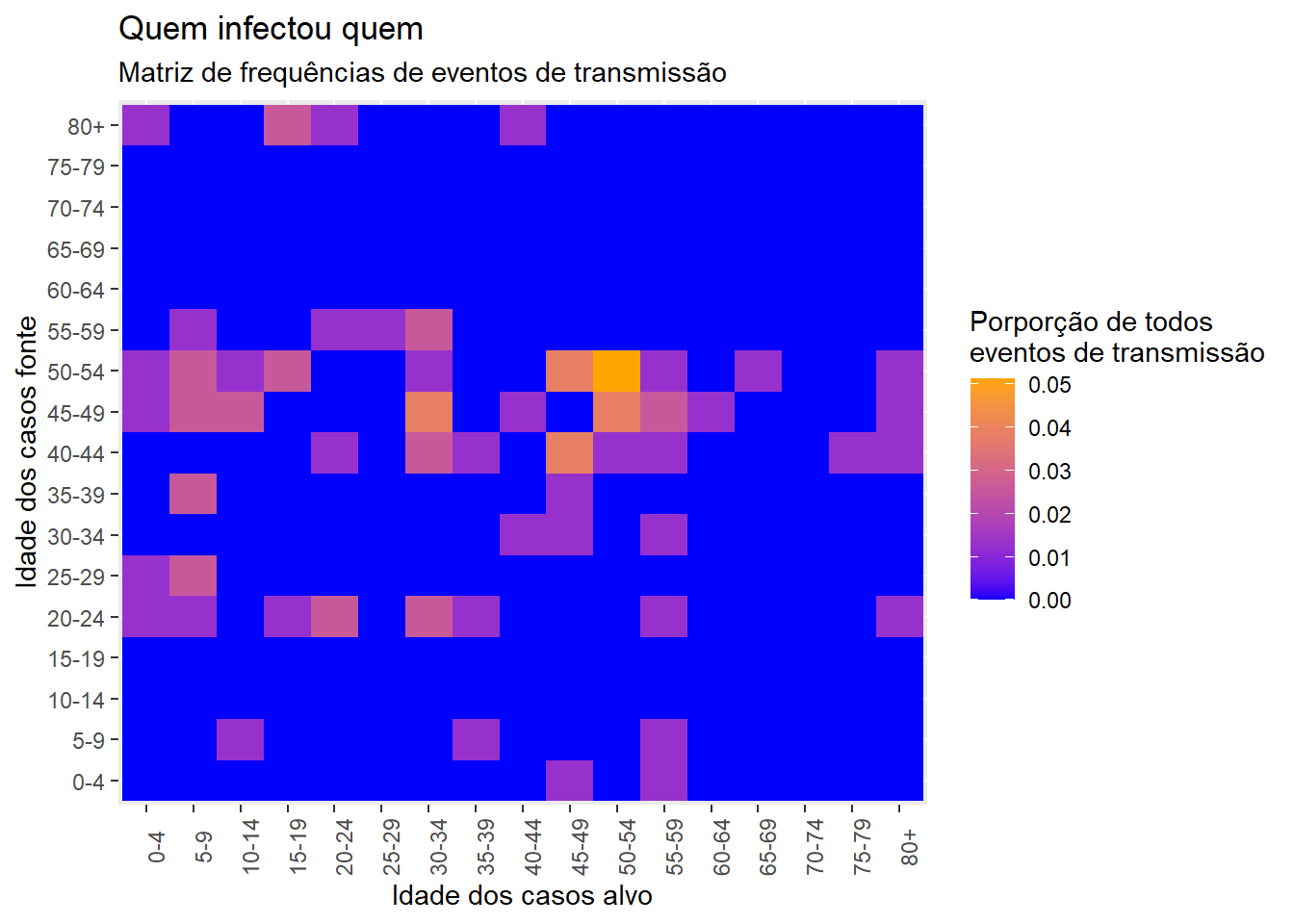
Como foi discutido na página Gráficos de calor, você pode criar uma matriz de “quem infectou quem” utilizando geom_tile().
Quando novos contatos são criados, o Go.Data armazena essa informação de relações no ponto final da API relationships; e podemos ver o primeiras 50 filas deste conjunto de dados abaixo. Isto significa que podemos criar um gráfico de calor com relativamente poucas etapas, dado que cada contato já está unido ao seu caso de origem.
Como feito anteriormente para a pirâmide etária comparando casos e contatos, podemos selecionar as poucas variáveis necessárias e criar colunas com faixas etárias categóricas, tanto para fontes (casos) quanto para alvos (contatos).
heatmap_ages <- relationships %>%
select(source_age, target_age) %>%
mutate( # a função transmute é como a função mutate(), mas remove todas as outras colunas
source_age_class = epikit::age_categories(source_age, breakers = seq(0, 80, 5)),
target_age_class = epikit::age_categories(target_age, breakers = seq(0, 80, 5))) Como descrito anteriormente, criamos uma tabulação cruzada;
cross_tab <- table(
source_cases = heatmap_ages$source_age_class,
target_cases = heatmap_ages$target_age_class)
cross_tab target_cases
source_cases 0-4 5-9 10-14 15-19 20-24 25-29 30-34 35-39 40-44 45-49 50-54
0-4 0 0 0 0 0 0 0 0 0 1 0
5-9 0 0 1 0 0 0 0 1 0 0 0
10-14 0 0 0 0 0 0 0 0 0 0 0
15-19 0 0 0 0 0 0 0 0 0 0 0
20-24 1 1 0 1 2 0 2 1 0 0 0
25-29 1 2 0 0 0 0 0 0 0 0 0
30-34 0 0 0 0 0 0 0 0 1 1 0
35-39 0 2 0 0 0 0 0 0 0 1 0
40-44 0 0 0 0 1 0 2 1 0 3 1
45-49 1 2 2 0 0 0 3 0 1 0 3
50-54 1 2 1 2 0 0 1 0 0 3 4
55-59 0 1 0 0 1 1 2 0 0 0 0
60-64 0 0 0 0 0 0 0 0 0 0 0
65-69 0 0 0 0 0 0 0 0 0 0 0
70-74 0 0 0 0 0 0 0 0 0 0 0
75-79 0 0 0 0 0 0 0 0 0 0 0
80+ 1 0 0 2 1 0 0 0 1 0 0
target_cases
source_cases 55-59 60-64 65-69 70-74 75-79 80+
0-4 1 0 0 0 0 0
5-9 1 0 0 0 0 0
10-14 0 0 0 0 0 0
15-19 0 0 0 0 0 0
20-24 1 0 0 0 0 1
25-29 0 0 0 0 0 0
30-34 1 0 0 0 0 0
35-39 0 0 0 0 0 0
40-44 1 0 0 0 1 1
45-49 2 1 0 0 0 1
50-54 1 0 1 0 0 1
55-59 0 0 0 0 0 0
60-64 0 0 0 0 0 0
65-69 0 0 0 0 0 0
70-74 0 0 0 0 0 0
75-79 0 0 0 0 0 0
80+ 0 0 0 0 0 0converter em formato longo com proporções;
long_prop <- data.frame(prop.table(cross_tab))e criar um gráfico de calor para a idade.
ggplot(data = long_prop)+ # usar dados longos, com proporção como Freq
geom_tile( # visualizar quadrantes
aes(
x = target_cases, # eixo X é a idade do Alvo
y = source_cases, # eixo Y é a idade da Fonte
fill = Freq))+ # cor dos quadrantes é de acordo com a coluna Freq da base de dados
scale_fill_gradient( # ajustar a cor de enchimento das quadrantes
low = "blue",
high = "orange")+
theme(axis.text.x = element_text(angle = 90))+
labs( # rótulos
x = "Idade dos casos alvo",
y = "Idade dos casos fonte",
title = "Quem infectou quem",
subtitle = "Matriz de frequências de eventos de transmissão",
fill = "Porporção de todos\neventos de transmissão" # título da legenda
)
25.6 Fontes
https://github.com/WorldHealthOrganization/godata/tree/master/analytics/r-reporting